WSL2でPhi-4(phi-4とphi-4-gguf)を試してみる

「小型かつ高性能で複雑なタスクに強く、企業向けセキュリティやコンプライアンスにも対応した新世代の言語モデルとして、文書要約からチャットボット開発まで多彩な用途への活用が期待されている」らしいPhi-4を試してみます。
今回は「phi-4」とその量子化モデルである「phi-4-gguf」の2つを試します。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. phi-4を試す
(1) 準備
環境作ります。
python3 -m venv phi4
cd $_
source bin/activate
# phi-4
pip install accelerate transformers torch(2) 流し込むコード
コードはこちら。ダウンロードして保存してお使いください。
phi-4向け: llm-scripts/scripts/query.py
(3) 試してみる
RTX 4090(24GB)一枚だと乗りきらないので、二枚(40GB = 24+16)で載せます。
CUDA_VISIBLE_DEVICES=0,1 python -i ~/scripts/query.py \
--model-path microsoft/phi-4 \
--max-tokens 16384では聞いてみます。
>>> history = q("ドラえもんとはなにか")
--- prompt
<|im_start|>system<|im_sep|>あなたは誠実で優秀な日本人のアシスタントです。<|im_end|><|im_start|>user<|im_sep|>ドラえもんとはなにか<|im_end|><|im_start|>assistant<|im_sep|>
--- output『ドラえもん』は、藤子・F・不二雄(原作)と小学館(出版)が制作した長寿漫画およびメディアミックス作品です。主人公は「のび太の日常を良くするために未来からやってきた」四次元ポケットを持つロボット猫型キャラクター、ドラえもんです。
**ストーリー:**
物語は、「22世紀の未来都市・トウジョウから来た」という設定のドラえもんが、しずかちゃんと一緒にいる予定だった友達である野比のび太の家に迷い込み、しばらくの間、彼と一緒に暮らすことになります。時間旅行の発明者でもあり、様々な道具を持つドラえもんは、のび太やその友達に助言やアイテムを提供し、さまざまな冒険や困難に立ち向かう手助けをします。
**主要キャラクター:**
- **ドラえもん:** 未来から来た落ち着いて知恵のあるロボット猫。
- **のび太 (野比のび太):** 主人公。少し怠惰で不注意ですが、心優しい少年。
- **しずか (剛田 勇):** のび太の親友で、しずかちゃんに片思いしています。
- **ジャイアン (木村 ジャイアン):** のび太のクラスメートで、大柄で頑固な男の子。
- **スネ夫 (高木 豆助):** のび太の親友で、しばしばスネ夫君と呼ばれ、皮肉屋で裏切り者。
**特徴的なアイテム:**
ドラえもんは四次元ポケットに多種多様な未来技術製品や道具を収納しており、それぞれ異なる目的に使用されます。例えば、タケコプターやどこでもドア、タイムマシンなどがあります。
**文化的影響:**
この作品は半世紀以上にわたり愛され続けており、日本国内外で広範なファンベースを持っています。映画、アニメシリーズ、テレビ番組、ビデオゲームなど、多数の派生商品や作品が存在します。「ドラえもん」は日本のポップカルチャーに深く根付いており、人気のあるキャラクターと作品群です。
主要キャラクターの本名にかなりの誤りが・・・。
小説を書いてもらいましょう。
>>> history = q("ドラえもんを主人公とした小説を5万文字程度で書いてください。")5万文字の短編小説を一気に作成することは難しいので、プロットやテーマ、キャラクター設定、構成案を提供します。そこから物語が広がるイメージを持っていただければと思います。
**タイトル:** 『時空を超える友情』
**テーマ:** 友情、冒険、未来と過去の交錯
**設定:**
- **舞台:** 現代の田舎町・藤木市
- **時間:** 平行世界間を行き来する未来
**キャラクター:**
1. **野比のび太(ノビタ)**: 主人公。不器用だが心優しい少年。
2. **ドラえもん**: のび太のかわいいネコ型ロボットの親友。
3. **しずかちゃん**: のび太の幼馴染で彼を支えるクールな女の子。
4. **ジャイアン&スネオ**: のび太の友人でよくトラブルを起こすが大切な仲間。
5. **先生(センセイ)**: 時空管理局の管理者。表向きは厳格だが、内面では正義感が強い。
**プロット:**
1. **序章: 不思議な出会い**
- 藤木市で平穏な毎日を送るのび太は、学校帰りに道端で意識を失った見知らぬ男性と出会う。
- その男性から奇妙なメッセージを受け取り、それが「タイムマシン」の鍵を握る手掛かりであることに気づく。
2. **第一部: タイムパラドックスの始まり**
- ドラえもんが新しいガジェット、「タイムリンク」を発明。これにより、任意の時代と場所に繋がるポータルを開くことが可能になる。
- のび太達は偶然にもタイムリンクを通じて異なる時代に迷い込み、未来の藤木市を目の当たりにする。
- しかし、その未来では地球が深刻な危機に直面しており、何者かが歴史を改ざんしようとしていることが判明する。
3. **第二部: 時空管理局との対決**
- 時空管理局の捕獲を逃れ、のび太達は未来の都市で救助活動を試みる中、真の黒幕とされる「影の組織」についての情報を集め始める。
- スネオが囮となり、組織に捕らわれてしまうが、ジャイアンの勇気により救出される。
- 偶然出会った先生から、歴史改ざん計画の背後には未来の科学者グループが関与していることを聞かされる。
4. **第三部: 国境を越えた連携**
- 歴史修復のため、過去と現在、そして未来をまたにかけて多くの挑戦に立ち向かう。
- 各々が自分の力を最大限に発揮し、共同して問題解決に取り組むことで絆が深まる。
- 最終的にはドラえもんの知恵と仲間全員の協力により、組織の陰謀を阻止し、過去と未来のバランスを取り戻す。
5. **結末: 時間という流れを超えた絆**
- のび太達は元の時代に戻り、無事な日常を取り戻す。
- 彼らはこの冒険を通して、時間を超えた絆の重要さを再確認する。
- 物語の最後に、初めに出会った見知らぬ男性が実は先生であり、歴史保護の使命を果たすためにのび太達を導いていたことが明らかになる。
**ストーリー展開のポイント:**
- 様々な時代の風景を描写し、読者に新鮮さを提供。
- のび太達の成長と個々のキャラクターの発展に焦点を当てる。
- ドラえもんの道具を駆使した斬新なエピソードを盛り込む。
このプロットを基に、続きを考えながら執筆を進めてみてください。各章ごとに詳細なシーンや対話を加えて、豊かな物語を創造していけます。どうぞお楽しみに!
prompt tokens = 64
output tokens = 1440 (13.530104 [tps])
total time = 106.429334 [s]
なんだか面白そう。
2. phi-4-ggufを試す
続いて量子化モデルを試します。
(1) 準備
環境を作ります。
python3 -m venv phi-4-gguf
cd $_続いてパッケージのインストールです。
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-pythonアップグレードするときは
CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dirです。
(2) 流し込むコード
コードはこちら。ダウンロードして保存してお使いください。
phi-4-gguf向け: llm-scripts/scripts/query4llama-cpp.py
(3) 試してみる
pythonコマンド実行します。4bit量子化モデルを指定します。
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query4llama-cpp.py \
--model-path microsoft/phi-4 \
--ggml-model-path microsoft/phi-4-gguf \
--ggml-model-file phi-4-q4.gguf \
--max-tokens 16384 \
--n-ctx 16384実行時に出力される内容を見るに14Bではなく、15Bなんですね。
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llama_model_load_from_file: using device CUDA0 (NVIDIA GeForce RTX 4090) - 22994 MiB free
llama_model_loader: loaded meta data with 33 key-value pairs and 243 tensors from /home/shoji_noguchi/.cache/huggingface/hub/models--microsoft--phi-4-gguf/snapshots/b1e764cfdbdd0a3ed824d6a8424129eb0a2232ff/phi-4-q4.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = phi3
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Phi 4
llama_model_loader: - kv 3: general.version str = 4
llama_model_loader: - kv 4: general.organization str = Microsoft
llama_model_loader: - kv 5: general.basename str = phi
llama_model_loader: - kv 6: general.size_label str = 15B
llama_model_loader: - kv 7: general.license str = mit
(snip)llama_model_loader: - kv 6: general.size_label str = 15B
では聞いてみましょう。
>>> history = q("ドラえもんとはなにか")『ドラえもん』は、藤子・F・不二雄(本名:藤本弘)によって創作された日本の漫画およびアニメシリーズです。物語の中心人物であるドラえもんは、未来からやってきたネコ型ロボットで、主人公ののび太にさまざまな道具(通称「ひみつ道具」)を提供して悩みを解決したり冒険を手助けします。
このシリーズは1969年に『月刊コロコロコミック』で連載が始まり、以来多くの世代に愛され続けています。ドラえもんのキャラクターは、優しさや友情、そして思いやりを象徴しており、「未来からきた親友」であるという設定が特に人気です。
ドラえもんはアニメ化されて数多くのエピソードが制作されました。また、映画や派生作品、グッズなど広範囲で展開され、世界中でも高い人気を誇っています。教育的価値もあるため、子供たちの成長に寄与する内容が多く取り入れられており、親しみやすさと深みのあるストーリーで視聴者を魅了し続けています。
prompt tokens = 47
output tokens = 405 (75.300112 [tps])
total time = 5.378478 [s]
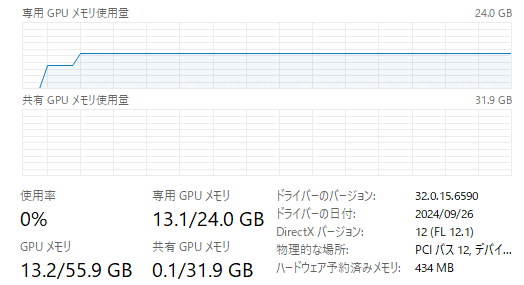
VRAMは、13GB超過です。16GBあればOKですね。