
WSL2でStable Cascadeを試してみる

「この革新的なテキストから画像へのモデルは、品質、柔軟性、微調整、および効率性のための新しいベンチマークを設定し、ハードウェアのバリアをさらに排除することに重点を置いた、興味深い3段階のアプローチを導入」したらしいStable Cascadeを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venv環境を構築して、
python3 -m venv stable-cascade
cd $_
source bin/activateHugging FaceのREADME内、code exampleにある内容(stabilityai/stable-cascade)に従って、パッケージのインストールです。
pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v32. コード
流し込むコードはこちら。code exampleにある内容をベースに、画像を表示するためのコード2行を最後に追加し、プロンプトは cat を Doraemon に変更しています。
(擬人化しなくてもドラえもんはドラえもんなわけだが、ま、いいか)
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipeline
device = "cuda"
num_images_per_prompt = 2
prior = StableCascadePriorPipeline.from_pretrained(
"stabilityai/stable-cascade-prior",
torch_dtype=torch.bfloat16
).to(device)
decoder = StableCascadeDecoderPipeline.from_pretrained(
"stabilityai/stable-cascade",
torch_dtype=torch.float16
).to(device)
prompt = "Anthropomorphic Doraemon dressed as a pilot"
negative_prompt = ""
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
#Now decoder_output is a list with your PIL images
for image in decoder_output:
image.show()3. 試してみる
RTX 4090 Laptop GPU(16GB)ですと、いつも見慣れたCUDA OOMです。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 768.00 MiB. GPU 0 has a total capacty of 15.99 GiB of which 0 bytes is free. Including non-PyTorch memory, this process has 17179869184.00 GiB memory in use. Of the allocated memory 14.23 GiB is allocated by PyTorch, and 460.74 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFでは、RTX 4090(24GB)で試しましょう。モデルロードから画像生成に至るGPUリソースはこんな推移です。最終的には17.1GB使用しています。
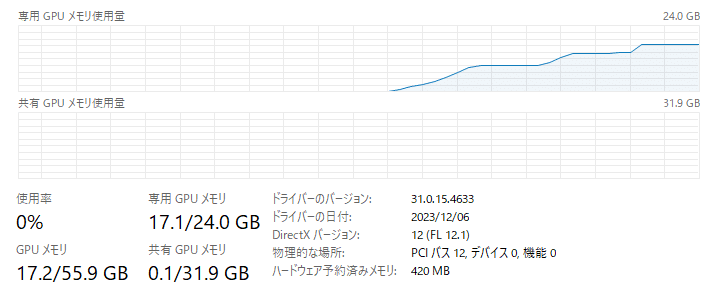
生成に要した時間は prior が3秒、decodeが2秒、あわせて5秒です。
100%|██████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:03<00:00, 5.36it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 4.81it/s]コードを流し込んで表示された画像がこちら。


かっ、かわいい。
まとめ
VRAMは17.1GB使用でした。VRAM 24GBのGPUじゃないと厳しいですね。
生成に要した時間は おおよそ5秒でした。速いですねぇ。
さて、学習の「試してみる」は時間があるときに・・・。https://github.com/Stability-AI/StableCascade