
WSL2でAniDocを試してみる

「アニメーション線画の自動着色を目的としたディープラーニングベースのシステム」「この技術は、アニメーション制作における着色作業を効率化し、特に手間のかかるフレーム単位の処理を軽減することを目指している」らしいAniDocを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
環境構築
venv環境構築。
python3 -m venv anidoc
cd $_
source bin/activateリポジトリをクローン。
git clone https://github.com/yihao-meng/AniDoc
cd AniDocパッケージのインストールです。shell scriptが用意されているので、有り難くそれを使用します。が、いくつか不足しているので合わせてインストールしておきます。
bash ./install.sh
# 不足パッケージ
pip install moviepy==1.0.3 basicsrモデルのダウンロード
# SVD
huggingface-cli download --repo-type model --local-dir pretrained_weights/stable-video-diffusion-img2vid-xt stabilityai/stable-video-diffusion-img2vid
# AniDoc Unet and ControlNet
huggingface-cli download --repo-type model --local-dir pretrained_weights/anidoc Yhmeng1106/anidoc
# co_tracker
wget -P ./pretrained_weights https://huggingface.co/facebook/cotracker/resolve/main/cotracker2.pthanidocはanidoc/anidocをanidocにしなければならないので、以下のようにディレクトリを移動させておきます(お茶を濁します)。
cd pretrained_weights
mv anidoc anidoc.orig
mv anidoc.orig/anidoc .
cd ..2. プログラムを確認する
(1) anidoc_inference.sh と anidoc_inference.py
anidoc_inference.shとanidoc_inference.pyは、アニメーションの線画シーケンスを特定のキャラクターデザインに基づいて着色するためのスクリプトです。
anidoc_inference.sh
このシェルスクリプトは、Pythonスクリプトであるanidoc_inference.pyを実行するためのコマンドを含んでいます。主な引数は以下です。
--control_image:線画シーケンス(カラー動画)を指定し、各フレームのスケッチを抽出して制御信号として使用する。
--ref_image:キャラクターデザインの参照画像を指定。
これらの引数を適切に設定することで、anidoc_inference.pyを実行し、指定した線画シーケンスが参照キャラクターデザインに基づいて着色されます。
anidoc_inference.py
このPythonスクリプトは、指定された線画シーケンスとキャラクターデザイン参照画像を入力として受け取り、機械学習モデルを使用して線画シーケンスを着色します。
処理の流れは以下です。
入力の読み込み:指定された線画シーケンスと参照画像を読み込む。
前処理:線画シーケンスから各フレームのスケッチを抽出し、モデルの入力形式に変換。
モデル推論:事前学習済みのモデルを使用して、線画シーケンスを指定のキャラクターデザインに基づいて着色。
後処理と保存:生成された着色済みのフレームを動画として保存。
これらのスクリプトを使用することで、独自の線画シーケンスを特定のキャラクターデザインに基づいて自動的に着色することができるようです。たぶん。
(2) process_video_to_14frames.py
指定されたフォルダ内の動画ファイル(主にMP4形式)を読み込み、それぞれから14フレームを均等に抽出して新しい動画ファイルとして保存し、さらに各フレームを個別の画像ファイル(PNG形式)として保存するスクリプトです。
入力と出力のフォルダ設定
input_folderに処理対象の動画ファイルが含まれるフォルダパスを指定。
output_folderに処理結果を保存するフォルダのパスを指定。
動画ファイルの処理
input_folder内の全ファイルを取得し、.mp4ファイルを対象。
各動画ファイルに対して、cv2.VideoCaptureを使用して動画を読み込み、以下の情報を取得。
総フレーム数(cv2.CAP_PROP_FRAME_COUNT)
フレームレート(cv2.CAP_PROP_FPS)
フレームの幅(cv2.CAP_PROP_FRAME_WIDTH)
フレームの高さ(cv2.CAP_PROP_FRAME_HEIGHT)
フレームの抽出
動画の開始から終了までの間に均等に14個のフレームインデックスを計算。
動画をフレームごとに読み込み、計算したインデックスに該当するフレームをsampled_framesリストに追加。
新しい動画ファイルの作成
抽出した14フレームを使用して、新しい動画ファイルを作成し、output_folder内に保存。
cv2.VideoWriterを使用して、元の動画と同じフレームレート、幅、高さで新しい動画を作成。
フレームの画像ファイルとしての保存
各動画ファイルに対応するフォルダをoutput_folder内に作成し、抽出した各フレームをPNG形式で保存。
cv2.imwriteを使用して、各フレームをframe_XXX.pngという形式のファイル名で保存。
画像ファイルの処理
input_folder内の.pngのファイルは、そのままoutput_folderにコピー。
動画から特定のフレーム数を抽出し、新たな動画や画像として保存する際に有用なのかしら。
3. 試してみる - サンプルを
サンプルに従い試してみましょう
bash scripts_infer/anidoc_inference.shするとこんな感じのログが出力され、
layers per block is 2
Loading pipeline components...: 100%|██████████████████████████████████████████████████████| 5/5 [00:05<00:00, 1.17s/it]
Downloading: "https://huggingface.co/lllyasviel/Annotators/resolve/main/sk_model.pth" to /mnt/data/shoji_noguchi/venv/anidoc/AniDoc/lineart_extractor/annotator/ckpts/sk_model.pth
100%|███████████████████████████████████████████████████████████████████████████████| 16.4M/16.4M [00:01<00:00, 10.9MB/s]
Downloading: "https://huggingface.co/lllyasviel/Annotators/resolve/main/sk_model2.pth" to /mnt/data/shoji_noguchi/venv/anidoc/AniDoc/lineart_extractor/annotator/ckpts/sk_model2.pth
100%|███████████████████████████████████████████████████████████████████████████████| 16.4M/16.4M [00:00<00:00, 32.5MB/s]
Downloading: "https://github.com/cvg/LightGlue/releases/download/v0.1_arxiv/superpoint_v1.pth" to ./LightGlue/ckpts/superpoint_v1.pth
100%|███████████████████████████████████████████████████████████████████████████████| 4.96M/4.96M [00:00<00:00, 25.2MB/s]
WARNING:py.warnings:/mnt/data/shoji_noguchi/venv/anidoc/AniDoc/./LightGlue/lightglue/lightglue.py:143: UserWarning: FlashAttention is not available. For optimal speed, consider installing torch >= 2.0 or flash-attn.
self.inner_attn = Attention(flash)
Downloading: "https://github.com/cvg/LightGlue/releases/download/v0.1_arxiv/superpoint_lightglue.pth" to ./LightGlue/ckpts/superpoint_lightglue.pth
100%|███████████████████████████████████████████████████████████████████████████████| 45.3M/45.3M [00:02<00:00, 19.9MB/s]
100%|████████████████████████████████████████████████████████████████████████████████████| 25/25 [00:19<00:00, 1.27it/s]
Moviepy - Building video results/sample4_sample4.mp4.
Moviepy - Writing video results/sample4_sample4.mp4
Moviepy - Done !
Moviepy - video ready results/sample4_sample4.mp4resultsディレクトリの下にファイルができあがりました。
$ find results/ -type f -ls
31983519 168 -rw-rw-r-- 1 user user 167988 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0005.png
31983516 160 -rw-rw-r-- 1 user user 162606 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0002.png
31983514 160 -rw-rw-r-- 1 user user 160373 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0000.png
31983522 164 -rw-rw-r-- 1 user user 165770 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0008.png
31983517 164 -rw-rw-r-- 1 user user 164210 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0003.png
31983524 164 -rw-rw-r-- 1 user user 166568 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0010.png
31983521 164 -rw-rw-r-- 1 user user 165390 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0007.png
31983526 164 -rw-rw-r-- 1 user user 166564 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0012.png
31983527 164 -rw-rw-r-- 1 user user 164181 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0013.png
31983518 164 -rw-rw-r-- 1 user user 166043 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0004.png
31983520 168 -rw-rw-r-- 1 user user 169600 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0006.png
31983523 168 -rw-rw-r-- 1 user user 169098 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0009.png
31983515 160 -rw-rw-r-- 1 user user 161359 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0001.png
31983525 164 -rw-rw-r-- 1 user user 166628 Dec 22 23:27 results/sample4_sample4/frames/sample4_sample4_frame_0011.png
31983509 12 -rw-rw-r-- 1 user user 9685 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0009.png
31983500 12 -rw-rw-r-- 1 user user 10732 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0000.png
31983504 12 -rw-rw-r-- 1 user user 10439 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0004.png
31983505 12 -rw-rw-r-- 1 user user 10285 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0005.png
31983506 12 -rw-rw-r-- 1 user user 10305 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0006.png
31983501 12 -rw-rw-r-- 1 user user 10695 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0001.png
31983512 12 -rw-rw-r-- 1 user user 9854 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0012.png
31983511 12 -rw-rw-r-- 1 user user 9706 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0011.png
31983507 12 -rw-rw-r-- 1 user user 9925 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0007.png
31983503 12 -rw-rw-r-- 1 user user 10635 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0003.png
31983508 12 -rw-rw-r-- 1 user user 9672 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0008.png
31983510 12 -rw-rw-r-- 1 user user 9679 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0010.png
31983502 12 -rw-rw-r-- 1 user user 10659 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0002.png
31983513 12 -rw-rw-r-- 1 user user 9898 Dec 22 23:27 results/sample4_sample4/sketches/sample4_sample4_sketch_0013.png
31983528 60 -rw-rw-r-- 1 user user 58472 Dec 22 23:27 results/sample4_sample4/sample4_sample4_reference.png
31983530 68 -rw-rw-r-- 1 user user 67204 Dec 22 23:27 results/sample4_sample4.mp4
31983529 1436 -rw-rw-r-- 1 user user 1467049 Dec 22 23:27 results/sample4_sample4.gifVRAM使用量は、14.3GBほど。
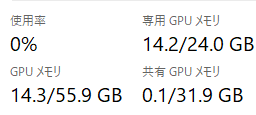
実行時間は42秒ほどでした。
real 0m42.580s
user 1m5.710s
sys 0m8.785s4. 試してみる - 指定した.mp4で
process_video_to_14frames.pyを使用して指定したmp4からフレームを抽出してみて、いろいろ試してみましょう。
取り急ぎ、mp4ファイルを格納するディレクトリを作成します。
mkdir input_video_folderで、適当なmp4ファイル(IMG_1129.mp4)を格納して、
心斎橋店で撮影した元動画がこちら。これをprocess_video_to_14frames.pyスクリプトで14フレームを抽出して生成されたmp4をcontrol_imageとして指定。 pic.twitter.com/OLSrbqnAjC
— NOGUCHI, Shoji (@noguchis) December 22, 2024
以下のコマンドを実行します。
python process_video_to_14frames.pyとしたら、14フレームが抽出され、mp4ファイルも生成されました。
$ find preprocessed_video_folders/ -type f -ls
31983531 1788 -rw-r--r-- 1 user user 1827613 Dec 22 23:56 preprocessed_video_folders/IMG_1129.mp4
31983544 3136 -rw-r--r-- 1 user user 3208889 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_012.png
31983536 3324 -rw-r--r-- 1 user user 3400491 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_004.png
31983539 3268 -rw-r--r-- 1 user user 3343972 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_007.png
31983535 3184 -rw-r--r-- 1 user user 3259855 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_003.png
31983542 3096 -rw-r--r-- 1 user user 3168469 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_010.png
31983532 3116 -rw-r--r-- 1 user user 3187698 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_000.png
31983534 3108 -rw-r--r-- 1 user user 3178716 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_002.png
31983545 3432 -rw-r--r-- 1 user user 3511952 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_013.png
31983533 3144 -rw-r--r-- 1 user user 3215817 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_001.png
31983540 2984 -rw-r--r-- 1 user user 3054778 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_008.png
31983538 3128 -rw-r--r-- 1 user user 3201240 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_006.png
31983543 3136 -rw-r--r-- 1 user user 3209698 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_011.png
31983537 3052 -rw-r--r-- 1 user user 3123860 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_005.png
31983541 3000 -rw-r--r-- 1 user user 3071961 Dec 22 23:56 preprocessed_video_folders/IMG_1129/frame_009.png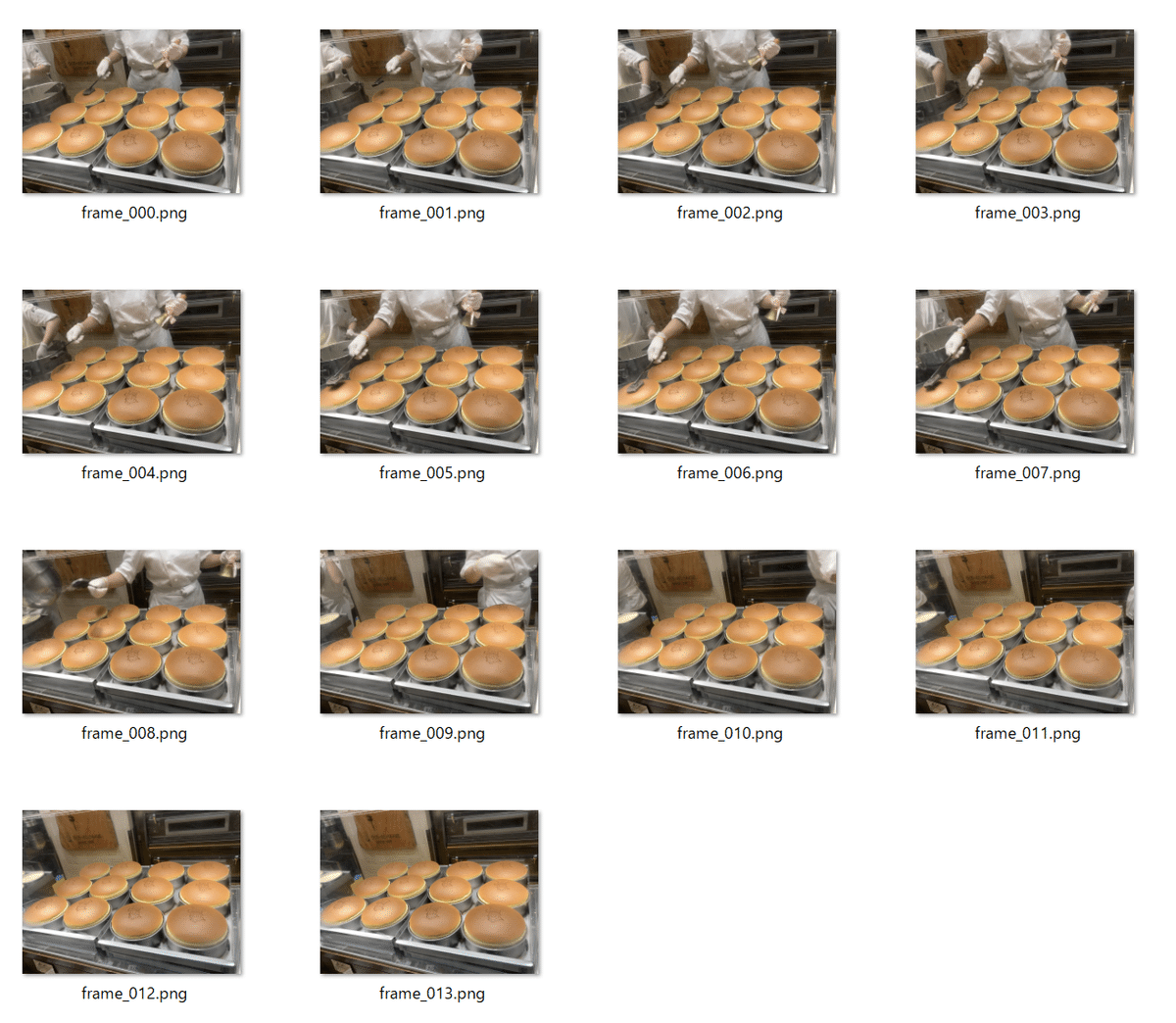
これに着色必要となる参照画像(ref_image)を指定・・・、ここは愛らしいイチゴに登場してもらいましょう。

では、実行です。
CUDA_VISIBLE_DEVICES=0 python scripts_infer/anidoc_inference.py
--all_sketch
--matching
--tracking
--control_image preprocessed_video_folders/IMG_1129.mp4
--ref_image ichigo.png
--output_dir results.1129
--max_point 10生成されたものがこちら。
results.1129/ichigo_IMG_1129.mp4
参照画像で着色されたものだけのmp4がこちら。 pic.twitter.com/LKl28WsOVW
— NOGUCHI, Shoji (@noguchis) December 22, 2024
results.1129/ichigo_IMG_1129.gif
AniDocを試している。https://t.co/oukqu42LgW
— NOGUCHI, Shoji (@noguchis) December 22, 2024
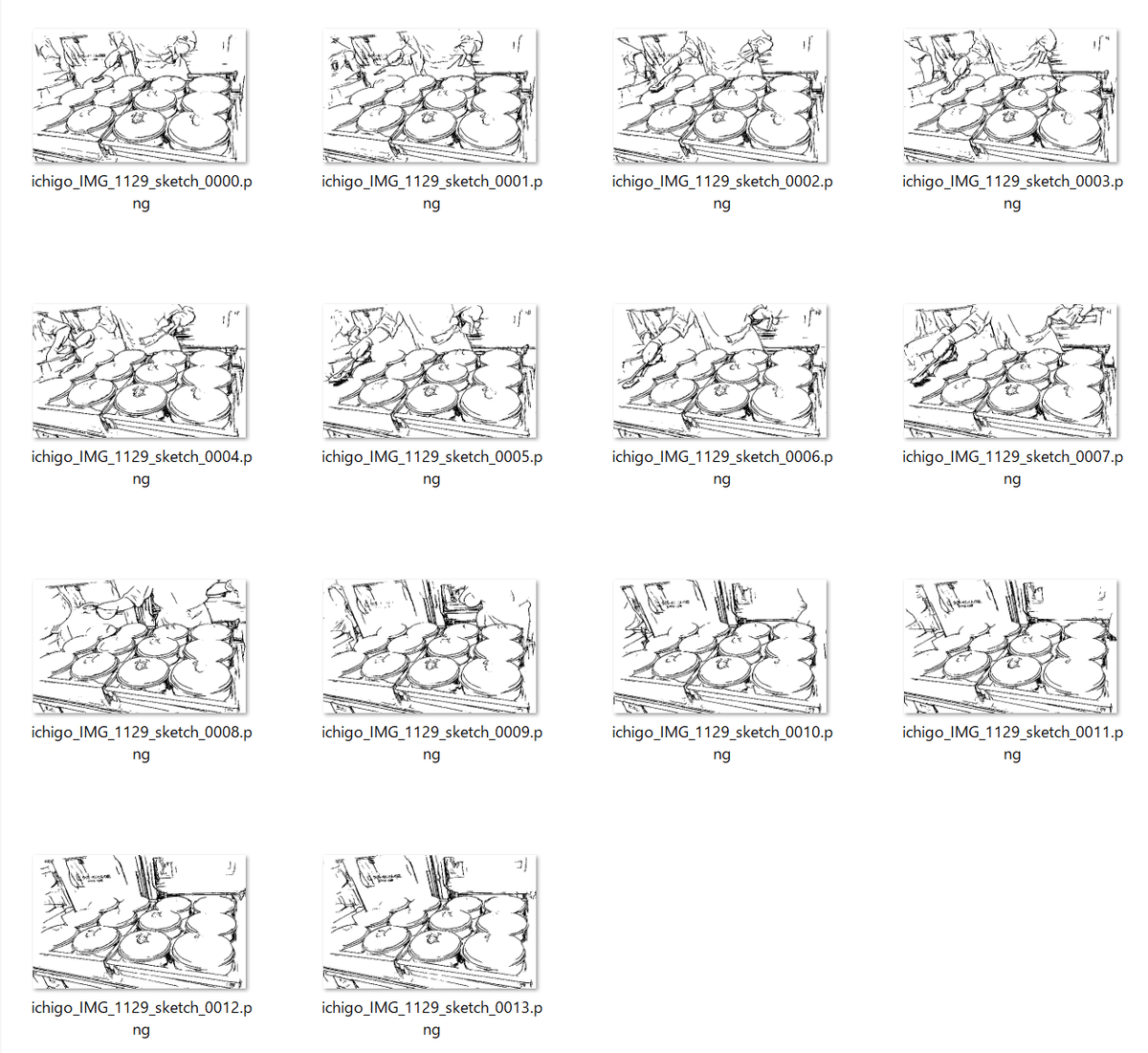
手元にアニメーションがないので、りくろーおじさんのチーズケーキの作成風景の動画から14フレーム抽出した動画をcontrol_imageとし、なにかのイチゴを参照画像として生成されたのがこちら。
チーズケーキが赤くなってほしかったが、そもそも使い方(ry pic.twitter.com/SilI2A97ff
生成されたスケッチ。
生成されたフレーム。
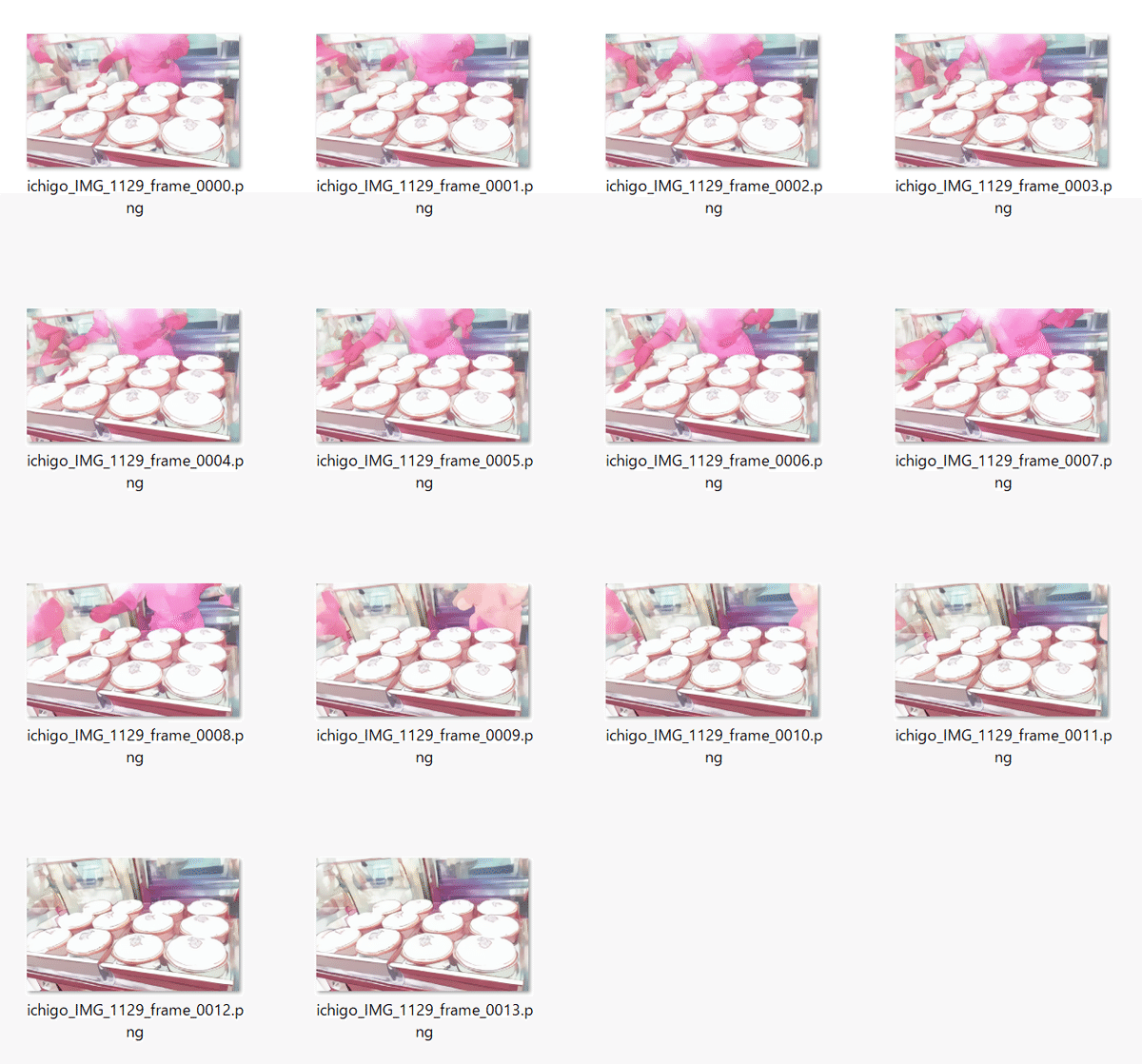
results.1129/ichigo_IMG_1129/frames
うーん、だったので、参照画像(ref_image)を加工して試してみたのがこちら。

