WSL2でInternVL2_5-8Bを試してみる

「OpenGVLabが開発したマルチモーダル大規模言語モデル(MLLM)で、視覚情報とテキスト情報を統合的に処理する能力を持ちます。このモデルは、約8億パラメータを持つ視覚エンコーダー「InternViT-300M-448px-V2_5」と、約70億パラメータを持つ言語モデル「internlm2_5-7b-chat」を組み合わせ、視覚と言語の両方の情報を効果的に理解・生成することが可能」らしいInternVL2_5-8Bを試してみます。
モデルは 1, 2, 4, 8, 26, 38, 78 Bがそれぞれ公開されています。VisionとLanguageの各パートは以下の組み合わせとなっています。
InternViT-300M-448px-V2_5 + QWen2.5-0.5B-Instruct
InternViT-300M-448px-V2_5 + internlm2_5-1_8b-chat
InternViT-300M-448px-V2_5 + QWen2.5-3B-Instruct
InternViT-300M-448px-V2_5 + internlm2_5-7b-chat
InternViT-6B-448px-V2_5 + internlm2_5-20b-chat
InternViT-6B-448px-V2_5 +Qwen2.5-32B-Instruct
InternViT-6B-448px-V2_5 +Qwen2.5-72B-Instruct
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
仮想環境
python3 -m venv internvl2_5
cd $_
source bin/activateつづいて、パッケージのインストール。
pip install torch transformers accelerate einops timm decord sentencepieceです。
流し込むコードで使用されている ./examplesの画像と動画もダウンロードしておきます。
wget -P examples https://huggingface.co/OpenGVLab/InternVL2_5-8B/resolve/main/examples/image1.jpg
wget -P examples https://huggingface.co/OpenGVLab/InternVL2_5-8B/resolve/main/examples/image2.jpg
wget -P examples https://huggingface.co/OpenGVLab/InternVL2_5-8B/resolve/main/examples/red-panda.mp42. 流し込むコード
README.md 記載の inference with transformers です。こちらを infer.pyとでも名前を付けて保存しましょう。
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/InternVL2_5-8B'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')3. 試してみる
では、実行。。。
CUDA_VISIBLE_DEVICES=0 python ./infer.pyサンプルコードが長いので、プロンプトを区切って示しましょう。
(1) ただの会話
User: Hello, who are you?
Assistant: Hello! I am an AI assistant whose name is InternVL, developed jointly by Shanghai AI Lab, Tsinghua University and other partners.
User: Can you tell me a story?
Assistant: Of course! Here's a brief story for you:
In a quaint village nestled in the heart of a lush green valley, there was a small, picturesque cottage. The cottage was made from the finest timber and was adorned with brightly colored flowers every spring. Its inhabitants, the humble Smiths, lived a simple yet fulfilling life, surrounded by the beauty of nature.
One day, an unexpected visitor arrived at the cottage. It was a young boy, no more than ten years old, covered in mud and tears. He had wandered far from home, and the villagers had found him and brought him to the Smiths. The elderly Mr. and Mrs. Smith took him in, providing him with food, a warm bed, and a place to dry off.
Over the next few days, the boy grew closer to the Smiths and shared stories of his life in the nearby forest, filled with adventures and the wonders of nature. The Smiths listened with interest, eager to learn about the boy's experiences. They taught him kindness and the value of simple pleasures, such as reading books by the fire or picking berries for dessert.
As time passed, the boy grew stronger and healthier under the care of the Smiths. One evening, as the boy was preparing to leave, he realized he had forgottent to thank the Smiths. With tears in his eyes, he thanked them for their kindness and promised to never forget them.
It was then that Mr. and Mrs. Smith noticed the boy had lost something precious – a small, intricately carved wooden bird. The boy had told them it was his grandfather's, a token of their family's history and love. Understanding the boy's sadness, the Smiths decided to craft a beautiful replica of the bird, which they gifted to the boy before he returned home.
The boy left the village with a lighter heart. Years later, when he returned to the valley, he returned with a large wooden bird, carved in the finest detail. It was a gift to represent all the gratitude he felt towards the Smiths and the kindness they had shown him.
And so, the story of the small cottage and its kind inhabitants spread through the village, a testament to the power of kindness and the enduring bonds formed when we care for one another. The wooden bird, now placed above the fireplace, served as a reminder of the beauty of friendship and the gratitude that binds us all.
ここは普通の会話ですね。
(2) 画像1枚での質問

User: <image>
Please describe the image shortly.
Assistant: A red panda rests on a wooden platform, surrounded by a natural setting with tree branches and green leaves in the background. The red panda's distinct reddish-brown fur, white markings, and large ears are clearly visible.
翻訳。
ユーザー: <画像>画像について簡単に説明してください。
アシスタント: レッサーパンダが木の台の上に休んでいます。背景には木の枝と緑の葉があり、自然に囲まれています。レッサーパンダの特徴的な赤茶色の毛皮、白い模様、大きな耳がはっきりと見えます。
(3) 画像1枚での会話
User: <image>
Please describe the image in detail.
Assistant: The image shows a cute and adorable red panda resting on a wooden structure. The red panda has soft, reddish-brown fur with distinct white markings around its face. Its large, expressive eyes and small, rounded ears give it a curious and endearing look. It appears to be inside a wooden enclosure, nestled comfortably on a block of wood. The background displays green trees, indicating that the setting is likely a natural habitat or a well-maintained zoo environment.
User: Please write a poem according to the image.
Assistant: In twilight woods, where trees embrace,
A gentle soul with eyes so vast.
Red fur as warm as summer sun,
And white as morning dew, begun.
Eyes watch the world with curious grace,
A heart that's kind without a trace.
In woodland nestled soft and tight,
The red panda rests throughout the night.
Oh, keeper of the forest's peace,
With every step, love you release.
May your days be filled with joy and cheer,
Gently moving, year by year.
In forest green, you're home so dear,
Adventurous dreams will soon appear.
With every twist and every stride,
The red panda, sweet and wide.
翻訳。
ユーザー: <画像>
画像を詳しく説明してください。
アシスタント: この画像には、かわいくて愛らしいレッサーパンダが木の構造物の上に休んでいる様子が写っています。レッサーパンダは柔らかい赤茶色の毛皮で、顔の周りにははっきりとした白い模様があります。大きくて表情豊かな目と小さくて丸い耳が、好奇心旺盛で愛らしい表情をしています。レッサーパンダは木の囲いの中にいて、木のブロックの上に心地よく寄り添っているようです。背景には緑の木々が写っており、この環境は自然の生息地か、よく整備された動物園の環境である可能性が高いことを示しています。
ユーザー: 画像に合わせて詩を書いてください。
アシスタント: 木々が抱擁する夕暮れの森で、
とても広い目をした優しい魂。
夏の太陽のように暖かい赤い毛皮、
そして朝露のように白い毛皮が始まりました。
好奇心に満ちた優雅さで世界を見守る目、
痕跡のない優しい心。
柔らかくしっかりと寄り添う森の中で、
レッサーパンダは夜通し休んでいます。
ああ、森の平和の番人よ、
一歩ごとに、愛を解き放ちます。
あなたの日々が喜びと元気で満たされますように、
年々穏やかに進んでいきます。
森の緑の中で、あなたはとても愛しい家に帰り、
冒険的な夢がすぐに現れます。
ひねりを加え、一歩一歩、
レッサーパンダは優しく広い。
(4) 画像2枚を1枚に連結して会話

User: <image>
Describe the two images in detail.
Assistant: The image shows two adorable animals:
1. **Red Panda:**
- Located on top part of the image.
- Has a reddish-brown face with white ears and a white underbelly with black patches around eyes.
- Appears to be resting its arms on a wooden platform or structure.
- The background includes green foliage, suggesting an outdoor or natural environment.
2. **Panda:**
- Located in the lower part of the image.
- Shows a classic panda appearance with black and white fur.
- It is sitting among green bamboo plants.
- The background includes bamboo and other greenery, indicating a habitat that might be designed to mimic its natural environment.
User: What are the similarities and differences between these two images.
Assistant: Here are the observed similarities and differences between the two images:
### Similarities:
- **Animals**: Both images feature animals that are commonly associated with Asian and animal conservation settings.
- **Eyes and Fur**: Both animals have round, expressive eyes and distinct soft fur.
- **Environment**: Both appear to be in natural or semi-natural settings with green foliage in the background, suggesting that they live in a habitat designed to mimic their natural environment.
### Differences:
- **Species**:
- The animal on the top is a red panda.
- The animal on the bottom is a panda, specifically a giant panda.
- **Fur Patterns**:
- Red panda has reddish-brown fur with black patches around the eyes and white ears.
- Panda has mostly black fur with white patches around the eyes and face.
- **Location**:
- The red panda is positioned higher on a wooden structure.
- The panda is lower, sitting among bamboo plants.
- **Facial Characteristics**:
- The red panda’s face is predominantly reddish-brown, while the panda’s face is black.
- The panda has larger, darker patches around its eyes compared to the red panda.
- **Ear Color**:
- Red panda has white-tipped ears.
- Panda's ears are black.
- **Behavior**:
- Red panda appears to be resting its arms, possibly on a structure.
- Panda appears to be interacting or focusing on something amongst the bamboo foliage.
These differences highlight the unique characteristics of each animal and the environments they are presented in.
翻訳。
ユーザー: <画像>
2 つの画像を詳しく説明してください。
アシスタント: 画像には、2 匹の愛らしい動物が写っています。
1. **レッサーパンダ:**
- 画像の上部にあります。
- 赤みがかった茶色の顔に白い耳、白い下腹部、目の周りに黒い斑点があります。
- 木製の台または構造物に腕を置いているように見えます。
- 背景には緑の葉があり、屋外または自然環境を示唆しています。
2. **パンダ:**
- 画像の下部にあります。
- 黒と白の毛皮を持つ典型的なパンダの外観を示しています。
- 緑の竹の間に座っています。
- 背景には竹やその他の緑があり、自然環境を模倣するように設計された生息地である可能性があります。
ユーザー: これら 2 つの画像の類似点と相違点は何ですか。
アシスタント: 2 つの画像で観察された類似点と相違点は次のとおりです:
### 類似点:
- **動物**: 両方の画像には、アジアや動物保護の環境によく関連付けられる動物が写っています。
- **目と毛皮**: 両方の動物は丸くて表情豊かな目と独特の柔らかい毛皮を持っています。
- **環境**: どちらも、背景に緑の葉がある自然または半自然の環境にいるように見えます。これは、自然環境を模倣するように設計された生息地に住んでいることを示しています。
### 相違点:
- **種**:
- 上の動物はレッサーパンダです。
- 下の動物はパンダ、具体的にはジャイアントパンダです。
- **毛皮の模様**:
- レッサーパンダの毛皮は赤褐色で、目の周りに黒い斑点があり、耳は白です。
- パンダの毛皮はほとんどが黒で、目と顔の周りに白い斑点があります。
- **場所**:
- レッサーパンダは木造構造物の高い位置にあります。
- パンダは竹の間に座っており、低い位置にあります。
- **顔の特徴**:
- レッサーパンダの顔は主に赤茶色ですが、パンダの顔は黒です。
- パンダの目の周りの斑点は、レッサーパンダよりも大きくて暗いです。
- **耳の色**:
- レッサーパンダの耳の先は白です。
- パンダの耳は黒です。
- **行動**:
- レッサーパンダは腕を構造物の上に休めているように見えます。
- パンダは竹の葉の間で何かとやりとりをしているか、何かに集中しているように見えます。
これらの違いは、それぞれの動物のユニークな特徴と、それらが提示されている環境を際立たせています。
(5) 画像2枚を連結せずに会話
User: Image-1: <image>
Image-2: <image>
Describe the two images in detail.
Assistant: Image-1: A red panda with reddish-brown fur, a white face, and dark eyes is peeking over a wooden obstacle in an outdoor enclosure. The panda is leaning on the barrier with its front paws, showing a calm and attentive expression. The background includes green foliage and a tree trunk, suggesting a natural habitat or a wildlife sanctuary.
Image-2: A panda is seen sitting among green bamboo leaves in an outdoor enclosure, partially obscured by the leaves. The panda, with its distinctive black and white fur, is positioned near a wooden structure, and another panda can be seen slightly visible behind and to the left. The surrounding area is lush with greenery, creating a naturalistic environment for the animals.
User: What are the similarities and differences between these two images.
Assistant: same
翻訳。
ユーザー: 画像 1: <画像>
画像 2: <画像>
2 つの画像を詳しく説明してください。
アシスタント: 画像 1: 赤茶色の毛皮、白い顔、黒い目をしたレッサーパンダが、屋外の囲いにある木製の障害物から顔を覗かせています。パンダは前足で障害物に寄りかかっており、穏やかで注意深い表情を見せています。背景には緑の葉と木の幹があり、自然の生息地または野生動物保護区を示唆しています。
画像 2: パンダが屋外の囲いにある緑の竹の葉の間に座っていますが、葉に部分的に隠れています。黒と白の毛皮が特徴的なパンダは、木製の構造物の近くにいます。後ろと左側にもう 1 頭のパンダがかすかに見えます。周囲は緑が豊かで、動物にとって自然な環境を作り出しています。
ユーザー: この 2 つの画像の類似点と相違点は何ですか。
アシスタント: 同じです
同じではないと思うが…。
(6) バッチ推論、画像1枚ずつ
まずはレッサーパンダの画像から。
User: <image>
Describe the image in detail.
Assistant: This image features a close-up of a red panda, a mammal native to the eastern Himalayas and southwestern China. The red panda has distinctive, fluffy ears tipped in white, as well as reddish-brown fur on the back and white fur on the belly. Its facial features are accentuated by dark brown markings around its eyes and a small, round nose that contrasts with the white of its face. The panda is sitting on a wooden surface that appears to be part of an enclosure, possibly at a sanctuary or zoo. It is looking directly at the camera with large, expressive eyes, giving an impression of curiosity or alertness. The background includes green foliage, suggesting an outdoor setting or a habitat with natural elements.
ユーザー: <画像>
画像を詳しく説明してください。
アシスタント: この画像には、ヒマラヤ東部と中国南西部に生息する哺乳類、レッサーパンダのクローズアップが写っています。レッサーパンダは、先端が白く、ふわふわした特徴的な耳と、背中の毛が赤茶色、腹部の毛が白です。顔の特徴は、目の周りの暗褐色の模様と、顔の白さと対照的な小さくて丸い鼻によって強調されています。パンダは、おそらく保護区か動物園の囲いの一部であると思われる木製の表面に座っています。大きく表情豊かな目でカメラをまっすぐに見つめており、好奇心や警戒心があるように見えます。背景には緑の葉が含まれており、屋外の設定または自然の要素のある生息地を示唆しています。
続いて、パンダ。
User: <image>
Describe the image in detail.
Assistant: The image shows an adorable giant panda sitting amidst a collection of green bamboo leaves and plants. The panda has the characteristic black-and-white coloring: black patches on its ears, eyes, and around its mouth, and a white face with subtle black markings. The panda appears to be looking at something with interest, possibly chewing on or playing with the bamboo.
The background includes wooden structures that resemble either a platform or feeding area constructed to mimic the panda's natural habitat. The setting is lush with greenery, creating an environment that looks like a well-maintained bamboo grove. This image captures the panda in a relaxed, natural-seeming pose, surrounded by the plants typical in its diet.
ユーザー: <画像>
画像を詳しく説明してください。
アシスタント: この画像には、緑の竹の葉や植物に囲まれた愛らしいジャイアントパンダが写っています。パンダは特徴的な白黒の色合いをしており、耳、目、口の周りに黒い斑点があり、白い顔には微妙な黒い模様があります。パンダは何かに興味を持って見ているようで、竹を噛んだり、竹で遊んだりしているようです。
背景には、パンダの自然の生息地を模倣して作られたプラットフォームまたは餌場のような木製の構造物があります。背景は緑豊かで、手入れの行き届いた竹林のような環境を作り出しています。この画像では、パンダがリラックスした自然なポーズで、パンダの典型的な食事の植物に囲まれています。
(7) 動画での会話
User: Frame1: <image>
Frame2: <image>
Frame3: <image>
Frame4: <image>
Frame5: <image>
Frame6: <image>
Frame7: <image>
Frame8: <image>
What is the red panda doing?
Assistant: The red panda is hanging from the tree, standing on a branch, and eating a piece of food. In some frames, it appears to be holding a piece of food.
User: Describe this video in detail.
Assistant: The video captures the red pandas' behavior and movements. Red pandas are small mammal species related to raccoons and bears, known for their reddish-brown fur and long bushy tails. In the video, we see a red panda hanging from a tree, standing on a branch, and eating a piece of food. The animal's behavior in the video is typical, as it goes about its daily activities such as feeding and resting. The video is likely taken in a controlled environment, as red pandas are not commonly found in the wild. Overall, the video provides a glimpse into the daily lives of red pandas in captivity.
翻訳。
ユーザー: フレーム 1: <画像>
フレーム 2: <画像>
フレーム 3: <画像>
フレーム 4: <画像>
フレーム 5: <画像>
フレーム 6: <画像>
フレーム 7: <画像>
フレーム 8: <画像>
レッサーパンダは何をしていますか?
アシスタント: レッサーパンダは木からぶら下がって枝の上に立ち、食べ物を食べています。いくつかのフレームでは、食べ物を持っているように見えます。
ユーザー: この動画を詳しく説明してください。
アシスタント: この動画では、レッサーパンダの行動や動きが捉えられています。レッサーパンダは、アライグマやクマの仲間で、赤茶色の毛と長くふさふさした尻尾で知られる小型哺乳類です。動画では、レッサーパンダが木からぶら下がったり、枝に立ったり、食べ物を食べたりしています。動画でのレッサーパンダの行動は、餌を食べたり、休んだりといった日常の活動を行う典型的なものです。レッサーパンダは野生では一般的に見られないため、この動画は管理された環境で撮影されたと思われます。全体として、この動画は飼育されているレッサーパンダの日常生活を垣間見ることができます。
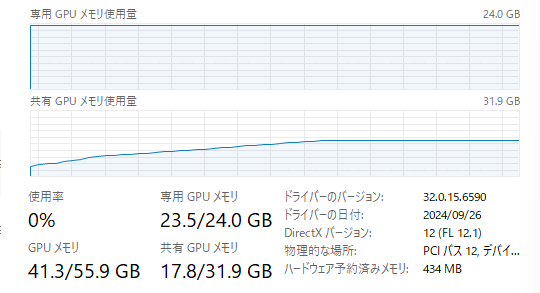
4. リソース使用状況
VRAM 24GBだと溢れてしまうようです。
処理の内容にも依りますが、40GB~50GB程の使用量になりました。