
WSL2でLlama-3-ELYZA-JPを試してみる

「『GPT-4』を上回る日本語性能のLLM」はLlama-3-ELYZA-JP-70Bらしいですが、そのファミリーである8Bモデルを試してみます。
8Bのモデルを今回使用します。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv elyza
cd $_
source bin/activateバッケージのインストール。
pip install torch transformers accelerate2. 流し込むコード
以下のコードを /path/to/query.py として保存します。
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--tokenizer-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
tokenizer_id = model_id
if args.tokenizer_path:
tokenizer_id = args.tokenizer_path
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
#torch_dtype=torch.bfloat16,
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
#
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages3. 試してみる
pythonを起動します。
$ python -i /path/to/query.py --model-path elyza/Llama-3-ELYZA-JP-8B聞いてみましょう。
>>> history = q("ドラえもんとはなにか")
--- prompt
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは誠実で優秀な日本人のアシスタントです。<|eot_id|><|start_header_id|>user<|end_header_id|>
ドラえもんとはなにか<|eot_id|><|start_header_id|>assistant<|end_header_id|>
--- output
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
ドラえもんは、藤子・F・不二雄原作の日本の漫画作品です。小学館の「コロコロコミック」に1970年から1985年まで連載されました。
物語は、22世紀から現代に来たロボットのドラえもんと、主人公の小学4年生の少年・のび太が繰り広げるSFファンタジーです。ドラえもんは、のび太やその友達たちを助けるため、未来から持ってきた道具「秘密道具」を使って事件を解決します。
代表的な秘密道具としては、「タイムマシン」、「どこでもドア」、「四次元ポケット」などがあります。これらの道具は、のび太たち が日常生活や社会問題を学ぶきっかけにもなることが多く、教育的要素も含まれています。
連載終了後も、テレビアニメや映画などのメディア展開が行われ、長期にわたり日本国民に親しまれている作品です。
prompt tokens = 40
output tokens = 241 (17.513165 [tps])
total time = 13.761076 [s]ドラえもんは、藤子・F・不二雄原作の日本の漫画作品です。小学館の「コロコロコミック」に1970年から1985年まで連載されました。
物語は、22世紀から現代に来たロボットのドラえもんと、主人公の小学4年生の少年・のび太が繰り広げるSFファンタジーです。ドラえもんは、のび太やその友達たちを助けるため、未来から持ってきた道具「秘密道具」を使って事件を解決します。
代表的な秘密道具としては、「タイムマシン」、「どこでもドア」、「四次元ポケット」などがあります。これらの道具は、のび太たち が日常生活や社会問題を学ぶきっかけにもなることが多く、教育的要素も含まれています。
連載終了後も、テレビアニメや映画などのメディア展開が行われ、長期にわたり日本国民に親しまれている作品です。
コロコロコミックの創刊は1977年5月15日なのだよ。
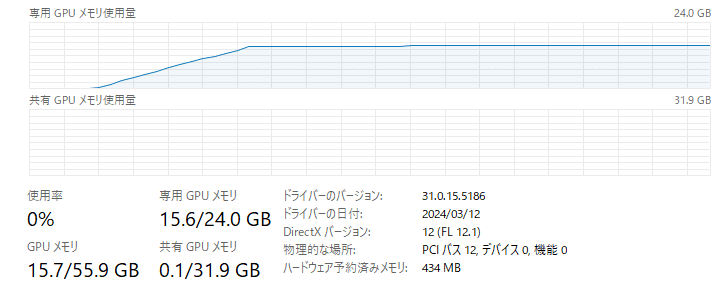
VRAM使用量は 15.6GB付近でした。
4. 性能比較
llama.cppやvLLMもバージョンアップしているようなので、せっかくなので3つのモデルの性能比較をしてみます。
llama-cpp-pythonのインストール方法と試してみるコードは、以下の記事を参考にしてください。
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query4llama-cpp.py \
--model-path elyza/Llama-3-ELYZA-JP-8B \
--ggml-model-path elyza/Llama-3-ELYZA-JP-8B-GGUF \
--ggml-model-file Llama-3-ELYZA-JP-8B-q4_k_m.gguf同様に、vLLMはこちら。
# normal
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query4vllm.py --model-path elyza/Llama-3-ELYZA-JP-8B
# awq
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query4vllm.py --model-path elyza/Llama-3-ELYZA-JP-8B-AWQでは、比較結果です。
(1-1) elyza/Llama-3-ELYZA-JP-8B w/ transformers
- prompt tokens = 40
- output tokens = 241 (17.513165 [tps])
- total time = 13.761076 [s]
(1-2) elyza/Llama-3-ELYZA-JP-8B w/ vLLM
- prompt tokens = 40
- output tokens = 256 (45.040229 [tps])
- total time = 5.683808 [s]
(2) elyza/Llama-3-ELYZA-JP-8B-AWQ w/ vLLM
- prompt tokens = 40
- output tokens = 256 (84.191201 [tps])
- total time = 3.040698 [s]
(3) elyza/Llama-3-ELYZA-JP-8B-GGUF w/ python-llama-cpp
- prompt tokens = 35
- output tokens = 256 (29.356053 [tps])
- total time = 8.720518 [s]
AWQ x vLLM、速いですね。