
WSL2でViewDiffを試してみる...が

「本物の環境で現実世界の3Dオブジェクトの高品質でマルチビューの一貫した画像を生成」するらしいViewDiffを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
環境構築
python3 -m venv viewdiff
cd $_
source bin/activateリポジトリをクローン。
git clone https://github.com/facebookresearch/ViewDiff
cd ViewDiffパッケージのインストールです。
パッケージのインストール。トレーニング時、torchは2.0.1が要求されます。また、CUDA 11(.7)である必要があるため、torchは2.0.1+cu117をインストールします。
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
pip install -r requirements.txt
pip install --upgrade triton==2.1.0続いて、pytorch3dパッケージのインストールです。
ビルド時にCUDA 11.7が要求されますので、環境変数PATHの設定でCUDA 11が優先されるように変更しておきます。
export PATH=/usr/local/cuda-11/bin:$PATH
pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"なお、CUDA 11とCUDA 12を共存させる方法は、こちらを参照ください。
2. データ準備
(1) データセットのダウンロード
co3d(Common Objects in 3D dataset)にあるデータセットをダウンロードして所定のディレクトリに配置します。
まずは、リポジトリをクローンします。
git clone https://github.com/facebookresearch/co3d
cd co3dダウンロード先のディレクトリ(ここでは dataset としました)を作成します。
mkdir -p datasetダウンロードします。すべてをダウンロードすると5.5TBらしいので、今回は、数あるデータセットの中からteddybear だけをダウンロードします。
python ./co3d/download_dataset.py --download_folder ./dataset --download_categories teddybear
cd ..teddybearだけでも173GB必要。zipファイルも別に169GB。
$ du -sh ./co3d/dataset/teddybear
173G ./co3d/dataset/teddybear
$ ls -ld ./co3d/dataset/teddybear*
drwxr-xr-x 1291 user user 49152 Mar 7 20:13 ./co3d/dataset/teddybear
-rw-r--r-- 1 user user 47978935 Mar 7 16:41 ./co3d/dataset/teddybear_000.zip
-rw-r--r-- 1 user user 20057560456 Mar 7 18:14 ./co3d/dataset/teddybear_001.zip
-rw-r--r-- 1 user user 19942843476 Mar 7 18:10 ./co3d/dataset/teddybear_002.zip
-rw-r--r-- 1 user user 19897334876 Mar 7 18:06 ./co3d/dataset/teddybear_003.zip
-rw-r--r-- 1 user user 19860684205 Mar 7 18:18 ./co3d/dataset/teddybear_004.zip
-rw-r--r-- 1 user user 20073335109 Mar 7 19:48 ./co3d/dataset/teddybear_005.zip
-rw-r--r-- 1 user user 19994857469 Mar 7 19:56 ./co3d/dataset/teddybear_006.zip
-rw-r--r-- 1 user user 19882100456 Mar 7 19:56 ./co3d/dataset/teddybear_007.zip
-rw-r--r-- 1 user user 20056925367 Mar 7 19:13 ./co3d/dataset/teddybear_008.zip
-rw-r--r-- 1 user user 19922552083 Mar 7 20:08 ./co3d/dataset/teddybear_009.zip
-rw-r--r-- 1 user user 1954044300 Mar 7 19:55 ./co3d/dataset/teddybear_010.zip
$ ls -ld ./co3d/dataset/teddybear*.zip | awk'{sum+=$5}END{print sum}'
181690216732
$展開されたディレクトリ配下を見ると、そのデータ数は1,287ありました。
$ ls -d co3d/dataset/teddybear/[1-9]* | wc -l
1287
$(2) BLIP-2 テキストキャプションの生成
カテゴリごとに画像から BLIP-2 テキストキャプションを生成します。
export CO3DV2_DATASET_ROOT=$(pwd)/co3d/dataset
python -m viewdiff.data.co3d.generate_blip2_captions --dataset-config.co3d_root ${CO3DV2_DATASET_ROOT} --output_file ${CO3DV2_DATASET_ROOT}/co3d_blip2_captions.jsonこの処理が終了すると、jsonファイルが書き出されます。
$ ls -l co3d/dataset/co3d_blip2_captions*
-rw-r--r-- 1 user user 457 Mar 7 20:36 co3d/dataset/co3d_blip2_captions_07.03.2024_20:36:03.948886_intermediate.json
-rw-r--r-- 1 user user 400759 Mar 7 20:45 co3d/dataset/co3d_blip2_captions_07.03.2024_20:45:12.963035.json
$--outputオプションで指定したファイル名とちょっと違いますね。タイムスタンプが含まれています。
jsonファイルの中身を確認しましょう。以下のように画像ファイルごとの生成プロンプトが記された内容となっています。
{
"teddybear": {
"392_47576_94593": [
"a red stuffed animal sitting on a blue and white checkered table",
"a red pig sitting on a blue and white checkered cloth",
"a teddy bear sitting on a blue and white checkered table",
"a red stuffed animal sitting on a blue and white checkered table",
"a stuffed bear sitting on a bed"
],
"610_96831_194027": [
"a teddy bear sitting on top of a plastic chair",
"a stuffed animal sitting on top of a green chair",
"a teddy bear sitting on a green stool",
"a teddy bear sitting on a small stool",
"a teddy bear sitting on a small stool"
],
"529_76746_148287": [
(snip)また、./co3d/dataset/teddybear/custom_sequence_metadata.jsonが新規作成されます。このファイルには、シーケンスデータ毎に「点群データ(point cloud)を有するか」「有効な再中心化か」「無効な再中心化か」というデータが記録されています。
$ head -16 ./co3d/dataset/teddybear/custom_sequence_metadata.json
{
"101_11758_21048": {
"has_pointcloud": true,
"is_valid_recentered": false,
"is_invalid_recentered": false
},
"101_11763_21624": {
"has_pointcloud": true,
"is_valid_recentered": false,
"is_invalid_recentered": false
},
"101_11768_21754": {
"has_pointcloud": true,
"is_valid_recentered": false,
"is_invalid_recentered": false
},
$この処理ではVRAMは8.3GBほどを使用、処理時間は9分ほどでした。

Generate Captions: 100%|███ (snip) ███| 1548/1548 [09:11<00:00, 2.81it/s](3) Prior preservationデータセットの生成
カテゴリごとに、DreamBoothで知られるPrior preservation(同じクラス画像で追加学習する)手法を使用して、データセットを生成します。
前段で生成されたjsonファイルを引数に指定します。
※ファイル名にタイムスタンプが含まれています。このため、個々の環境で異なりますので、ご注意ください。
export CO3DV2_DATASET_ROOT=$(pwd)/co3d/dataset
python -m viewdiff.data.co3d.generate_co3d_dreambooth_data --prompt_file ${CO3DV2_DATASET_ROOT}/co3d_blip2_captions_07.03.2024_20:45:12.963035.json --output_path ${CO3DV2_DATASET_ROOT}/dreambooth_prior_preservation_dataset./co3d/dataset/dreambooth_prior_preservation_dataset/teddybear というディレクトリにデータ(JPEG画像ファイル)が生成されます。
$ ls ./co3d/dataset/dreambooth_prior_preservation_dataset/teddybear/*.jpg | wc -l
1200
$入力データはサンプリングして300が対象。それに対して4つずつ画像が生成されていますので1,200あります。
この処理ではVRAMは4.6GBほどを使用、処理時間は63分ほどでした。

Generate for teddybear: 100%|███ (snip) ███| 300/300 [1:03:22<00:00, 12.67s/it](4) ポーズの再中心化
カテゴリ毎に、各オブジェクトが単位立方体内に収まるようにポーズを再中心化します。
python -m viewdiff.data.co3d.save_recentered_sequences --dataset-config.co3d_root ${CO3DV2_DATASET_ROOT}入力データそれぞれに対して、処理が行われます。
loaded 1236/1287 valid sequences from /mnt/data/venv/viewdiff/ViewDiff/co3d/dataset/teddybear/custom_sequence_metadata.json
Parsed teddybear: using 1236 sequences with 246202 frames in total.1,287あるデータのうち1,236が処理対象となっています。それでは、そのうちの1つであるシーケンスデータ 94_10371_19623 の処理結果を見てみましょう。recentered.plyファイルが生成されています。
$ ls -l ./co3d/dataset/teddybear/94_10371_19623/ | grep recenter
-rw-r--r-- 1 user user 152 Mar 7 23:01 bbox_recentered.npy
-rw-r--r-- 1 user user 23520204 Mar 7 23:01 recentered.ply
drwxr-xr-x 2 user user 16384 Mar 7 23:01 recentered_poses_world2cam
$
$ ls -l ./co3d/dataset/teddybear/94_10371_19623/recentered_poses_world2cam
total 808
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000001.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000002.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000003.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000004.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000005.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000006.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000007.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000008.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000009.npy
(snip)
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000193.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000194.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000195.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000196.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000197.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000198.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000199.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000200.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000201.npy
-rw-r--r-- 1 user user 192 Mar 7 23:01 pose_world2cam_frame000202.npy
$また、./co3d/dataset/teddybear/custom_sequence_metadata.jsonも合わせて更新されます。is_valid_recenteredの行がfalseからtrueに更新されているのがわかります。
$ head -16 ./co3d/dataset/teddybear/custom_sequence_metadata.json
{
"101_11758_21048": {
"has_pointcloud": true,
"is_valid_recentered": true,
"is_invalid_recentered": false
},
"101_11763_21624": {
"has_pointcloud": true,
"is_valid_recentered": true,
"is_invalid_recentered": false
},
"101_11768_21754": {
"has_pointcloud": true,
"is_valid_recentered": true,
"is_invalid_recentered": false
},
$さて、この処理はCPUとメモリがガンガン使用します。WSL2に割り当てたメモリが32GBだとOOMが発生しpythonプロセスがkillされました。
MiB Mem : 31947.9 total, 224.2 free, 31383.7 used, 340.0 buff/cache
MiB Swap: 8192.0 total, 4533.3 free, 3658.7 used. 150.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
246551 shoji_n+ 20 0 37.4g 29.9g 17092 R 1181 95.8 12:36.19 pythonこのため、WSL2への割当メモリを49GBにして試行しています。ただ、それでもメモリとswap領域も食い潰してしまう事象が発生しました。ctrl+cして、再実行(途中から再開される)でお茶を濁しています。なお、処理は60分ほどで終了しました。
これで、データ準備は完了です。要した時間は、ダウンロード時間を除き、RTX 4090(24GB)使用で約140分でした。
3. 学習を試みる
学習用スクリプトの確認
学習用にshell scriptが2つ用意されています。
・2 x A100 80GB 向け : viewdiff/scripts/train.sh
・1 x 3090 向け : viewdiff/scripts/train_small.sh
持つ者と、持たざる者と言い換えればいいのかしら。いずれにせよ、パラメータを弄らなくてよいので、有り難いことです。
これらの差分は以下のようにバッチサイズ等の違いだけです。
$ diff -u viewdiff/scripts/train*.sh
--- viewdiff/scripts/train.sh 2024-03-06 10:27:41.846080162 +0900
+++ viewdiff/scripts/train_small.sh 2024-03-07 16:40:33.389339171 +0900
@@ -3,14 +3,14 @@
export CO3DV2_DATASET_ROOT=$1
-accelerate launch --mixed_precision="no" --multi_gpu -m viewdiff.train \
+accelerate launch --mixed_precision="no" -m viewdiff.train \
--finetune-config.io.pretrained_model_name_or_path $2 \
--finetune-config.io.output_dir $3 \
--finetune-config.io.experiment_name "train_teddybear" \
--finetune-config.training.mixed_precision "no" \
--finetune-config.training.dataloader_num_workers "0" \
--finetune-config.training.num_train_epochs "1000" \
---finetune-config.training.train_batch_size "4" \
+--finetune-config.training.train_batch_size "1" \
--finetune-config.training.dreambooth_prior_preservation_loss_weight "0.1" \
--finetune_config.training.noise_prediction_type "epsilon" \
--finetune_config.training.prob_images_not_noisy "0.25" \
@@ -20,19 +20,19 @@
--finetune-config.optimizer.learning_rate "5e-5" \
--finetune-config.optimizer.vol_rend_learning_rate "1e-3" \
--finetune-config.optimizer.vol_rend_adam_weight_decay "0.0" \
---finetune-config.optimizer.gradient_accumulation_steps "8" \
+--finetune-config.optimizer.gradient_accumulation_steps "1" \
--finetune-config.optimizer.max_grad_norm "5e-3" \
---finetune-config.cross_frame_attention.to_k_other_frames "4" \
+--finetune-config.cross_frame_attention.to_k_other_frames "2" \
--finetune-config.cross_frame_attention.random_others \
--finetune-config.cross_frame_attention.with_self_attention \
--finetune-config.cross_frame_attention.use_temb_cond \
--finetune-config.cross_frame_attention.mode "pretrained" \
---finetune-config.cross_frame_attention.n_cfa_down_blocks "1" \
---finetune-config.cross_frame_attention.n_cfa_up_blocks "1" \
+--finetune-config.cross_frame_attention.n_cfa_down_blocks "0" \
+--finetune-config.cross_frame_attention.n_cfa_up_blocks "0" \
--finetune-config.cross_frame_attention.unproj_reproj_mode "with_cfa" \
---finetune-config.cross_frame_attention.num_3d_layers "5" \
+--finetune-config.cross_frame_attention.num_3d_layers "1" \
--finetune-config.cross_frame_attention.dim_3d_latent "16" \
---finetune-config.cross_frame_attention.dim_3d_grid "128" \
+--finetune-config.cross_frame_attention.dim_3d_grid "64" \
--finetune-config.cross_frame_attention.n_novel_images "1" \
--finetune-config.cross_frame_attention.vol_rend_proj_in_mode "multiple" \
--finetune-config.cross_frame_attention.vol_rend_proj_out_mode "multiple" \
@@ -43,10 +43,10 @@
--finetune-config.model.pose_cond_mode "sa-ca" \
--finetune-config.model.pose_cond_coord_space "absolute" \
--finetune-config.model.pose_cond_lora_rank "64" \
---finetune-config.model.n_input_images "5" \
+--finetune-config.model.n_input_images "3" \
--dataset-config.co3d-root $CO3DV2_DATASET_ROOT \
--dataset-config.category $4 \
---dataset-config.max_sequences "500" \
+--dataset-config.max_sequences 50 \
--dataset-config.batch.load_recentered \
--dataset-config.batch.use_blip_prompt \
--dataset-config.batch.crop "random" \
@@ -61,4 +61,4 @@
--validation-dataset-config.batch.crop "random" \
--validation-dataset-config.batch.image_width "256" \
--validation-dataset-config.batch.image_height "256" \
---validation-dataset-config.dataset_args.n_frames_per_sequence "5"
+--validation-dataset-config.dataset_args.n_frames_per_sequence "3"よく見ると teddyabear とハードコーディングされている箇所が2箇所あります。内容からして、$4(処理対象のカテゴリ)に文字列置換したほうが良い気がしますが、コードは修正したくないのでそのままにしておきます。(今回、ダウンロードしたデータが teddybearなので問題はなさそうですから)。
実行
では、実行です。
./viewdiff/scripts/train_small.sh ${CO3DV2_DATASET_ROOT} "stabilityai/stable-diffusion-2-1-base" outputs/train teddybearむむむ。
Steps: 1%| | 53027/9907000 [12:56:13<2127:40:43, 1.29it/s, lr=5e-5, step_loss=0.00768]想定していたことではありますが、2140時間近くかかりそうです。。。
READMEを見ると、
In our experiments, we train the model for 60K iterations.
らしく、A100 80GB 2枚想定のtrain.shを見るに、
300データ ÷ 4バッチ × 1,000 エポック = 75,000
なので、60,000経過したら CTRL+Cしてもいいんじゃない?という感じなのでしょうかね。いずれにせよ、RTX 4090しか持たぬ民は、厳しいです。
ですので、とりあえずは、できるところまでやってみましょう。
GPUリソース
GPU #1のRTX 4090 24GBが train_small.sh を実行しています。23,789 MiB 使用しています。
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.36 Driver Version: 546.33 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 ... On | 00000000:02:00.0 Off | N/A |
| N/A 43C P8 7W / 150W | 571MiB / 16376MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce RTX 4090 On | 00000000:0C:00.0 Off | Off |
| 32% 57C P2 213W / 450W | 23789MiB / 24564MiB | 79% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+4. 評価を試みる
生成されたチェックポイントをモデルに変換し、そのモデルを使用して評価する、という流れで試してみます。
モデルへの変換
チェックポイントは、./outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-XXXX という名前でのディレクトリ配下に書き出されています。ここでは、このnoteを執筆中の最新のチェックポイントである 53,500 をモデルに変換します。
python -m viewdiff.convert_checkpoint_to_model \
--checkpoint-path outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-53500/
チェックポイントの親ディレクトリ(同じレベルのディレクトリ)に saved_model_from_checkpoint-XXXX という名前のディレクトリが作成され、その配下に変換ファイルが出力されています。
$ ls -l outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/saved_model_from_checkpoint-53500
total 36
-rw-r--r-- 1 user user 6152 Mar 9 00:58 config.json
drwxr-xr-x 2 user user 4096 Mar 9 00:58 feature_extractor
-rw-r--r-- 1 user user 658 Mar 9 00:58 model_index.json
drwxr-xr-x 2 user user 4096 Mar 9 00:58 scheduler
drwxr-xr-x 2 user user 4096 Mar 9 00:58 text_encoder
drwxr-xr-x 2 user user 4096 Mar 9 00:58 tokenizer
drwxr-xr-x 2 user user 4096 Mar 9 00:58 unet
drwxr-xr-x 2 user user 4096 Mar 9 00:58 vaeモデルの評価
変換されたモデルを使用して、どんなあんばいであるかを確認しましょう。
CUDA_VISIBLE_DEVICES=0 ./viewdiff/scripts/test/test_spherical_360_256x256.sh \
${CO3DV2_DATASET_ROOT} \
outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/saved_model_from_checkpoint-53500 \
outputs/single-batch-uncond-generation \
10 \
teddybear \
50まだまだ学習中ではありますが、こんな感じで画像が出力されております。


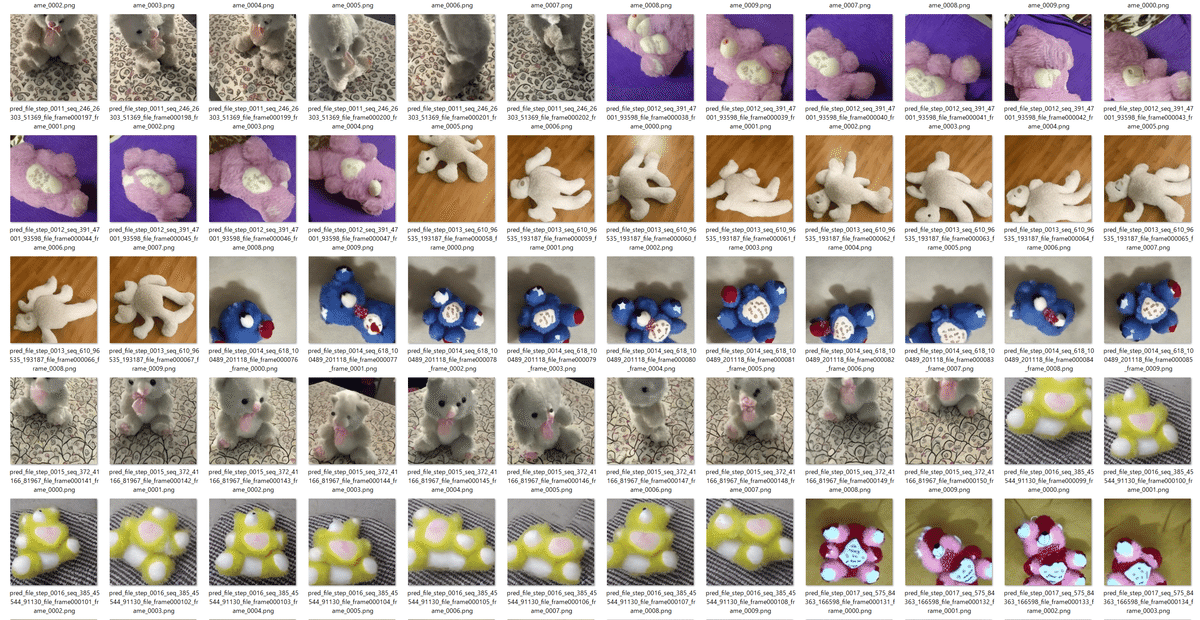
5. まとめ
RTX 4090(24GB)でも学習はできました。ただ、少なくとも2000時間は軽く超えそうな見込み。現実的な時間で終えることができるか?は別問題ですから、試してみる方は注意しましょう。
きっとそういうとき、論文には実行時間のことは書いてないと思います。知らんけど。
6. 追記 - 2024/3/18
WSL2が落ちる
CTR+Cを押下することなく学習させ続けていたのですが、10日経過した本日3/18昼過ぎ、WSL2にてランタイムエラー発生。当然、pythonプロセスも落ちました…。
03/18/2024 12:51:29 - INFO - __main__ - removing checkpoints: checkpoint-1059500
03/18/2024 12:51:30 - INFO - accelerate.accelerator - Saving current state to outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000
Configuration saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/unet/config.json
Model weights saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/unet/diffusion_pytorch_model.safetensors
Model weights saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/unet/pytorch_lora_weights.safetensors
03/18/2024 12:51:40 - INFO - accelerate.checkpointing - Optimizer state saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/optimizer.bin
03/18/2024 12:51:40 - INFO - accelerate.checkpointing - Scheduler state saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/scheduler.bin
03/18/2024 12:51:40 - INFO - accelerate.checkpointing - Random states saved in outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000/random_states_0.pkl
03/18/2024 12:51:40 - INFO - __main__ - Saved state to outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000
Steps: 11%|█ | 1061469/9907000 [241:05:00<1918:37:01, 1.28it/s, lr=5e-5, step_loss=0.0237]最後の画像生成
ということで、最後のcheckpointを用いて、画像生成です!
export CO3DV2_DATASET_ROOT=$(pwd)/co3d/dataset
CUDA_VISIBLE_DEVICES=1 python -m viewdiff.convert_checkpoint_to_model
--checkpoint-path outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/checkpoint-1061000
CUDA_VISIBLE_DEVICES=0 ./viewdiff/scripts/test/test_spherical_360_256x256.sh
${CO3DV2_DATASET_ROOT}
outputs/train/teddybear/50_sequences/subset_all/input_3/train/train_teddybear/saved_model_from_checkpoint-1061000/ outputs/single-batch-uncond-generation
10
teddybear
50





学習したモデル
Hugging Faceにアップロードしておきました。ご笑納ください。
この記事が気に入ったらサポートをしてみませんか?