
WSL2でFish Speechを試してみる

某界隈で有名なFish SpeechをローカルPCで立ち上げるため、試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
環境構築
python3 -m vevn fishspeech
cd $_
source bin/activateリポジトリをクローン。
git clone https://github.com/fishaudio/fish-speechパッケージのインストールです。
※requirements.txtが見当たらないので、trial & error で試した結果です。
pip install torch torchaudio transformers gradio librosa pyrootutils loguru kui lightning wandb opencc faster_whisper hydra-core einops natsort loralib vector_quantize_pytorchモデルのダウンロード
huggingface-cliコマンドで所定のディレクトリにダウンロードします。
huggingface-cli download fishaudio/fish-speech-1.2-sft --local-dir checkpoints/fish-speech-1.2-sft2. Web UI立ち上げ
では、gradioを立ち上げましょう。
CUDA_VISLBLE_DEVICES=0 python tools/webui.py \
--llama-checkpoint-path checkpoints/fish-speech-1.2-sft \
--decoder-checkpoint-path checkpoints/fish-speech-1.2-sft/firefly-gan-vq-fsq-4x1024-42hz-generator.pth立ち上がりました。
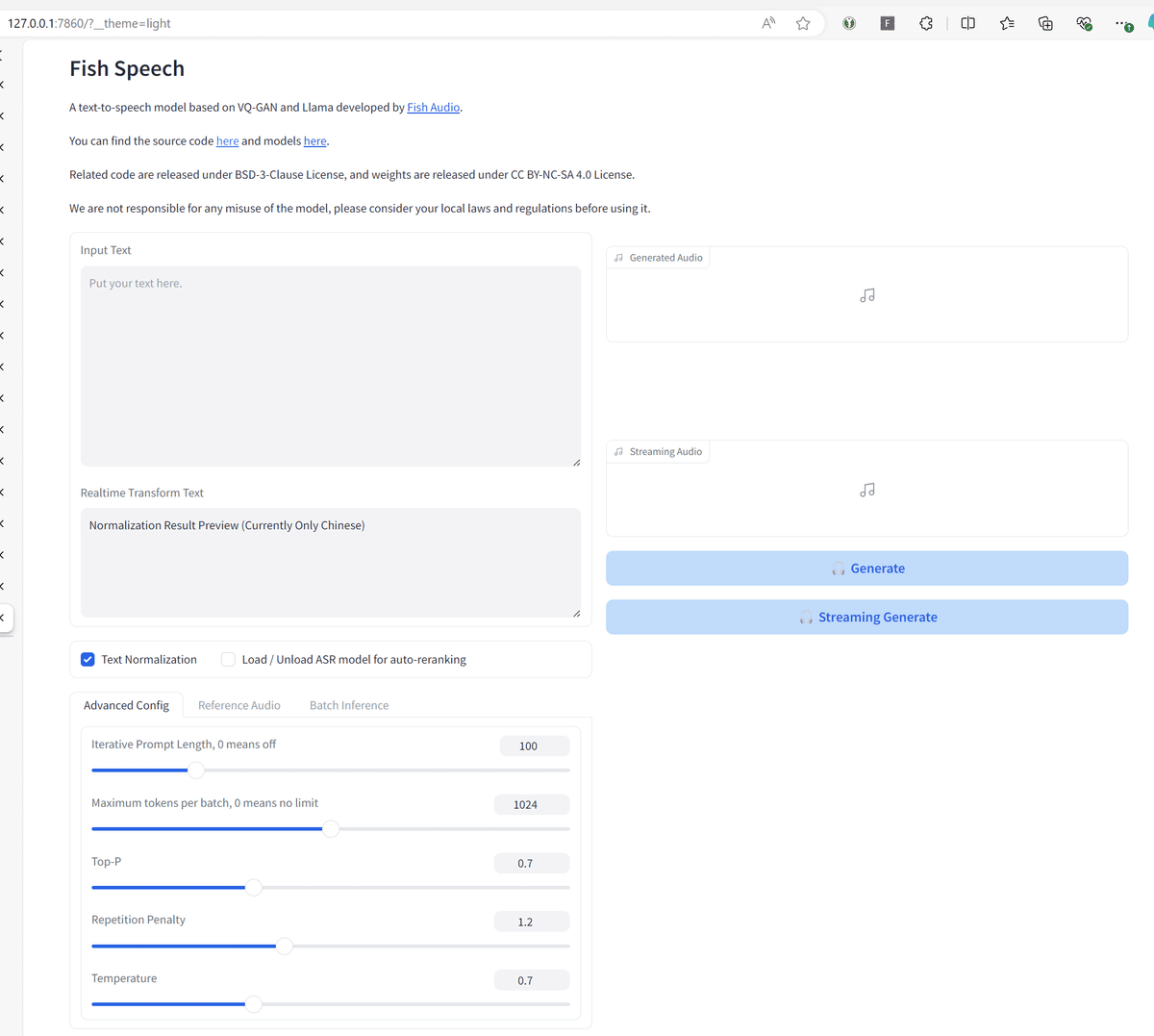
Input Text「今日は、雨でした。」として、Reference Audioで自分の声を記録した後、Generateボタンを押下して生成された音声がこちら。
RTX 4090(24GB)で5秒ほどでした。VRAM使用量は4.5GBほど。