
ニューラルネットワーク・モデリングの弱点とその回避~スパースモデリング

人工ニューラルネットワーク(ANN)はある意味万能な機械学習システムですが、その表現力の豊かさを持つ反面、機械学習一般で問題となる「過学習」の弱点があります。
「過学習」は、学習に用いたデータ固有の特徴を学習したために、一般的なテストデータに対して性能が大幅に下落する問題です。条件によっては、単純な線形回帰モデルの方が相対的に優れた性能を示すこともあります。

従って、機械学習の最大のテーマは「過学習をいかに回避して、汎化性能の高いモデルを獲得するか」という問題に尽きます。
一般に過学習のリスクは、学習サンプル数が説明変数よりも多くなる(“ビッグデータ”領域)と発生しにくくなります。
この場合には、十分な中間層を定義することで、人間が手を加える必要なく入力データからの特徴量をニューラルネットワーク自身が獲得することが可能となります。

一方、学習サンプル数が説明変数より同程度か少ないような状況(“スモールデータ”領域)では、ノイズの影響を受けて過学習になりやすくなります。業務が最適化されている場合、異常データは正常データに対して頻度がわずかとなり、全体として大量データが利用できたとしても、業務上価値ある異常データの識別問題は“スモールデータ”領域の問題となります。
“スモールデータ”領域における過学習の回避は、利用可能な入力変数から有効な変数を抜き出す「スパースモデリング」が有効と考えられています[1][2]。
スパースモデリングとは、スパース性の仮説:「複雑な自然科学的現象や経済現象(消費者の購買行動など)も、本質的に少数の因子によって良く記述できる」を受け入れ、必要最小限の変数でモデルを探索することを意味しています((例)金属電子論における有効質量をもつ自由電子モデル)。
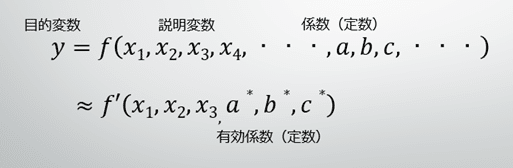
弊社が取り扱うニューラルワークス製品のPredict/NeuralSightでは、スパースモデリングを実現するための複数の仕組み(データ分布の一様化変換、L0/L2正則化、ネットワーク探索におけるカスケードコリレーション法[3]の採用)が組み込まれており、ANNの最適な設計の負担が大きく軽減されています[4]。

なお、教師データが得られない(検査データで不良データが利用できない)、あるいは圧倒的に少ない状況では、回帰モデルによる問題解決ではなく、文字通り教師無し学習での問題解決を図ることを考えてください。
[1] 大関真之 (2015) 『今日からできるスパースモデリング』 大阪市立大学特別講義
[2] 弘川奨悟、田口茂樹、松下康弘、足立吉隆, DP鋼の応力―ひずみ曲線を支配する組織因子のスパース学習, 日本鉄鋼協会/鉄と鋼, 103 巻 (2017) 8 号 p. 468-474
[3]S. E. Fahlman and C. Lebiere. The cascade correlation learning architecture.
In D. Touretzky, editor, Advances in Neural Information Processing Systems,
volume 2, pages 524 532. Morgan Kaufman, 1990.
[4] ニューラルワークス Predict ユーザーガイド
弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。
社内セミナーの企画等、お気軽にご相談いただければ幸いです。