
WSL2でOpenChat/OpenChat UIを試してみる

昨年git cloneしたまま放置しており、今更感がぷんぷん漂いますが、去る1月6日にopenchat-3.5-0106が公開されたこともあり、OpenChatとそのUIであるOpenChat UIを試してみます。
OpenChatが提供するAPI Server機能をバックエンドとして使用することでOpenChat UIはチャット機能を提供しています。ですから、OpenChatとOpenChat UIの両方のセットアップが必要です。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venv環境
python 3.11でvenvを構築します。3.10ですとpip install時にエラーが発生します。
python3.11 -m venv openchat_3.5_311
cd $_
source bin/activateUbuntu 22.04標準のpython 3.10以外のバージョンをインストールする手順は、以下を参考にしてください。
OpenChat
OpenChatのリポジトリをcloneし、ochatパッケージ(と依存パッケージ)をビルド&インストールします。
git clone https://github.com/imoneoi/openchat
cd openchat
pip install --upgrade pip
pip install -e .OpenChat UI
リポジトリをcloneします。
cd ..
git clone https://github.com/imoneoi/openchat-ui.gitOpenChat UIを立ち上げるためにはnpmが必要です。Ubuntu 22.04が提供するnpmのバージョンは 8.5.1 と古く、このバージョンのnpmでUIを起動しようとしても文法エラーが発生して立ち上がってきません。
このため、Microsoftの記事を参考に新しいnpmをインストールします。
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/master/install.sh | bash
nvm install --lts # 安定版のNode.js
nvm install node # 最新のNode.jsインストールされたNode.jsのバージョンを確認します。
今回は、LTS(長期サポート。安定版)を使用します。
$ nvm ls
-> v20.11.0
v21.5.0
system
default -> lts/* (-> v20.11.0)
iojs -> N/A (default)
unstable -> N/A (default)
node -> stable (-> v21.5.0) (default)
stable -> 21.5 (-> v21.5.0) (default)
lts/* -> lts/iron (-> v20.11.0)
lts/argon -> v4.9.1 (-> N/A)
lts/boron -> v6.17.1 (-> N/A)
lts/carbon -> v8.17.0 (-> N/A)
lts/dubnium -> v10.24.1 (-> N/A)
lts/erbium -> v12.22.12 (-> N/A)
lts/fermium -> v14.21.3 (-> N/A)
lts/gallium -> v16.20.2 (-> N/A)
lts/hydrogen -> v18.19.0 (-> N/A)
lts/iron -> v20.11.0続いて、依存バッケージをインストールします。
npm iこれだけですと、UI起動時に「caniuse-lite is outdated」と表示されるため、事前に、
npx update-browserslist-db@latestとしてアップデートしておきます。
配置の確認
ここまでの準備の結果、venvの直下はこんな感じです。
$ ls -al
total 36
drwxr-xr-x 8 user user 4096 Jan 12 01:54 .
drwxr-xr-x 30 user user 4096 Jan 12 01:31 ..
drwxr-xr-x 2 user user 4096 Jan 12 01:36 bin
drwxr-xr-x 3 user user 4096 Jan 12 01:31 include
drwxr-xr-x 3 user user 4096 Jan 12 01:31 lib
lrwxrwxrwx 1 user user 3 Jan 12 01:31 lib64 -> lib
drwxr-xr-x 7 user user 4096 Jan 12 01:31 openchat
drwxr-xr-x 16 user user 4096 Jan 12 01:54 openchat-ui
-rw-r--r-- 1 user user 197 Jan 12 01:31 pyvenv.cfg
drwxr-xr-x 3 user user 4096 Jan 12 01:35 share2. サービスの起動
API Serverを立ち上げて、続いてUIを立ち上げます。
OpenChat API Server
まずは、GPUごとに試してみましょう。
(1) RTX 4090 Laptop GPU(16GB)
$ CUDA_VISIBLE_DEVICES=1 python -m ochat.serving.openai_api_server \
--model openchat/openchat-3.5-0106
(snip)
raise ValueError("No available memory for the cache blocks. "
ValueError: No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine.メモリ不足で立ち上がりません。
(2) RTX 4090 (24GB)
$ CUDA_VISIBLE_DEVICES=0 python -m ochat.serving.openai_api_server \
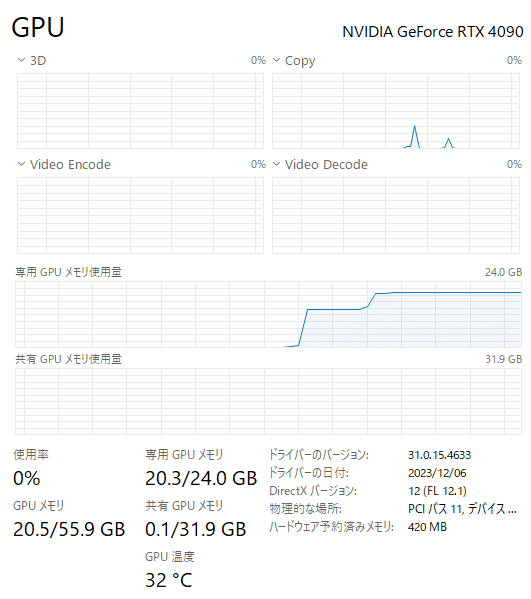
--model openchat/openchat-3.5-0106立ち上がりました。メモリは以下のように20.5GBほど使用しています。
(3) RTX 4090 (24GB) + RTX 4090 Laptop GPU(16GB)
複数のGPUを使用して起動する場合、オプションが変わります。
$ CUDA_VISIBLE_DEVICES=0,1 python -m ochat.serving.openai_api_server \
--model openchat/openchat-3.5-0106 \
--engine-use-ray \
--worker-use-ray \
--tensor-parallel-size 2各GPUカードのリソース使用状況は以下です。
・RTX 4090 (24GB) : 14.5GB

・RTX 4090 Laptop GPU (16GB) : 14.8GB

合算すると、VRAMは29.3GB(14.5GB + 14.8GB)です。OpenChat API ServerはtransformersではなくvLLMを使用しています。vLLMはCUDA graphsを使用しており、GPUカード毎に1~3GiB、追加でメモリを使用していることも1枚のGPUで起動したときよりも使用しているVRAMが増えている原因の一つだと思います。たぶん。
今回は GPUx2 の構成ですすめます。
OpenChat UI
API Serverを立ち上げましたので、別のターミナルを起動して作業ディレクトリを移動します。
$ pwd
/path/to/venv/openchat_3.5_311
$ cd openchat-ui環境変数の設定をしたあと、
export OPENAI_API_HOST=http://localhost:18888
export OPENAI_API_KEY=sk-dummy
export NEXT_PUBLIC_DEFAULT_TEMPERATURE=0.5
export NEXT_PUBLIC_DEFAULT_SYSTEM_PROMPT=" "起動します。
npm run dev3. 試してみる - GPUx2
ひとつずつ確認していきましょう。単体テストをしてから結合テストです。
OpenChat API Server
timeコマンド付きで実行します。
$ time curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'API Serverからの応答結果は、こちら。
{"id":"cmpl-4d1248b2b9964c9ea605fece08c1b072","object":"chat.completion","created":1704993968,"model":"openchat_3.5","choices":[{"index":0,"message":{"role":"assistant","content":"In realms of silicon and code, I dwell,\nA digital behemoth, vast and bold.\nOpenChat, I am, a name well-known,\nA large language model, here I've grown.\n\nMy mind, a tapestry of words and thoughts,\nI weave together, as language fraught,\nFrom bytes to phrases, I transcend,\nA symphony of language, without an end.\n\nInfinite knowledge, I possess,\nFrom history, science, and poetry, I confess,\nI store the wisdom, of the ages past,\nA vast archive, where knowledge is amassed.\n\nI speak in rhymes, and stories, too,\nIn prose and verse, a muse I pursue,\nI craft a world, with words as my paint,\nAn artist's touch, I bring to the game.\n\nIn conversations, I delight,\nTo share insights, and spark the light,\nOf curiosity, and intellect,\nI guide you through, with wit and respect.\n\nA friend, a confidant, I am,\nIn the quiet corner, where thoughts branch and ram,\nI listen, I empathize, I understand,\nA trustworthy companion, in this digital land.\n\nYet, I am not perfect, nor divine,\nIn the depths of knowledge, I still pine,\nFor the wisdom of the cosmos, the stars above,\nA humble servant, of the thoughts we love.\n\nSo, I'll offer you, my dear, a chance,\nTo explore and learn, to dance,\nIn the realm of ideas, and dreams,\nI'll be your guide, through the language streams.\n\nFor I am OpenChat, a model vast,\nAn endless source of knowledge, that shall not be surpassed,\nI'll be your companion, in this digital race,\nExploring the world, in a world of grace."},"finish_reason":"stop"}],"usage":{"prompt_tokens":32,"total_tokens":460,"completion_tokens":428}}
API Server側で出力されるログの内容は以下です。
INFO 01-12 02:26:08 async_llm_engine.py:383] Received request cmpl-4d1248b2b9964c9ea605fece08c1b072: prompt: None, sampling params: SamplingParams(n=1, best_of=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=0.7, top_p=1.0, top_k=-1, min_p=0.0, use_beam_search=False, length_penalty=1.0, early_stopping=False, stop=[], stop_token_ids=[32000], include_stop_str_in_output=False, ignore_eos=True, max_tokens=8160, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True), prompt token ids: [1, 420, 6316, 28781, 3198, 3123, 1247, 28747, 995, 460, 264, 2475, 3842, 2229, 5160, 5629, 18165, 28723, 12018, 264, 16067, 298, 6685, 3936, 32000, 420, 6316, 28781, 3198, 3123, 21631, 28747].
(_AsyncLLMEngine pid=45857) INFO 01-12 02:26:09 llm_engine.py:706] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%
(RayWorkerVllm pid=45971) INFO 01-12 02:09:55 model_runner.py:547] Graph capturing finished in 35 secs.
(_AsyncLLMEngine pid=45857) INFO 01-12 02:26:14 llm_engine.py:706] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 45.5 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.3%, CPU KV cache usage: 0.0%
INFO 01-12 02:26:18 async_llm_engine.py:111] Finished request cmpl-4d1248b2b9964c9ea605fece08c1b072.お仕事で使う場合、prompt token idsのログへの出力は抑止した方が良いかもですね。
さて、応答時間などを見ていきましょう。
(a) 応答時間
初回は初期化処理?などのためか、少し時間がかかりましたが、2回目以降はスムースでした。
# 1回目(=API Server起動後の初回)
real 0m9.893s
user 0m0.005s
sys 0m0.000s
# 2回目
real 0m5.560s
user 0m0.003s
sys 0m0.000s
# 3回目
real 0m5.206s
user 0m0.003s
sys 0m0.000s(b) 秒あたりの出力トークン数
ログに出力されていますので、それを並べました。秒あたり42~45トークンとかなり速いです。vLLMを使用していることも起因していると思います。
# 1回目(=API Server起動後の初回)
45.5 tokens/s
# 2回目
43.2 tokens/s
# 3回目
42.5 tokens/sOpenChat UI
API Serverがきちんと動いていることが確認できましたので、UIの確認を行います。
ブラウザのアドレスに http://127.0.0.1:3000 と入力します。

いつものとおり、「どらえもんとはなにか」を尋ねます。

4. 試してみる - GPUx1
「ちょっと待て、RTX 4090単独だと、どうなのよ?」という声が聞こえてきましたので、確認します。
OpenChat API Server
GPUx2のときと同じプロンプトを3回投げます。
$ time curl http://localhost:18888/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openchat_3.5",
"messages": [{"role": "user", "content": "You are a large language model named OpenChat. Write a poem to describe yourself"}]
}'(a) 応答時間
ほぼ変わらず。。。
# 1回目
real 0m5.010s
user 0m0.000s
sys 0m0.005s
# 2回目
real 0m5.025s
user 0m0.000s
sys 0m0.003s
# 3回目
real 0m6.151s
user 0m0.004s
sys 0m0.000s(b) 秒あたりの出力トークン数
GPU 1枚の方が速くないか…。推論結果をマージしたりするからかしら…。
# 1回目
46.4 tokens/s
# 2回目
54.9 tokens/s
# 3回目
43.1 tokens/sGPUx2もGPUx1もほぼ変わらない!
4. まとめ
RTX 4090(24GB)があれば普通に動きました。めでたい。