
【第530回】AI画像生成とその課題。権利保護?技術革新?日本の文化を守るには?(2023/03/29)【#山田太郎のさんちゃんねる】文字起こし風要約

文字起こし元の動画
出演者:
山田さん:
山田太郎のさんちゃんねるです。今日は私自身も地方創生デジタル特別委員会で質疑をしましたが、AIについては光と影ということで問題点があります。AIを推進するために必要なこともあるということを含め、AIが置かれている状況や著作権法との関係についてお話します。
AI画像生成とその課題 権利保護?技術革新?日本の文化を守るには?
山田さん:
AIに関する問題で、事務所にもこのまま放置しておいたらまずいんじゃないかという相談もありましたが、賛否が非常に分かれていまして、まずAIについて寄せられた皆さんの意見をお伝えします。
AIについて寄せられた声

AI画像生成によりインターネット上のイラストを無断で学習されることは、私の絵も特定のキャラクターの個性を学ぶための情報として利用されている可能性があり、とても不愉快である。
学習元へ還元される仕組みができていない。

AI使用者が無断で画像を生成AIに組み込んで、数秒で絵を生成、投稿することにより、クリエイターは莫大なダメージを受ける。
現在のイラストAIは自身を含めた幾万人もの著作者に全く還元されない状態で商用利用されており、非常に憤りを感じる。
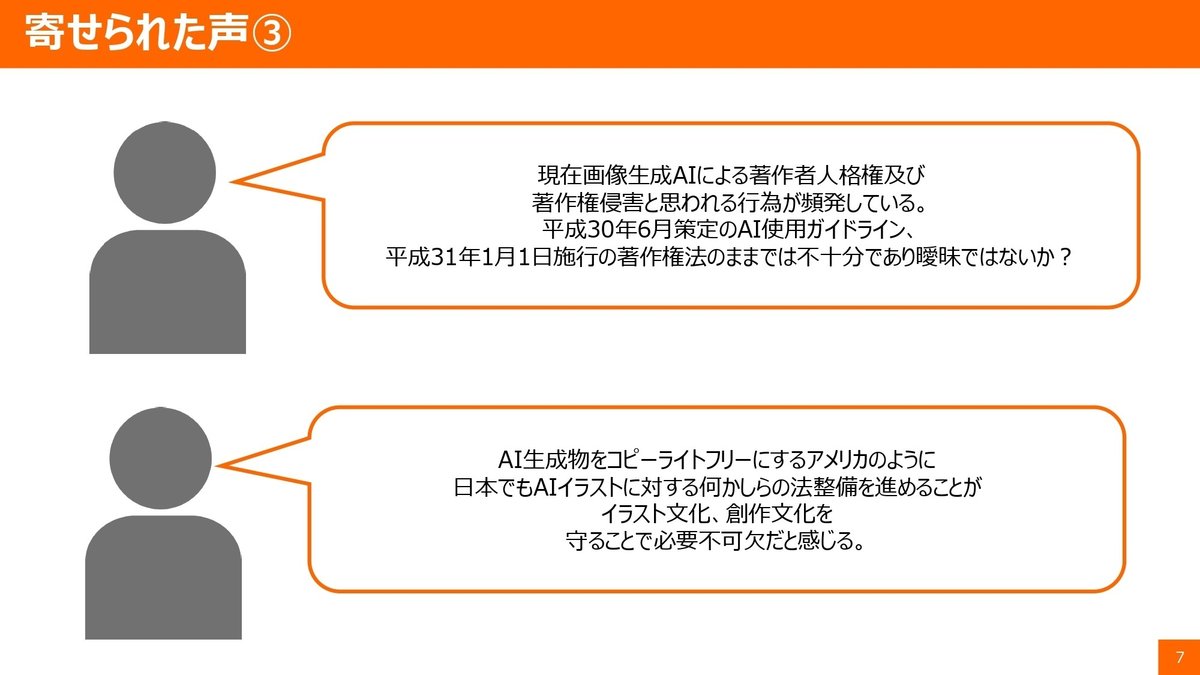
現在画像生成AIによる著作者人格権及び著作権侵害と思われる行為が頻発している。平成30年6月策定のAI使用ガイドライン、平成31年1月1日施工の著作権法のままでは不十分であり曖昧ではないか?
AI生成物をコピーライトフリーにするアメリカのように、日本でもAIイラストに対する何かしらの法整備を進めることが、イラスト文化、創作文化を守ることで必要不可欠だと感じる。

現在の画像生成AIについては、盗作ツールとして特化し、権利侵害の面が多く、発展的な技術としての使用は、他のツールで代用可能なものばかり。技術発展のため使われ方をしておらず、現状において市場の混乱を招いているだけであり、クリエイター環境に利益はなく、むしろ不利益をもたらしている。
どんな最新の絵柄を用意して作品を作ったとしても、データがロンダリングされてAIに吸収されてしまった時点で作品を作る価値が落ちてしまう。これでは絵を描くという行為自体の意義がなくなる、健全な競争環境とはいえないのではないか。

Winnyのように技術が悪者にされて、イノベーションが阻害されてはならない。ジェネレーティブAIで逮捕者が出たりして、日本のAI開発が世界に取り残されるのは嫌。
著作権侵害に利用されたWinnyと違って、画像生成AIの開発や利用はそもそも著作権侵害がないのではないか。自分のイラストが無断で使われるのは嫌だという気持ちはわかるが、いくら騒いでも適法な以上仕方がない。

現在のGPT4でもかなりの技術革新で、それが更に進む可能性が示されている時に、厳しい学習許可制などは技術的に取り残されかねない。
機械学習違法化や画像生成AIの違法化は、破滅的な結果しか生まないので反対。あくまで違法化すべきはi2iと呼ばれる無断でイラストをAIで描き直すシステムにとどめるべき。
山田さん:
というような意見もあって賛否がわかれています、いろいろな立場があると思いますが、めぐめぐさんはどう思いますか?
めぐめぐ:
私はイラストレーターとして、AIがどんどん発展していくことには賛成ですが、自分のイラストが取り込まれることが怖いという思いもあります。
山田さん:
ということで今ネットの中でもいろいろな声が寄せられていますが、まずは著作権について少し知っておく必要もあるだろうということで、小山さんにも解説してもらいながら、著作権について少し勉強しておきましょう。
著作権法とAI

小山さん:
まず根本的な問題になりますと、「著作権侵害」とは次の3つ、(1)他人の著作物を、(2)無権原で、(3)利用することです。
ポイントとしては、3つを満たさなければ「著作権侵害」にはなりません。つまり仮にAI生成物が著作物ではない場合は著作権侵害が発生しないということ、また他人の著作物であっても、保護される期間が満了しているものは著作権侵害にはなりません。

小山さん:
著作物とは、法律上非常に複雑な概念で「思想または感情を創作的に表現したものであって、文芸、学術、美術または音楽の範囲に属するもの」とされています。単なる事実やアイデアは著作物にならず、スポーツのルールなども著作物には該当しません。
山田さん:
今回はAIで生成されたものが著作物なのかどうか、それからAIに学習させる素材は著作物なのかどうか、まずこの2つを押さえておく必要がある。

小山さん:
著作物とは、法律の10条1項に詳細に列挙されており、言語、音楽、舞踊、美術、建築、映画、写真、プログラムなどが含まれます。またデータベースの著作物というのもありまして、AIと関連した問題で今後も出てきますので覚えておいてください。
山田さん:
だからありとあらゆるものが著作物として認定されるということ。

小山さん:
「法定の利用行為」とは著作権法21条以下定められた行為であり、それによって定められていない行為、例えば著作物を単に読む、見る、触る、聞くなどの行為は、著作権の保護の対象外となりません。

小山さん:
著作権が及ぶ行為は主に複製権に関連して、上演、演奏、上映、公衆送信、伝達、口述、展示、頒布、譲渡、貸与、翻案が含まれていまして、この中で複製と翻案が特に問題となります。
山田さん:
つまり著作権があるものを勝手にコピーしたらダメとか、翻案、新たな創作性を加えて既存の著作物を利用することは、無制限にできるわけではありません。

小山さん:
特に複製と翻案は既存の著作物を増やしたり、あとは形を変えて新しいもにすることで問題が起きることが多いです。両者とも、他人の著作物に依拠して、同一又は類似のものを作るだけで、新しい創作的表現の付加がなければ、多少違っていてもそれは複製に過ぎません。翻案は新たな創作的表現の付加がある場合のみ成立します。
山田さん:
ここが今回のAIにおいて著作権侵害があるかないかの重要なポイントです。著作権侵害の有無はこの類似性と依拠性が大事、類似性は似てるということなんだけど、依拠性というのは元のオリジナルと関連が強いかどうか、単に似てるだけじゃなくて、依拠性がないと著作権侵害にならないんです。
次にAIが生成したものに著作権があるかどうか、実は日本ではこの問題がまだ議論されていません。アメリカでは著作権局が基本的にはないと言ってるんだけれども、日本では著作性があるとされる可能性はあります。

小山さん:
次に無権原とは著作者の許諾がないこと、なおかつ権利制限規定にも該当しないことというのは、著作憲法30条以下にいろいろ規定されていまして、私的利用のための複製、引用、非営利・無料の場合の著作権利用などがあります。
山田さん:
日本では作品に何か創造性があれば、基本的に著作権が認められるんですが、引用や私的使用等は例外規定として認められる。引用にはガイドラインがあって、それに従えば著作者の許可を得ずに引用することができる。私的利用は自分またはその関係家族ぐらいまでと言われてるんですけど、いろいろ議論があって難しい。
いずれにしても、私的利用は良くてもインターネットを使ってしまうとそれは公衆送信に当たるのでダメということ。

小山さん:
特に問題になるのは引用に関する規定で、クリエイターや表現者の中には引用禁止を主張する方もいますが、これは契約でもしていない限り著作権法で引用は認められています。
ただ引用には制限もあります。公表された著作物であることが条件の1つであり、無断で公表することは認められていません。また引用の条件には、明瞭区別性と主従関係性、引用部分と被引用部分が明瞭に区別できること、引用部が主、被引部が従であることなどがあります。
あと「公正な慣行に合致する」という要件や「正当な範囲内」などの要件もあり、画像生成AIの学習段階も含めて、それが嫌だという気持ちも理解できますが、著作権の権利制限規定に当たればそれは合法というのが今の法律ですので、まずこれらのポイントを理解していただきたいと思います。
山田さん:
何でもかんでも著作権で守られるわけじゃなくて、権利が制限されることもあるんだということを、問題のAIとの関係に移る前に押さえておいてください。

小山さん:
次は「著作物に表現された思想又は感情の享受を目的としない利用」これはかなり広範に、どんな形態でも利用できるという、結構強い権利制限規定です、権利制限というのは使ってもかまわないということ。
ただし「当該著作物の種類及び用途並びに当該利用の態様に照らし、著作権者の利益を不当に害することとなる場合は、この限りでない。」ということで、上画像の一~三にありますが、非常に何を言ってるかわからない。
山田さん:
この3つは人工知能のシステムに情報を学習させるために作られた規定でして、それまでは著作性があるものを学習させることに著作権侵害の有無がわからないから、日本のAIとか人工知能が発展できるように、とりあえず学習させることを保証したのがこの30条の4だと思ってください。
ただし問題だったのは、学習段階のインプットばかりが議論されて、生成段階のアウトプットについては、一部しか書いてないんです。
小山さん:
そしてこれだけではわかりにくいので、一応基本的な考え方というのを文化庁が示してくれています。

小山さん:
結局何言ってんだかさっぱりわからないんですけど、要するに、著作物等の視聴、見たり聴いたりすることを通じて、知的・精神的欲求を満たすための行為であるか否かで判断しますよと、AIに学習させる場合は、別に見るわけでも楽しむわけでもないから、これは享受には当たらないということになります。
山田さん:
いやいや生成AIは、画像や文章などの形で提示されることが多いから、それを見たり読んだりして精神的に楽しみや満足感を享受しているじゃないかというかもしれませんが、AIが生成したものを楽しむ人と、AIを開発して学習させて育てる人は別人だから、単にAIを育てるために学習させることが目的であって、楽しむことは目的としていないというのが問題になっちゃう。
一方で生成AIを使う人たちは、そのAIが生成したものを享受していることになるから、30条の4が成立しない可能性があるということ。
小山さん:
学習された当該データがそのまま出てくるなら享受になりますが、生成AIはそのまま元のデータが出てくるわけではない。
山田さん:
ただAIを使ってると偽って、例えば特定の誰かの絵を5枚だけ学習させて、それを加工して出力した場合は享受しているし、依拠性も存在して、入力した人と出力した人が同一人物と見なされるから、その場合は違反となる可能性がありますが、現実的にはなかなか微妙なんですよ。
これについては政府の答弁も取ったし、いろんなところで議論もしているんですが、生成系AIが出てきてこんな大きな問題になるとは想定してなかったんです、その時は。
どちらかというと、ニューラルネットワークのようにいろんなデータを組み合わせて、何かデータ収集・解析ができるようにということを目指して、それを急いでいた節があります。

小山さん:
次に「著作物に表現された思想又は感情の「享受」を目的としない行為とは」ということで、その1番目に「人工知能の開発に関し、人工知能が学習するためのデータの収集行為、人工知能の開発を行う第三者への学習用データの提供行為」これは著作権課が明確に認めた行為です。
これはインターネット上に上がっている侵害コンテンツであったとしても、著作権侵害にはならないと明確にここで示していると言われています。

山田さん:
「著作権者の利益を不当に害することとなる場合とは」ということで、ごちゃごちゃ書いてありますが、これに当てはまるんじゃないかと、「著作権者の著作物の利用市場と衝突するか」「あるいは将来における著作物の潜在的市場を阻害するか」という観点から判断されるとはどういうことか。
例えばある絵がありまして、それにすごく似ている絵が出力された、それはまさに利用市場が衝突するじゃないかと。これについては質疑で確認していて、実は今言ったような懸念点を問題とした「ただし書き」ではない。
これは例えばデータセット、何かAIに学習させたときに作られるモデルデータ、そのモデルデータが勝手に他の人にコピーされて使われないようにするための条文であるという見解なんです。
小山さん:
一般的な例として、AIを開発する場合、言語モデルのデータを集めてそれを有料で販売したとします。その有料のデータを勝手に使うことは許可されないというようなことしか言っていません。
あとは司法の判断におまかせですということなんですが、今日の山田さんの質疑でもありましたが、今現在AI開発は非常に重要な局面にあります。司法リスク、司法がどう判断するかわからない中で、日本もいろいろAI戦略を進めていますが、裁判所が違法と判断するとその政策がストップするリスクがあります。
山田さん:
だから我々立法府が、ちゃんと作っていくべきだと今日くぎを刺しておきました。政府は責任を回避しているようで、司法だって困るよね。それで司法がゼロから考えて、適当な判決を出されても困りますので。
今後はデジタル時代に合わせた従来の権利制限型の著作権は合わない場合もあるから、フェアユースを少し組み合わせたような新しい著作権制度が必要なんじゃないかと2016年ぐらいから提唱していて、今回の人工知能の問題でも非常に重要ですので、党内の知財調査会でも議論が始まる見通しです。

小山さん:
「AI開発のための学習データの収集及び提供の適法性」ということで、さっきも言った通り30条の4で適法なんですが、これに関してはいろいろ賛否両論あると思いますので、ではどうするのか、これから何をしたらいいのかということで、問題をざっくりと整理します。
これからやるべきこと

山田さん:
まずAIとひとくくりになってるけど、何を指しているか整理する必要があって、AIにはそのAIを動かすソフトウエアがあって、そのソフトウェアに学習させるデータがあって、そしてそのデータを使ってAIが生成したものがある、さらにその出力されたものをどう使用するかによって問題が異なってくるから、この4つの要素を分けて考えないといけない。
かつての「Winny」のようなことにしてはいけない。「Winny」ではピア・ツー・ピア(P2P)と呼ばれる通信方式が使われていて、その中には著作権に違反するデータや児童ポルノなどが流れているということが問題視されて、Winnyを潰すべきだという意見が出ました。
だけど「Winny」自体が悪いんじゃなくて、問題なのはそれをどう使うか、どんなデータが入力されて、出力されたものをどう使うかということなんであって、例えば包丁は料理をするために使います、しかしそれで人を殺すことも出来てしまう、でもその包丁や包丁を作った人に責任はないよね。
小山さん:
「AIの利用と著作権法」に関しては、先ほど言った複製と翻案が特にAIの利用において、依拠性と類似性があるのかどうか。類似性がなければそもそも問題とならないので、類似性があることを前提として、依拠性の有無が最大のポイントだと思います。
例えばAdobeのIllustratorを使って他人の絵を編集した場合、それは編集した人が責任を負います。一方でAIは同じ指示を出しても、異なる生成物が出てくることが多いと言われています。

小山さん:
山田事務所でChatGPTにi2i(image to image)は何ですかと、同じ質問を連続でやってみました。そしたらindividual to individualの略だとか、eye to eyeの誤った表記だとか、この場合、依拠性が誰にどうあるのかわからない。
同じ指示を出して同じものが出てくるのであれば、何かに依拠していると考えられるのですが、同じ指示をしても全く違う結果が出てくるのであれば、AIが何かしらに依拠してるとは言いにくいという意見があります。
こういったAIに含まれるのは、具体的な画像や文章などのコンテンツデータではなくパラメータになりますので、そのパラメータの組み合わせで生成されたものは、元のコンテンツとの依拠性はないという意見もありながら、どう考えるかは難しいです。

小山さん:
ただAIと言っても、imeage to imageのもの、画像を入力して類似した画像を生成させるAIは、明らかに依拠性あるように思います。他人の著作物と認識した上で、元画像と類似した生成物を出力する場合、これはいろんな著作権の関係者も指摘していますが、著作権侵害が成立する可能性は極めて高いと私も思います。
image to imageと異なり、text to imageの場合は、依拠性の有無は理論的には難しいと思われます。場合によっては依拠性ありと決めざるを得ない状況が出てくる可能性もありますし、元々のコンテンツが不明だからできないという判断になるかもしれませんが、これを司法判断に全部おまかせするのは、AI戦略として非常に問題があると思いますので、どこかしらで決断を出さなくてはならない問題だと思います。

小山さん:
ただAIの生成物に関しては、2016年時点でいろいろな検討されていたことが資料からも読み取れます。この当時は第一進化がAIによる特徴抽出と分析への活用で、現在は第二進化のAIによる創作の実現までいってます。


小山さん:
2016年時点でAIによる創作の取り組み事例として、スペインの大学で作曲をする人工知能ラムスとか、テイラーブランド社の人工知能でロゴを自動的にデザインするものとか、いろいろな生成系AIがありました。

小山さん:
人による創作物とAI創作物の境界についても考察がされていて、古くは昭和48年、そして平成5年に文化庁著作権審議会での議論を踏まえると、下図のようになります。

小山さん:
人による創作は著作権が発生しますが、AIによる創作については、単に指示を与えただけ、人間から〇〇を作ってという働きかけがあっただけの場合は、一見して創作物だという形でも著作権は発生しない。
山田さん:
その場合権利は発生しないのではないかと、これは確定ではありませんが、重要なポイントは一番下の、AIを道具として使って、創作意図だとか、創作的寄与がある場合、AIから出力されたものでも人間の意志や意図が入っている場合は権利が発生する。
だからAIでも簡単な指示で生成したものには権利は発生しないかもしれませんが、そのAIに細かく指示を出して生成したものに関しては、それは創作性があるのではないかという考え方もできますが、まだ確定ではありません。
小山さん:
ただその創作意図と創作的寄与の特に寄与のところは、例えばプロンプト(AIに出す指示)がどのくらいの量だったら認められるのかとか、解釈が難しいです。

小山さん:
2016年当時にもAIに関して知財制度上起こりうる懸念というのが上図のとおり3つありましたが、この懸念が今実際に起こっています。

小山さん:
これらの懸念に対して、AI創作物の知財制度上の取り扱いについて、改めて検討したらどうかと言っていますが、実際には十分な検討は行われていませんでした。

小山さん:
ただそのAI生成物に著作権と同等の保護を与えるか、一切保護しないのか、あるいは別の保護を与えるのか、いろいろ考えられますが、いずれにしてもまだ課題が多く残っており、まとまった結論は出ていません。

小山さん:
新しい知財制度の検討ということで、「権利の主体と保護法益」「権利の内容」「権利の発生要件」をそれぞれどうするのか。
山田さん:
「権利の主体と保護法益」というのは、もし権利を認めるとするのであれば、誰にその権利がつくのか。
「権利の内容」は、その人だけ独占的に認めるのかとか、何年ぐらいの期間を認めるのか、その権利の内容の話です。
「権利の発生要件」の客観的要件や手続的要件というのは、明らかに第三者に対してもこれは権利主張されているということがわかるものと、方式主義とか無方式主義というのは、著作権は自然権とも言われるんだけど、作った段階ですでに存在します、いちいち登録とか届出をする必要がない。
こういうふうに、いろんなパターンをしっかり整理していかなければならないということです。

小山さん:
あとは「自然人の創作保護との関係」というところも非常に大きな問題となっています。
山田さん:
ということで何が論点になっているかわかりましたでしょうか。とにかく人工知能はソフトウェアが中心にあって、入力との話と出力の話は分けて考えないといけない。
もう1つ、確かに人工知能を発展させるためには、いちいち学習データの著作権について考慮してたら出来ない。ただし出力して出てきたものは著作権があるのかどうか、それに人がどのぐらい関与したかにもよって、それにどんな権利を与えるのかは非常に難しいということ。
これを前提として今日の私の国会での質疑について、どんな質問をして政府はどういう回答をしたのか。

山田さん:
国のAI政策について、AI生成物の著作権について賛否いろいろ意見がありますが、政府はそれを把握しているのかということですが、それに関してはわかっている、いろんなクリエイターから不安の声がある、実際の権利濫用があるのではないかということについては、一応認識しているということでした。
また政府は2019年以降AI戦略を作ってきました、2018年に30条の4を作ったけど、それ以降AIが急速に発展してきて、著作権法上の問題に関して何か議論しましたかと聞いたら、これに関しては政府はしていませんと。
AIを発展させることに関してデータセットをどうするかということは、一定の議論をしてきたんだけど、著作権だとかいろんな権利を侵害するかもしれないという整理に関しては議論をしてこなかったということ。
次にこの30条の4を巡っていろいろ揉めているので、これについてもなんのために30条の4を作ったのかと、この時私は議員ではありませんでしたから。
これはさっきの解説にあった通りなんですけれども、AIを初めとして、そのシステムとかいろんなものを作るときに、著作権を意識すると技術の発展が難しいから、基本的には思想等を享受しない、依拠しない場合は、データを学習するインプットについては認めたという説明でした。
ただしアウトプットに関しては議論してないと、言い切ってはいませんでしたが、強く検討したものではないと。
次は逆に、30条の4においても適法化されないAIとはどういうものを想定したんですかと、これもさっき説明しましたが、AIに学習させたデータセットを、勝手にコピーして使うのはダメということでした。
1つずつのアウトプットに対してではなくて、データセットそのものがそのままコピーされるということに関して、それは認めないということに過ぎないと。
それから一応著作権というのは「登録」をしなくても発生するんですが、著作権法の75条以下で「登録」するということもできるから、AIで出力したものも登録できるのかどうか。
もう1つ国会図書館法24条以下に納本制度というのがあるけど、AIで作られた書物や出版物はその制度の対象になるかどうかを質問しました。
まず登録に関しては、基本的には著作生ということを検討しながら登録するかどうかはそれぞれ個別に判断することになると。そもそもAIで作られたものに著作性があるかどうかはまだ決まっていないので。
僕自身は単にAIがそのまま出力したものに著作権を認めるべきではないと思っています。もちろんさっきも言ったとおり少しでも手を加えたらどうなのという問題とか、複製なのか翻案なのかも含めて議論しなきゃいけないんだけど、いずれしても75条で登録出来ちゃったらまずいだろうと。
そして国会図書館法の方は出版物であれば対象ですと、著作物性が認められるかどうかは関係がない。だから国会図書館がAIで作った出版物だらけになってしまう可能性もあるから、法律的に対応しておかないととまずいんじゃないのと、現実にAIが作った出版物がでてきてるから。
今このAIに対する著作権等を含めた問題を議論していないと、いろんな脆弱性がいっぱい出てきている。とはいえ今日この段階で結論は出ないけれども、ルールメイキングも含めて、総合的なAI政策を議論する政府内の専門部署を作るべきだと主張しました。
それについてはその必要性は認めると、ただしすぐにやるかどうかはわからないという話だったんで、これは私も党の方で責任を持ってやりたいと思います。
(実際の質疑の動画はこちら↓です、20分弱ありますが、よろしければぜひご覧ください、テキスト字幕もあります。)
山田さん:
小山さんここまでどうですか。
小山さん:
やはり著作権法を考える際には、文化の発展にどう寄与するのかというのが最大のポイントになると思っていまして、いろんな意見が寄せられた中には、やはり自分の画像を勝手に使われたら創作意欲がなくなるんだから文化の発展にとってはマイナスだという意見があります。
一方で自分は絵心がないけど、生成AIで出来るから創作意欲がわくという意見もあり、AIの生成物が著作物かどうかは難しい判断だと思いますが、そういう人からすれば、AIが文化の発展に寄与しているという意見もありますので、総合的に考えていく必要がある思います。
虹杜コメント:
ということで今回の文字起こしは以上です。今回も結構な部分、要約・カットしておりますので、しっかり内容を確認したい方は是非動画の方をご視聴下さい。
こちらの文字起こし風要約は自由に切り抜いてTwitter等で利用して頂いてかまいません。ここまで読んで頂きありがとうございました、もしよろしければスキを押していただけると幸い(お礼文はランダム表示)です。
山田太郎さんを応援したい方は、山田太郎公式ホームページの『山田太郎をSNSで応援する』や『山田太郎をもっと応援する』からどうぞよろしくお願いします。