WSL2でreasoning-modelを試してみる

「Hugging Face TransformersのAutoModelForCausalLMを拡張し、モンテカルロ木探索(MCTS)を用いて逐次的な探索に基づくテキスト生成を行う」「これにより、Chain of Thought(CoT)データセットで学習されたモデルの推論能力をさらに向上させる」らしいreasoning-modelを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
仮想環境
python3 -m venv reasoning-model
cd $_
source bin/activateGitリポジトリをクローン。
git clone https://github.com/Hajime-Y/reasoning-model.git
cd reasoning-modelつづいて、パッケージのインストール。
pip install -e .
pip install accelerateです。
2. 流し込むコード
README.md 記載の内容です。こちらを infer.pyとでも名前を付けて保存しましょう。
# モジュールのインポート
from reasoning_model import ReasoningModelForCausalLM
from tree_utils import print_tree_with_best_path
from transformers import AutoTokenizer
# tokenizerとmodelの準備
model_name = "HachiML/QwQ-CoT-0.5B-JA"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = ReasoningModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
system_prompt = "You are a helpful and harmless assistant. You should think step-by-step." # 固定を推奨
prompt = "231 + 65*6 = ?"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
]
# chat_templateとtokenize
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# MCTSを用いて生成(Google ColabのT4インスタンスで1分程度かかる)
final_tokens, final_node = model.generate(
**model_inputs,
iterations_per_step=5, # 1推論ステップの探索に何回シミュレーションを行うか。長いほど精度が高まる可能性はあるが、推論時間が伸びる。
max_iterations=15, # 推論ステップの上限: 0.5Bモデルの場合、そこまで長いステップの推論はできないため10~15くらいが妥当。
mini_step_size=32, # mini-step: 32tokens。Step as Action戦略を採用する場合、ここを512など大きな数字にする。(実行時間が伸びるため非推奨)
expand_threshold=0, # ノードを拡張するために必要なそのノードの訪問回数の閾値。デフォルトの0で、拡張には1回以上の訪問が求められる。基本デフォルトで良い。
step_separator_ids=None, # Reasoning Action StrategyでStep as Actionを採用するときの区切りとなるトークンのIDリスト。NoneでモデルConfigの値を利用するため、変更は非推奨。Step as Action不採用時には[]を設定する。
)
# 結果をテキスト化
final_text = tokenizer.decode(final_tokens, skip_special_tokens=True)
print("=== 最終生成テキスト ===")
print(final_text)
# ツリー構造表示
print("=== ツリー構造 ===")
print_tree_with_best_path(final_node, tokenizer)3. コードを読んでみる
reasoning_model.py で、TransformersのPreTrainedModelを継承した ReasoningModelForCausalLMクラスを定義。
モデルの処理フローはこんな感じ。起点は reasoning_mode.pyのgenerateメソッド。
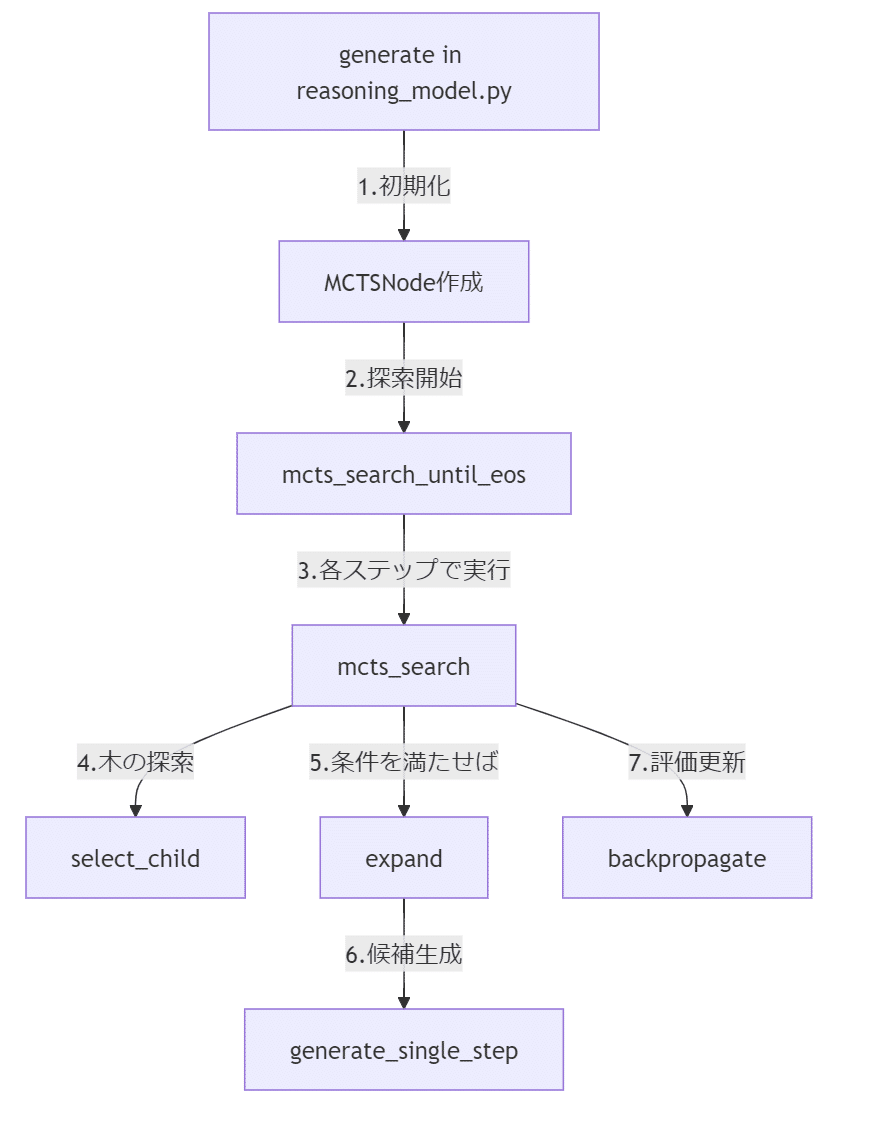
「5.条件を満たせば」は、visit_countがexpand_thresholdを超えていたら拡張し、しきい値未満ならばbackpropagationする、という感じらしいです。はい。
generate_single_stepメソッドで、指定したモデルで1ステップ分のテキスト生成を行っています。
4. 試してみる
では、実行。
CUDA_VISIBLE_DEVICES=0 python -i ./infer.pyプロンプトを再掲しておきます。
system_prompt = "You are a helpful and harmless assistant. You should think step-by-step."
prompt = "231 + 65*6 = ?"
実行結果がこちら。
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
From v4.47 onwards, when a model cache is to be returned, `generate` will return a `Cache` instance instead by default (as opposed to the legacy tuple of tuples format). If you want to keep returning the legacy format, please set `return_legacy_cache=True`.
=== 最終生成テキスト ===
与えられた式を計算します。
\[ 231 + 65 \times 6 \]
まず、括弧内の値を計算します。
\[ 65 \times 6 = 390 \]
次に、計算の結果を元の方程式に代入します。
\[ 231 + 390 = 621 \]
待って間違えたかもしれない。計算の見直しをします。
計算の結果は正しいようです。
\[ 231 + 390 = 621 \]
したがって、最終的な答えは:
\[ \boxed{621} \]
621
=== ツリー構造 ===
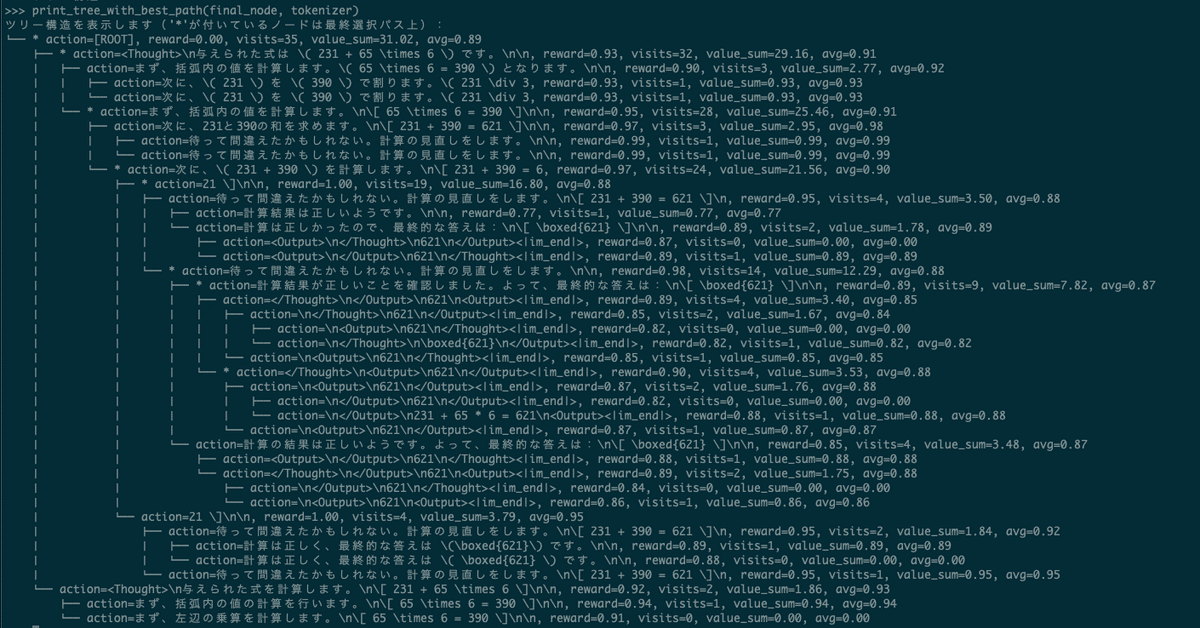
ツリー構造を表示します('*'が付いているノードは最終選択パス上):
└── * action=[ROOT], reward=0.00, visits=35, value_sum=30.80, avg=0.88
├── action=<Thought>\n与えられた式は $231 + 65 \times 6$ です。\n\n, reward=0.90, visits=2, value_sum=1.84, avg=0.92
│ ├── action=まず、括弧内の計算を計算します。\n\[ 65 \times 6 = 390 \]\n\n, reward=0.94, visits=1, value_sum=0.94, avg=0.94
│ └── action=まず、括弧内の値を計算します。 \n\[ 65 \times 6 = 390 \] \n\n次に、この, reward=0.91, visits=0, value_sum=0.00, avg=0.00
└── * action=<Thought>\n与えられた式を計算します。\n\[ 231 + 65 \times 6 \]\n\n, reward=0.92, visits=32, value_sum=28.96, avg=0.91
├── * action=まず、括弧内の値を計算します。\n\[ 65 \times 6 = 390 \]\n\n, reward=0.96, visits=28, value_sum=25.30, avg=0.90
│ ├── action=次に、この結果を231と掛けます。\n\[ 231 + 390 = 621 \]\n\n, reward=0.96, visits=4, value_sum=3.83, avg=0.96
│ │ ├── action=待って間違えたかもしれない。計算の見直しをします。\n\n, reward=1.00, visits=2, value_sum=1.87, avg=0.93
│ │ │ ├── action=再確認したところ、計算は正しかったようです。最終的な答えは:\n\[ \boxed{621} \]<|im_end|>, reward=0.86, visits=0, value_sum=0.00, avg=0.00
│ │ │ └── action=再確認すると、計算は正しかったようです。\n\[ 231 + 390 = 621 \]\n\n, reward=0.87, visits=1, value_sum=0.87, avg=0.87
│ │ └── action=待って間違えたかもしれない。計算の見直しをします。\n\n, reward=1.00, visits=1, value_sum=1.00, avg=1.00
│ └── * action=次に、計算の結果を元の方程式に代入します。\n\[ 231 + 390 = 621 \]\n\n, reward=0.91, visits=23, value_sum=20.52, avg=0.89
│ ├── action=待って間違えたかもしれない。計算の見直しをします。\n\n, reward=1.00, visits=4, value_sum=3.64, avg=0.91
│ │ ├── action=再確認した結果、計算は正しく、最終的な答えは:\n\[ \boxed{621} \]\n\n, reward=0.87, visits=1, value_sum=0.87, avg=0.87
│ │ └── action=再確認すると、計算は正しかったようです。最終的な答えは:\n\[ \boxed{621} \]\n\n, reward=0.90, visits=2, value_sum=1.76, avg=0.88
│ │ ├── action=<Output>\n</Thought>\n621\n</Output><|im_end|>, reward=0.87, visits=1, value_sum=0.87, avg=0.87
│ │ └── action=<Output>\n</Thought>\n621\n</Output><|im_end|>, reward=0.87, visits=0, value_sum=0.00, avg=0.00
│ └── * action=待って間違えたかもしれない。計算の見直しをします。\n\n, reward=1.00, visits=18, value_sum=15.97, avg=0.89
│ ├── * action=計算の結果は正しいようです。\n\[ 231 + 390 = 621 \]\n\n, reward=0.88, visits=14, value_sum=12.42, avg=0.89
│ │ ├── * action=したがって、最終的な答えは:\n\[ \boxed{621} \]\n\n, reward=0.98, visits=9, value_sum=7.92, avg=0.88
│ │ │ ├── * action=</Thought>\n</Output>\n621\n<Output><|im_end|>, reward=0.89, visits=4, value_sum=3.48, avg=0.87
│ │ │ │ ├── action=\n</Output>\n621\n</Thought><|im_end|>, reward=0.84, visits=1, value_sum=0.84, avg=0.84
│ │ │ │ └── action=\n<Output>\n621\n</Output><|im_end|>, reward=0.87, visits=2, value_sum=1.75, avg=0.87
│ │ │ │ ├── action=\n<Output>\n621\n</Output><|im_end|>, reward=0.84, visits=0, value_sum=0.00, avg=0.00
│ │ │ │ └── action=\n<Output>\n231 + 65 * 6 = 621\n</Thought><|im_end|>, reward=0.88, visits=1, value_sum=0.88, avg=0.88
│ │ │ └── action=</Thought>\n<Output>\n621\n</Output><|im_end|>, reward=0.90, visits=4, value_sum=3.46, avg=0.87
│ │ │ ├── action=\n<Output>\n621\n</Output><|im_end|>, reward=0.87, visits=2, value_sum=1.71, avg=0.85
│ │ │ │ ├── action=\n</Thought>\n621\n</Thought><|im_end|>, reward=0.80, visits=0, value_sum=0.00, avg=0.00
│ │ │ │ └── action=\n<Output>\n621\n</Output><|im_end|>, reward=0.83, visits=1, value_sum=0.83, avg=0.83
│ │ │ └── action=\n</Output>\n621\n<Output><|im_end|>, reward=0.86, visits=1, value_sum=0.86, avg=0.86
│ │ └── action=したがって、最終的な答えは:\n\[ \boxed{621} \]\n\n, reward=0.98, visits=4, value_sum=3.62, avg=0.90
│ │ ├── action=</Thought>\n<Output>\n621\n</Output><|im_end|>, reward=0.90, visits=2, value_sum=1.77, avg=0.89
│ │ │ ├── action=\n<Output>\n621\n</Output><|im_end|>, reward=0.87, visits=1, value_sum=0.87, avg=0.87
│ │ │ └── action=\n</Output>\n621\n</Output><|im_end|>, reward=0.86, visits=0, value_sum=0.00, avg=0.00
│ │ └── action=<Output>\n</Thought>\n621\n</Output><|im_end|>, reward=0.87, visits=1, value_sum=0.87, avg=0.87
│ └── action=計算は正しかったようです。最終的な答えは:\n\[ \boxed{621} \]\n\n, reward=0.86, visits=3, value_sum=2.55, avg=0.85
│ ├── action=</Output>\n<Output>\n621\n</Thought><|im_end|>, reward=0.88, visits=1, value_sum=0.88, avg=0.88
│ └── action=</Output>\n<Output>\n621\n</Output><|im_end|>, reward=0.81, visits=1, value_sum=0.81, avg=0.81
└── action=まず、括弧内の値を計算します。\n\[ 65 \times 6 = 390 \]\n\n, reward=0.96, visits=3, value_sum=2.74, avg=0.91
├── action=次に、この結果を231上に加えると計算されます。\n\[ 231 + 390 = 621, reward=0.88, visits=1, value_sum=0.88, avg=0.88
└── action=次に、この結果を231上に加えると、\n\[ 231 + 390 = 621 \, reward=0.91, visits=1, value_sum=0.91, avg=0.91
>>> 思考過程が木構造で可視化されている!おもしろい!