
WSL2でPowerInferを試してみる

12/25 22:40(JST)追記。
WSL2のメモリ割当が48GBでもswap領域に漏れていたようで、+1GBの49GBにしたら、tpsが1.5 ~ 1.9が2.0 ~ 2.1まで速くなりました。
コンシューマ向けのGPUでも、A100に迫る性能が!という触れ込みの「PowerInfer」を試してみます。今回、試してみるモデルは以下の2つです。
LLaMA(ReLU)-2-70B
LLaMA(ReLU)-2-7B
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、メモリは64GB、OSはWindows 11+WSL2です。
はい、コンシューマ向けPCです!
1. 準備
venv準備
python3 -m venv powerinfer
cd $_
source bin/activatePowerInferのセットアップ
git cloneしてパッケージをインストールします。
git clone https://github.com/SJTU-IPADS/PowerInfer
cd PowerInfer
pip install -r requirements.txtpip listの結果はこちらです。
$ pip list
Package Version Editable project location
------------------------ ---------- ----------------------------------------------------------------------
certifi 2023.11.17
charset-normalizer 3.3.2
cvxopt 1.3.2
filelock 3.13.1
fsspec 2023.12.2
gguf 0.5.2 /path/to/venv/powerinfer/PowerInfer/gguf-py
huggingface-hub 0.20.1
idna 3.6
Jinja2 3.1.2
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
packaging 23.2
pip 22.0.2
powerinfer 0.0.1 /path/to/venv/powerinfer/PowerInfer/powerinfer-py
PyYAML 6.0.1
regex 2023.12.25
requests 2.31.0
safetensors 0.4.1
sentencepiece 0.1.99
setuptools 59.6.0
sympy 1.12
tokenizers 0.15.0
torch 2.1.2
tqdm 4.66.1
transformers 4.36.2
triton 2.1.0
typing_extensions 4.9.0
urllib3 2.1.0ビルド
CMakeを使ってPowerInferをビルドします。RTX 4090なので、ONと指定します。
cmake -S . -B build -DLLAMA_CUBLAS=ON
cmake --build build --config Release2. モデルのダウンロード
Original Model WeightsとPredictor Weightsをダウンロードして変換するのはファイルサイズを考えると厳しいため、変換済みのファイルを有り難くダウンロードします。
LLaMA(ReLU)-2-70B
PowerInfer GGUF モデルを4ビット量子化されています。
mkdir ReluLLaMA-70B-PowerInfer-GGUF
wget -P ReluLLaMA-70B-PowerInfer-GGUF https://huggingface.co/PowerInfer/ReluLLaMA-70B-PowerInfer-GGUF/resolve/main/llama-70b-relu.q4.powerinfer.ggufLLaMA(ReLU)-2-7B
7Bは量子化されておらず。
mkdir ReluLLaMA-7B-PowerInfer-GGUF
wget -P ReluLLaMA-7B-PowerInfer-GGUF https://huggingface.co/PowerInfer/ReluLLaMA-7B-PowerInfer-GGUF/resolve/main/llama-7b-relu.powerinfer.gguf3. 試してみる - 70B - Mem:48GB
WSL2のメモリ割当変更: 32GB -> 48GB
素のWSL2のままだと 32GBしかメモリ割当が無く、swapに退避されてしまってDisk I/Oがとんでもないことになってしまいました。
このため、割当メモリを 48GBに設定変更します!
$ cat /mnt/c/Users/WhoAmI/.wslconfig
[wsl2]
memory=48GB
swap=8GBPowerShellを立ち上げてWSLを再起動します。
PS C:> wsl --shutdown聞いてみよう
./build/bin/main -m ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Doraemon is" --vram-budget 8Doraemon is a popular Japanese manga series that has been adapted into multiple television anime series and films. Doraemon: Nobita's Little Star Wars! is the 14th feature-length Doraemon film, which was released in Japan on March 8, 2009. The film follows the adventures of title character Nobita Nobi (Nobuo Nobi) as he joins forces with robot cat Doraemon to fight an army of aliens from the future that have invaded Earth in order to turn its people into dolls. Doraemon: Nobita's Little Star Wars!
パソコンで普通に動いていることに感動している!
総時間は1分30秒。
llama_print_timings: load time = 64314.04 ms
llama_print_timings: sample time = 31.70 ms / 128 runs ( 0.25 ms per token, 4037.98 tokens per second)
llama_print_timings: prompt eval time = 6052.19 ms / 5 tokens ( 1210.44 ms per token, 0.83 tokens per second)
llama_print_timings: eval time = 83929.07 ms / 127 runs ( 660.86 ms per token, 1.51 tokens per second)
llama_print_timings: total time = 90058.92 ms続きを聞いてみましょう。
$ ./build/bin/main -m ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Doraemon is a popular Japanese manga series that has been adapted into multiple television anime series and films. Doraemon: Nobita's Little Star Wars! is the 14th feature-length Doraemon film, which was released in Japan on March 8, 2009. The film follows the adventures of title character Nobita Nobi (Nobuo Nobi) as he joins forces with robot cat Doraemon to fight an army of aliens from the future that have invaded Earth in order to turn its people into dolls. Doraemon: Nobita's Little Star Wars!" --vram-budget 8太字が追加のレスポンスです。
Doraemon is a popular Japanese manga series that has been adapted into multiple television anime series and films. Doraemon: Nobita's Little Star Wars! is the 14th feature-length Doraemon film, which was released in Japan on March 8, 2009. The film follows the adventures of title character Nobita Nobi (Nobuo Nobi) as he joins forces with robot cat Doraemon to fight an army of aliens from the future that have invaded Earth in order to turn its people into dolls. Doraemon: Nobita's Little Star Wars! was directed by Shinnosuke Yoshida and produced by Shin-Ei Animation. The film was released on Blu-ray and DVD on December 2, 2013.
The series has also inspired a number of video games for the Nintendo Entertainment System, Game Boy Color, Game Boy Advance, PlayStation Portable, Wii, Nintendo DS and mobile phones. The first game in the series is Nobita no Dorabian Night (1987), released by Hudson Soft on the Famicom system.
Nobita's Little Star Wars
処理時間はこちら。入力プロンプトの評価が約27秒、レスポンスの生成が約68秒、計95秒程度です。
llama_print_timings: load time = 2893.91 ms
llama_print_timings: sample time = 30.63 ms / 128 runs ( 0.24 ms per token, 4178.77 tokens per second)
llama_print_timings: prompt eval time = 26704.66 ms / 133 tokens ( 200.79 ms per token, 4.98 tokens per second)
llama_print_timings: eval time = 68292.92 ms / 127 runs ( 537.74 ms per token, 1.86 tokens per second)
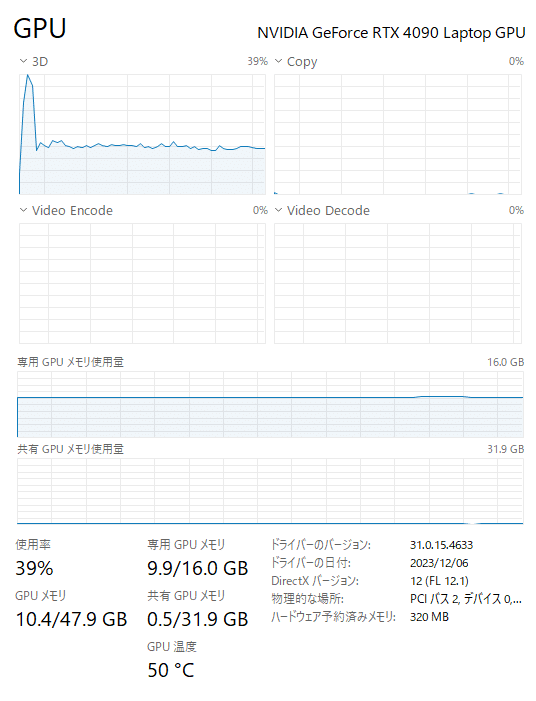
llama_print_timings: total time = 95070.24 msリソースの使用状況
topコマンドで、推論中のCPUとメモリの使用量を確認しました。メモリはぎりぎり足りたみたいです。
Tasks: 41 total, 1 running, 40 sleeping, 0 stopped, 0 zombie
%Cpu(s): 21.8 us, 0.1 sy, 0.0 ni, 78.1 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
MiB Mem : 48173.8 total, 309.9 free, 833.6 used, 47030.4 buff/cache
MiB Swap: 8192.0 total, 8190.5 free, 1.5 used. 46340.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3387 shoji_n+ 20 0 126.6g 40.6g 40.5g S 691.0 86.3 8:59.54 main
344 root 20 0 154160 64404 11548 S 0.0 0.1 0:01.46 python3.10
427 root 20 0 44252 35120 7628 S 0.0 0.1 0:00.83 python3GPUの専用メモリは、8GBと指定したけれども、9 ~ 10GB程度使用していました。
4. 試してみる - 7B
70Bが動くのであれば、7Bは安心です。
聞いてみよう
./build/bin/main -m ./ReluLLaMA-7B-PowerInfer-GGUF/llama-7b-relu.powerinfer.gguf -n 128 -t 8 -p "Doraemon is" --vram-budget 8Doraemon is one of the most popular and well-known anime characters in Japan. It has been around since 1969 and has become a cultural icon there, much like Mickey Mouse and Bugs Bunny have become icons here in the United States. As with any popular character, it has had its fair share of spin-offs and adaptations, from live action films to video games and even an arcade game called Doraemon: The Legendary Golden Rod.
Now another adaptation is coming, this one for smartphones. It's a rhythm-action game that will be available later this year in
総時間が約12秒。7倍近く速い。そりゃそうか。
llama_print_timings: load time = 24322.89 ms
llama_print_timings: sample time = 21.20 ms / 128 runs ( 0.17 ms per token, 6039.16 tokens per second)
llama_print_timings: prompt eval time = 467.13 ms / 5 tokens ( 93.43 ms per token, 10.70 tokens per second)
llama_print_timings: eval time = 11275.26 ms / 127 runs ( 88.78 ms per token, 11.26 tokens per second)
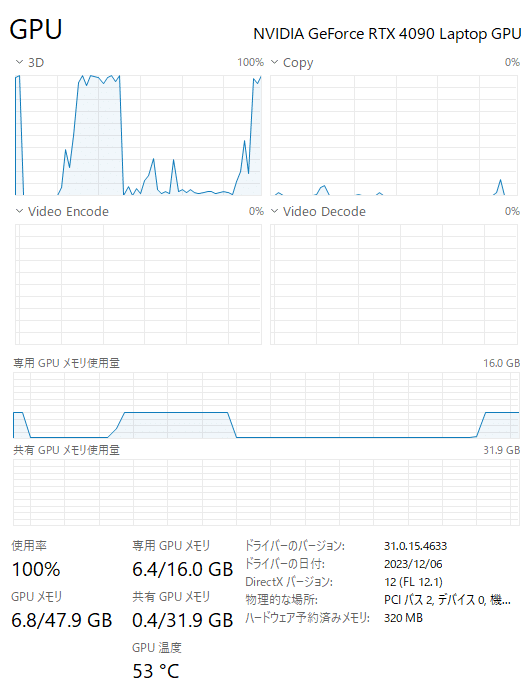
llama_print_timings: total time = 11795.47 msリソースの使用状況
GPU専用メモリの増加量は6GBぐらいに制限されていました。
5. 再び試してみる - 70B - Mem:49GB
メモリ48GBでもswap領域に漏れていたようで、WSL2のメモリ割当を+1GBの49GBにしたら、トークン/秒が 2.0 を超えるようになりました。
./build/bin/main -m ./ReluLLaMA-70B-PowerInfer-GGUF/llama-70b-relu.q4.powerinfer.gguf -n 128 -t 8 -p "Doraemon is" --vram-budget 8Doraemon is a manga series written and illustrated by Fujiko Fujio, which debuted on July 14, 1969 in Japan. Several anime television series based on the manga have been produced, as well as many animated feature films.
The series follows Nobita Nobi, a fourth-grader who finds a mysterious blue cat named Doraemon, who travels back in time from the 22nd century future to aid Nobita in stopping Nobita's troublesome behavior. The manga was initially published monthly on January 14, 196
処理時間はこちら。レスポンスの生成に 61秒。はやい!
llama_print_timings: load time = 2413.92 ms
llama_print_timings: sample time = 23.51 ms / 128 runs ( 0.18 ms per token, 5445.19 tokens per second)
llama_print_timings: prompt eval time = 1055.33 ms / 5 tokens ( 211.07 ms per token, 4.74 tokens per second)
llama_print_timings: eval time = 61177.50 ms / 127 runs ( 481.71 ms per token, 2.08 tokens per second)
llama_print_timings: total time = 62297.18 ms推論中のtopコマンドはこちら。
Tasks: 41 total, 1 running, 40 sleeping, 0 stopped, 0 zombie
%Cpu(s): 21.7 us, 0.1 sy, 0.0 ni, 78.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 49181.8 total, 5973.5 free, 918.4 used, 42290.0 buff/cache
MiB Swap: 8192.0 total, 8192.0 free, 0.0 used. 47271.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3301 shoji_n+ 20 0 131.0g 40.7g 40.5g S 692.7 84.7 10:16.89 main
351 root 20 0 154164 70336 17512 S 0.0 0.1 0:01.37 python3.106. まとめ
メモリ割当を48GB 49GB にすれば、70Bでもふつうに動きました。