
WSL2でjapanese-stable-diffusion-xlを試してみる

日本特化の商用利用可能 text-to-image モデル「Japanese Stable Diffusion XL」を試してみます。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、Windows 11+WSL2です。
準備
python関連
まずは、python関連から。
python3 -m venv japanese-stable-diffusion-xl
cd $_
source bin/activateとしてからのpip install
pip install torch transformers accelerate
pip install SentencePieceで、pip listです。
$ pip list
Package Version
------------------------ ----------
accelerate 0.24.1
certifi 2023.7.22
charset-normalizer 3.3.2
contourpy 1.2.0
cycler 0.12.1
diffusers 0.23.1
filelock 3.13.1
fonttools 4.44.3
fsspec 2023.10.0
huggingface-hub 0.19.4
idna 3.4
importlib-metadata 6.8.0
Jinja2 3.1.2
kiwisolver 1.4.5
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
packaging 23.2
Pillow 10.1.0
pip 22.0.2
psutil 5.9.6
pyparsing 3.1.1
python-dateutil 2.8.2
PyYAML 6.0.1
regex 2023.10.3
requests 2.31.0
safetensors 0.4.0
sentencepiece 0.1.99
setuptools 59.6.0
six 1.16.0
sympy 1.12
tokenizers 0.15.0
torch 2.1.1
tqdm 4.66.1
transformers 4.35.2
triton 2.1.0
typing_extensions 4.8.0
urllib3 2.1.0
zipp 3.17.0WSL2での画像表示
imageオブジェクトをshow()として、顎が落ちないようにするため、以下をインストールします。
$ sudo apt install imagemagickあと、環境変数DISPLAYも設定しておきます。
$ export DISPLAY=:0モデルのダウンロード
Hugging faceから試すぞー、なのですが、
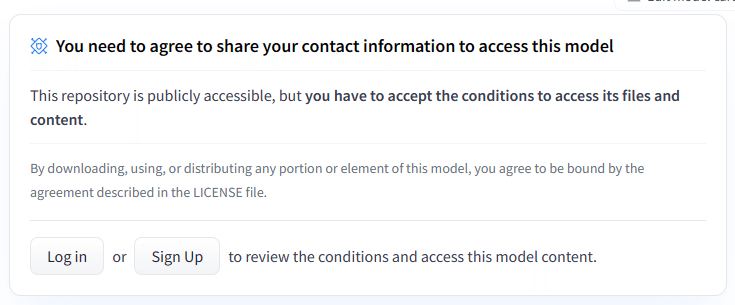
とのことで、試すためには提供しましょう。
そして、Access Tokensも必要になりますので、Hugging faceの Profile > Settings > Access Tokens からトークンを払い出した上で
$ HUGGING_FACE_HUB_TOKEN="hf_XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
$ export HUGGING_FACE_HUB_TOKENとしてpythonのコードから参照できるように設定しておきます。
試してみる
これで準備は完了です。
$ pythonを起動して、流し込みます。流し込む内容は README.mdのサンプルをベースにしたものです。
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"stabilityai/japanese-stable-diffusion-xl", trust_remote_code=True
)
pipeline.to("cuda")そして、、、
prompt = "松阪牛、時速80kmで疾走"
image = pipeline(prompt=prompt).images[0]
image.show()
出力された画像は、こちら。

いや、馬。
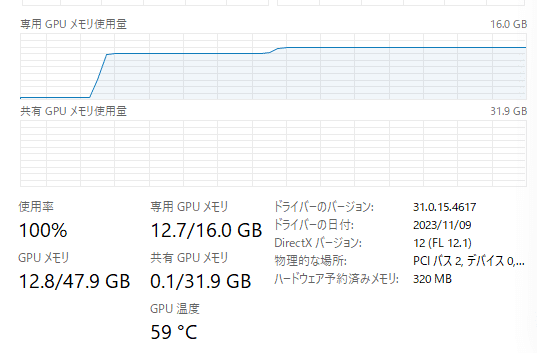
メモリ使用量
最初の傾きは、DiffusionPipeline.from_pretrainedメソッドの呼び出し。2つ目の傾きは、image = pipeline(prompt=prompt).images[0] の実行時です。
おまけ
「柴犬、カラフルアート」として出力されたイメージ。かわいい。
