深層学習day3~day4(ラビットチャレンジ)

Section1) 再帰型ニューラルネットワークの概念
全体像
・時系列データ
- 時間的順序を追って、一定間隔ごとに観察され、相互に統計的依存関係が認められるようなデータ系列
> 音声データ
> テキストデータ
・RNNとは
- 基本的なモデルの構造は変わらず、時間的なつながりを持たせたもの
- 前の層の中間層からの出力を次の層の中間層に入力する
(前の中間層からの入力に対する重みが追加されている)
・確認テスト

⇒ 解答 : 前の層の中間層から現在の中間層を定義する際にかけられる重み
・RNNの特徴
- 初期状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造が必要
・演習チャレンジ(1:03)

⇒ 解答 : ②
・BPTT(Back Propagation Through Time)
・確認テスト

⇒ 解答 : dz/dx = 2(x + y)
・確認テスト

⇒ 解答 : Z1 = X1 x W_in + S0 x W + b0
Y1 = g(Z1 x W_out + b1) = g{(X1 x W_in + S0 x W + b0) x W_out + b1}
・コード演習問題(2:46)

⇒ 解答 : (2)
Section2) LSTM
全体像
・RNNの課題
- 時系列をさかのぼればさかのぼるほど、勾配が消失していく
> 長い時系列の学習が困難(中間層にシグモイド関数のように、微分値が0~1の間の値をとるものが多い場合、値が小さくなってしまう)
>> 構造を自体を変えて解決したものがLSTM
・確認テスト

⇒ 解答 : (2)
・勾配爆発
- 逆伝搬が増えるほど、指数関数的に大きくなっていくこと
-対策は勾配クリッピング
> 勾配のノルムがある量を超えたら、正規化してしまう
・演習チャレンジ

⇒ 解答 : (1)
・LSTMの全体像
- RNNの1種
- 真ん中にCECがある
・CEC
- 中間層で肝になる部分を抜き出したもの
- 中間層でのデータため込みの際に、勾配消失問題が起きる
- CECに過去の情報を覚えこませる(記憶することのみ)
- 勾配が1であれば、勾配消失・勾配爆発は怒らない
> そのためにCECを導入
> 覚えることしかしない、学習することはしない、覚えた結果を出すだけ
> ニューラルネットワークの学習特性がない
> CECの周りに取り巻きを置く
> 周りに学習機能を配置して、何を覚えてもらうか、それをどう使うかを考えた
入力ゲートと出力ゲート
・入力ゲート
- 入力情報と入力ゲートからの情報が掛け合わされてCECに渡す
- どんなふうにCECに覚えさせるかを学習する
- 今回の入力値と前回の出力値から今回の入力値をどうするか、どれぐらい覚えさせるか
・出力ゲート
- どんな風にCECの出力を使うかを学習する
忘却ゲート
・過去の情報が不要となった時に削除されずに保管され続ける
- 不要になった時に、そのタイミングで情報を忘却する必要あり
> 忘却ゲートの誕生
・確認テスト

⇒ 解答 : 忘却ゲート
・演習チャレンジ

⇒ 解答 : (3)
覗き穴結合
・CEC自身の値に重み行列を介して伝播可能にした構造
- あまり大きな効果は得られなかった
Section3) GRU
・LSTMはパラメータ数が多く、計算負荷が大きい
- パラメータを大幅に削減し、精度は同等以上が望めるようになった構造
- 計算負荷が低い
・CEC、入力ゲート、忘却ゲートがなくなる代わりに、リセットゲートと更新ゲートが登場
・隠れ層の状態をどのような状態で保持しておくかをリセットゲートで設定
・確認テスト

⇒ 解答
- LSTMはパラメータ数が多く、計算コストが大きい
- CECは覚えることのみで学習はしないため、CECの周りにその他の機能を配置する必要がある
・演習チャレンジ

⇒ 解答 : (4)
・確認テスト

⇒ 解答
- LSTMはCEC、入力ゲート、出力ゲート、忘却ゲートから構成され、多くのパラメータで時間をかけて学習するのに対して、GRUはリセットゲート、更新ゲートを持ち、LSTMよりもパラメータの少ない、シンプルなモデルとなっており、計算量が少なくなる。
Section4) 双方向RNN
・過去の情報だけでなく未来の情報を加味することで、精度を向上させるためのモデル(文章の推敲や機械翻訳等)
・演習チャレンジ

⇒ 解答 : (4)
Section5) Seq2seq
・2つのネットワークをドッキングしたもの
・文の意味を抽出して、文の意味を基に別の表現を得る
・encoder - Decorderモデルの一種
・機械対話や機械翻訳に使用されている
Encoder RNN
・テキストデータを単語等のトークンに区切る
・単語をone-hotベクトルにしてベクトル表現を得る(数万から数十万)
- ほとんどがゼロのため、もったいない
・embeddingでのベクトルの大きさは数百程度に抑え込む(機械学習を用いる)
- 単語が似通った場合には、似通ったベクトル表現になるように学習する(ただし、難しい)
- embedding表現を入力値としてとる
・final stateがそれまでの入力を記憶した、文脈ベクトル
・Masked Language Model(推論モデル)
- 似たような意味の単語が似通ったベクトル表現に自然と落ち着いていく
- 一文中の単語をランダムに落とすなどすれば、教師データとしてラベリングする必要もなく、大量にデータが得られる
- Googleが作ったBERTが有名
Decoder RNN
・システムがアウトプットデータを単語等のトークンごとに生成する構造
・一番最初に入ってくるのはEncoderからの出力(文の意味)で、一単語目を作成、その後は次々に次の単語を予測していく
・ベクトル表現から、どれが一番近い単語かを予測していく
・確認テスト

⇒ 解答 : (2)
・演習チャレンジ

⇒ 解答 : (1)
HRED
・Seq2seqの課題は一問一答しかできない(文脈もなく、応答するのみ)
・文の意味ベクトルをつないでいく(RNNの多重構造)
・過去のn-1個の発話から次の発話を生成する
・前の単語の流れに即して応答されるため、より人間らしい文章になる
・Seq2seq + Context RNN(Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造)
⇒ 過去の発話の履歴を加味した返答が可能
・課題は以下
- 多様性がない(短く情報量に乏しい答えをしがちである)
- 短く、よくある答えを学ぶ傾向がある(「うん」、「そうだね」)
VHRED
・HREDにVAEの潜在変数の概念を追加したもの
- それにより、HREDの課題を解決
・確認テスト

⇒ 解答
- seq2seq : 一問一答しか対応できない
- HRED : 過去の文章の意味ベクトルを記憶して、文脈に沿った対応ができるが、多様性がない解答になりがち
- VHRED : VAEの概念を導入して、回答に多様性を持たせることができる
オートエンコーダ
・教師無し学習の一つ
- 訓練データのみで教師データは不要
・次元削減が可能
・入力と出力が同じになるように学習する
・VAE(Valuational Auto Encoder)
- 中間層の潜在変数zに確率分布を仮定したもの
- 元のデータが近ければ、同じようなベクトル表現になってほしいが、何も指定しないと、全く異なるベクトル表現になる可能性がある(デコーダーの入力にランダム性を持たせる(ノイズを加える))
> ノイズ付きのデータに対しても同じ出力を出すように学習するので、汎用的な出力になる
・確認テスト

⇒ 確率変数
word2vec
・単語をベクトル表現にする手法(embedding表現を得る手法)
・変換するときの変換表を学習する
Attention Mechanism
・seq2seqは長い文章に対して対応できない
・入力と出力のどの単語が関連しているのかの関連度を学習する仕組み
- 文章が長くなっても重要な情報のみをピックアップできる
- 近年のモデルはほとんどこれを用いている
・確認テスト

⇒ 解答
- RNN : 時系列データの処理に用いる
- word2vec : 単語をベクトルに表現する手法
- seq2seq : 2つの時系列データをドッキングしたもの
- Attention : 入力と出力のどの単語が関連しているのかの関連度を学習する仕組み
【強化学習】
・教師あり学習、教師無し学習は人間が成長する過程で自然に学んでいくプロセスと同じなのに対して、強化学習は人間が仕事で成果を出していくプロセスと同じ
⇒ AIを活用して何らかのタスクを実行したいはずなので、この分野が注目されている。
・探索と利用のトレードオフ
・これまでホワイトカラーがやっていたこと
- 経験や思い付きが必要
- 新たな人材育成が不要
・Q学習と関数近似法が理論的には大切
・目標設定に当たるものが価値
- 状態価値関数 : 環境の状態が価値を変えるもの(盤面の並びの状態だけ)
- 行動価値関数 : 状態と行動を基に価値が決まる(盤面の状態の中でどういう一手を置くか)
・方策関数
- 方策関数の結果に基づいて、エージェントは行動する
・方策勾配法
重みとしてθを取る
・NNの誤差関数を減らしていくのに対して、強化学習では期待収益増やしていく
【Section2 : Alpha Go】
・2種類ある
- AlphaGo Lee
- AlphaGo Zero
・AlphaGo Lee
- 方策関数 : PolicyNet
> 19 x 19 x 48
> 19 x 19でどこに次の一手を打つのが最も良いかが出力として出てくる
- 行動価値関数 : Value Net
> 19 x 19 x 49
> 現局面の勝率を-1~1で表したものが出力
・2次元の場合はConvolutionするしかない(定石)
最後が1次元なら全結合するしかない
・いきなり強化学習をやってもうまくいかないので、最初は教師あり学習をやる
・次の一手を考えるのに、3ミリ秒かかるが、何億回もやろうとすると結構なボリュームになる
⇒ 精度は落ちるがスピード重視
⇒ RollOutPolicy(NNではなく、線形の方策関数)
⇒ 3マイクロ秒/1手でできる
・教師あり学習において、RollOutPolicyを用いる
・3000万局面分の人間の手を学習させる(57%)
・モンテカルロ木探索
⇒ 価値関数を学習させるときに用いる
・AlphaGo Zero
- 強化学習のみで作成
- ヒューリスティックな要素を排除
- PolicyNetとValueNetを統合(枝分かれ構造)
- Residual Netを導入
- モンテカルロ木探索からRollOutシミュレーションをなくした
・ネットワークが深くなる ⇒ 潜在的に勾配消失(勾配爆発)問題が発生
⇒ ショートカットを入れてやる
⇒ いろいろなパターンのネットワークを模擬できる(アンサンブル効果)
・E資格では、モデルの特徴が良く出る
・現代の深層学習モデルでの根本的なネットワーク構造は、以下4つ
- 畳み込み
- プーリング
- RNN
- Attention
残りはこれらの組み合わせ
【Section3 軽量化・高速化技術】
・モデルを以下に速く学習するか??(3-1~3-3)
・スマホでもモデルを動かせるようにしよう(3-4~3-6)
・分散深層学習(最も大切な技術)
- ノートパソコンを複数台準備して、並列に学習させるイメージ。またはCPUの数を増やす。
- 毎年10倍の勢いで計算量が増えている(18ヶ月で2倍の高性能なコンピュータ(ムーアの法則))
- コンピュータ(ワーカー)を増やす、CPUを増やす、GPU, TPUを使う、夜間の充電中のスマホを使う・・・
・データ並列化
- 親モデルを子モデルにコピーして、子モデルたちの勾配の平均値でパラメータを更新し、再度コピーする
(同期型 : 各ワーカーが計算が終わるのを待つ、
非同期型 : 各ワーカーはお互いの計算完了を待たない代わりに、パラメータサーバーに順次結果を入れていく)
- 非同期型の方が処理は速いが、細心のパラメータを用いていないので、学習が不安定になりやすい
- 同期型か非同期型かは使い方による
(スマホのケースは非同期、自分たちでコントロールできるなら同期)
・モデル並列化
- 枝分かれ分割が主流
- 1台のPCで4つのGPUを接続して、みたいな使い方が多い
- データを集める際、ネットワーク経由だと遅い
- モデルが大きい ⇒ モデル並列化
- データが大きい ⇒ データ並列化
- 大きなモデルの方が、並列化の効果が高い(Google, 2016, Large Scale Distributed Deep Networks)
- 並列化による計算の効率化と分割したデータを集める時間のトレードオフ
- モデルの大きさはパラメータの数で示す
・GPUによる高速化
- CPU : 少数精鋭主義、1, 2人のイメージ、2秒/1画像
- GPU : 簡単な(行列計算)並列処理が得意、200-300人のイメージ、0.5秒/1画像
- GPGPU
> CUDA(NVIDIA)
> Open CL(あまり使われていない)
・量子化
- 計算は速く、省メモリ化が可能となるが精度は低下する
- 目盛を多く使う原因は重み(パラメータ)の情報(BERTだと数十億個)
- 2 Byte(半精度)、4 Byte(単精度)、16 Byte(倍精度)
- 64bitで量子化 ⇒ メモリが4GB、32bitで量子化 ⇒ メモリが2GB
- 前半5bitで整数の表現、後半11bitで小数の表現
- 大きなbit数で細かい数字まで表現できる
- 何ビットで表現するかが量子化の程度
- 16bitで150FLOPS程度
- 半精度でわりと十分
- 8 bitの小数は現在使われていない
・蒸留
- 精度が高いモデルをまず作って、その後軽量なモデルを作る
- 教師モデル(学習済み)と生徒モデル
・プルーニング
- 寄与の少ないニューロンを削減して、軽量化
- 重みが閾値以下のニューロンを削減し、再学習
- 意外と性能が変わらない
・Batch Normalizatiion
- ミニバッチ単位で正規化する(平均が0、分散が1)
> バッチサイズに影響を受ける
> あまり使いたくない
>> 学習時のハードウェア性能によって、ミニバッチのサイズを変えざるを得ないため
>> 再現性に欠ける??
・Layer Normalization
- TPUだと画像100枚ぐらいがミニバッチの上限
- CPUだと数十枚程度??
- 統計的に正しいのはミニバッチだが、レイヤーでもうまくいった
- 入力データのスケール、重み行列のスケールやシフトに対してロバスト
- 正規化はデータの特徴をそろえるイメージ
【Section4 応用技術】
・ネットワークに関する問題(特徴)がよく出る
(シラバスに載っている)
・画像認識モデルは2017年頃に完成していて、その後は軽くて精度の良いものが研究されている
・MobileNet
- 一般的な畳み込みレイヤーでの計算量が多いため、削減したい
(H x W x K x K x C x M)
- Depthwise Convolution
> フィルタ数は1
> 1つのチャンネルに対して、1枚のフィルタで畳み込みを実施
(H x W x K x K x C x 1)
- Pointwise Convolution
> カーネルサイズを1 x 1にして、複数のフィルタで畳み込みを実施
(H x W x 1 x 1 x C x M)
・DenseNet
- 画像認識のモデル
- Denseブロックが特徴
> Batch正規化
> Relu
> 3 x 3の畳み込み
- 1層通過するごとにkずつチャンネルが増えていく
(k : ネットワークのGrowth Rate)
- チャンネル数が増え過ぎないようにTransitiion Layerがある
- ResNetのSkip Connectionとの違い
> ResNetは前の層から結合に対して、
> ハイパーパラメータ k : Growth Rate(成長率)
・WaveNet
- 音声生成モデル(RNNではなくCNN)
(時系列データに対して、畳み込みを適用)
- とびとびに畳み込み処理をやっていける
(幅広い範囲のデータを得ながら、出力を一定レベルに保てる)
- Dilated casual convolution
- パラメータに対する受容野が広い
・逆畳み込み演算
- 解像度を上げる時など
【Seq2seq】
・Bert : Transformerが複数入ったもの
・Seq2seq : Sequence to Sequence(系列、日本語から英語)
- RNN
> 系列情報は順番が重要
> 最終的に内部状態ベクトルを出力する
- 言語モデル
> 単語の並びに対して、事後確率最大を計算する
> 決定的 : 0か1か ⇔ 確率分布
> Start of sentence
> 言語の自然な並び方を学習する
- RNNが2つ連結したもの
> 1つ目がエンコーダ、2つ目がデコーダ
内部状態ベクトルを出力することエンコード
デコーダは生成モデル
両者の違いは初期値としてhが与えられるかどうか
> デコーダのアウトプットに正解を与えれば、教師あり学習がend2endで行える
> Googleの翻訳システムもRNNベースで、何層にもしたもの
- Teacher Forcing
> 正解ラベルを直接デコーダの入力にする
訓練とテストで状態が異なるので、テスト結果が悪い可能性がある
【Transformer】
・seq2seqの弱点
- 長い文章に弱い、表現力が足りなくなる
> 翻訳元の文章を一つのベクトル表現にしてしまうため。
・合計1となる重み付けで単語同士の関連付け
・対応関係において注意を払うべき対象を絞る
・LSTMに次ぐ、次世代のユニットと言われている
- RNNを使わない、Attentionだけ
・重要なモジュール4つ
1. 位置情報を付加
2. Attention機構
3. フィードフォワードで全結合層に流す
4. 未来の単語を見ないようにマスク
・注意機構には2種類
- ソース・ターゲット注意機構
> 受け取った情報に対して狙うべき、近い情報のみに注意
- 自己注意機構
> CNNの考え方に似ていて、周辺情報全ても考慮されるイメージ(文脈を反映した表現が得られる)
・フィードフォワードネットワーク
- 位置情報を保持したまま順伝播させるような全結合層
・マルチヘッドアテンション
- 8つに分けて、アンサンブル学習のイメージ
・デコーダ
- セルフアテンションとソース・ターゲットアテンションの両方が使われている
・Add
- 入出力の差分を学習させる
- 学習、テストエラーの提言
・Norm
- バッチ正規化
物体検知・セグメンテーション
・物体検知、意味領域分割、個体領域分割では物体が映っている位置にも注目
【代表的データセット】
・VOC12(Visual Object Classes)
- クラス 20、Train + Val 11,540, Box/画像 2.4
・ILSVRC17(ImageNet Scale Visual Recognition Challenge)
- Instance Annotation(物体個々へのラベリング)が与えられていない
- クラス 200、Train + Val 476,668、Box/画像 1.1
- コンペは2017に終了
・MS COCO18(Common Object in Context)
- クラス 80、Train + Val 123,287、Box/画像 7.3
・OICOD18(Open Images Challenge Object Detection)
- クラス 500、Train + Val 1,743,042、Box/画像 7.0
- 一様な画像サイズではない
・Box/画像が小さい ⇒ アイコン的な映り、日常とはかけ離れている
・Box/画像が大きい ⇒ 部分的な重なりあり、日常生活のコンテキストに近い
・クラス数とBox/画像の2軸でデータセットを分類
- 目的に応じたBox/画像を用いる
- クラス数が大きければよいとは限らない
> 同じものが異なるラベルになっているが故にクラス数が増えている可能性もある
評価指標
・クラス分類の場合、Threshold(閾値)が変わってもConfusion Matrixに入る数は変わらない
・物体検出の場合、Thresholdが変わるとConfusion Matrixに入ってくる数も変化する
・IoU(Intersection over Union)
- クラスラベルだけでなく、物体一の予測精度も評価したい
- Jaccard係数
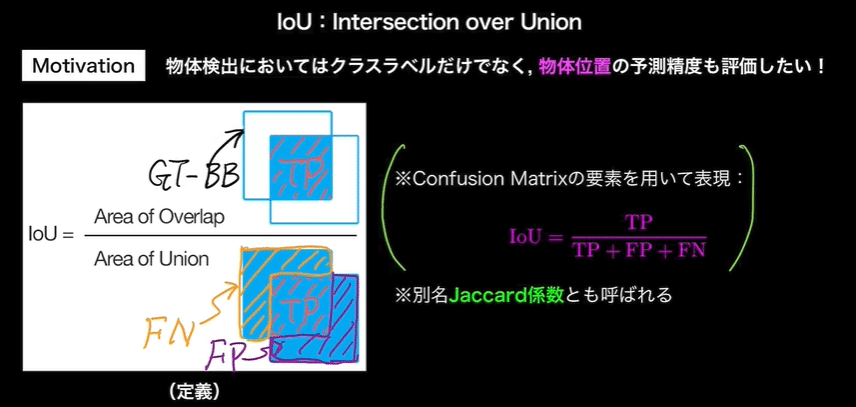
・IoUに対しても閾値を用意する
・同じ物体に対して、複数のBBで予測してしまった場合は、最も値の高いもののみを残す
・AP(Average Precision)
- Confidenceの閾値を0~1で変えて、積分する
・mAP(mean Average Precision)
- 各物体に対してAPを計算し、それらの平均をとってmAPとする
・IoU閾値も0.5から0.95までの0.05刻みでAP, mAPを計算し、算術平均を計算(MS COCOで導入された指標 mAP_COCO)
・FPS(Flames per Second)
- 応用上の要請から、検出精度に加えて検出速度も問題となる
物体検知の大枠(SIFTからDCNNへ)
・2段階検出(検出後、切り出して推論)
- 候補領域の検出と暮らす推定を別々に実施する
- 相対的に精度が高い
- 計算量が大きく推論も遅い
・1段階検出
- 同時に行う
- 精度が低い
- 計算量が小さく推論も早い
SSD(Single Shot Detector)
・流れ
1. Default Boxを用意
2. Default Boxを変形し、Confidenceを出力
・VGG16はSSDのベース(全結合層とConvolution層で16層)
- 最後の3層の全結合層の内、2層がConvolution層になっている
- 最後の全結合層は削除
- マルチスケール特徴マップ
・特徴マップからの出力
- 1つのDefault Boxからの出力はクラス + 4(位置)
- k個のDefault Boxからはk(クラス + 4)
- 特徴マップのサイズがm x nの場合、kmn(クラス + 4)
・物理的なサイズと解像度を混同しないようにする
- 物理的なサイズが変わるのではなく、特徴マップサイズが小さくなると解像度が荒くなっている
・多数のDefualt Boxによる問題
- Non-Maximum Suppression
> 1つの物体のみ映っていても、複数のPredicted BBが出てしまう
>> IoUが閾値以上で、Confidenceが最も大きなもののみを残す
- Hard Negative Mining
> 背景ばかりになってしまう
>> 背景と非背景の比を一定に保つ
・DSSDはResNetをベースにしている
Semantic Segmentation
・Conv. + Poolingで解像度が落ちていく
- Semantic Segmentationでは入力画像と同じサイズの画像の各ピクセルに対して、クラス分類が行われる
> 落ちた解像度をどのようにして元の入力画像サイズまで戻すのか
> アップサンプリングと呼ぶ
・Poolingしなければよいのでは??
- 正しく認識するためには受容野にある程度の大きさが必要
(一部だけを見せられてもわからない)
> 深いConv.層
>> 多層化に伴い、計算量が増える
> プーリング(ストライド)
・VGG16の全結合層3層をConv.層に変えている
- ヒートマップのようなものが出力される
・Deconvolution/Transposed convolution
- 特徴マップの間隔を空けて、パディングで余白を作ってサイズを大きくしてから、畳み込みでアップサンプリングする
- Poolingで失われた情報が復元されるわけではない
・低レイヤーのPooling層の出力をelement-wiseに足す
- U-Netが代表的
・Unpooling
- poolingした時の位置情報を保持しておく
・Dilated Convolution
- Conv.の段階で受容野を広げる工夫
実装演習
【3_1_simple_RNN_after.ipynb】
・バイナリ加算のRNNのプログラムを実装
・学習が進むにつれて、誤差が小さくなり、加算の結果を正しく予測できていることを確認
- 初期状態

- 初期値変更(He)
> 初期値の変更により早い段階で誤差が小さくなっていることを確認

- ReLU関数を適用
> 勾配爆発を確認

【3_3_predicted_sin.ipynb】
・sinカーブの計算

- Iter = 100に変更

【4_3_keras_codes_after.ipynb】
・kerasを用いて、以下のプログラムを実装
- 線形回帰、単純パーセプトロン、分類(iris)、分類(mnist)、CNN分類(mnist)、cifar10、RNN
- 線形回帰(代表例)
