
Predictによるクレジットカード与信分析

1.はじめに
ニューラルネットワークが、リスクマネージメントにも役立つ事例をご紹介します。
例えばクレジットカードの場合、入会申込をされたお客様に対し、審査のうえ利用限度額を設定することを与信といいます。しかし与信後、お客様の信用状況が悪くなった場合は、いったいどうなるでしょう?債務不履行、つまり支払えなくなるリスクが発生してきます。このリスクを未然に防ぐことは、クレジットカード会社にとって必要不可欠なことなのです。
そこで今回は、顧客属性として「性別」「婚姻」「年齢」「子供数」「勤務月数」「年収」「教育程度」のデータを用いて、延滞または完済の分析をしてみます。
「性別」「婚姻」「教育程度」は、定性的データ。「年齢」「子供数」「勤務月数」「年収」は、定量的データとなっています。
表1は、使用するデモ・データの一部です。トータルのデータ数は71件です。そのうち延滞件数は11件、完済件数は60件となっています。
まずニューラルネットワークの説明を簡単にしておきましょう。
ニューラルネットワークとは、人間の脳の神経結合を模倣した分析手法です。人間が学習して学んでいくように、ニューラルネットワークもデータから学習して答えを返してくれるのです。線形・非線形を問わず、これからのデータマイニングの分野で最も期待される分析手法の一つです。
ここではソフトウェアとして「ニューラルワークスPredict」を用いて分析手法を解説していきます。
2. ニューラルネットワークのモデルを作成する。
手 順
1.分析したいExcelファイルを開いておきます。
2.メニュー「Predict」→「新規」をクリックします(図1)。
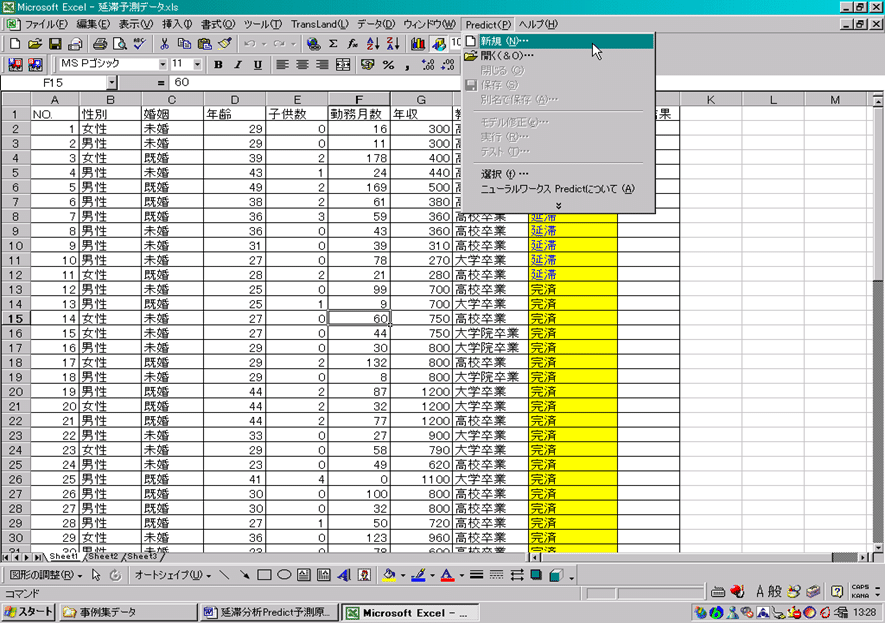
「新しいモデル」分析のタイプを選択します。この事例では、クレジット決済金額の「延滞」か「完済」かの判別を行うので、「データを分類する」を選択します(図2)。

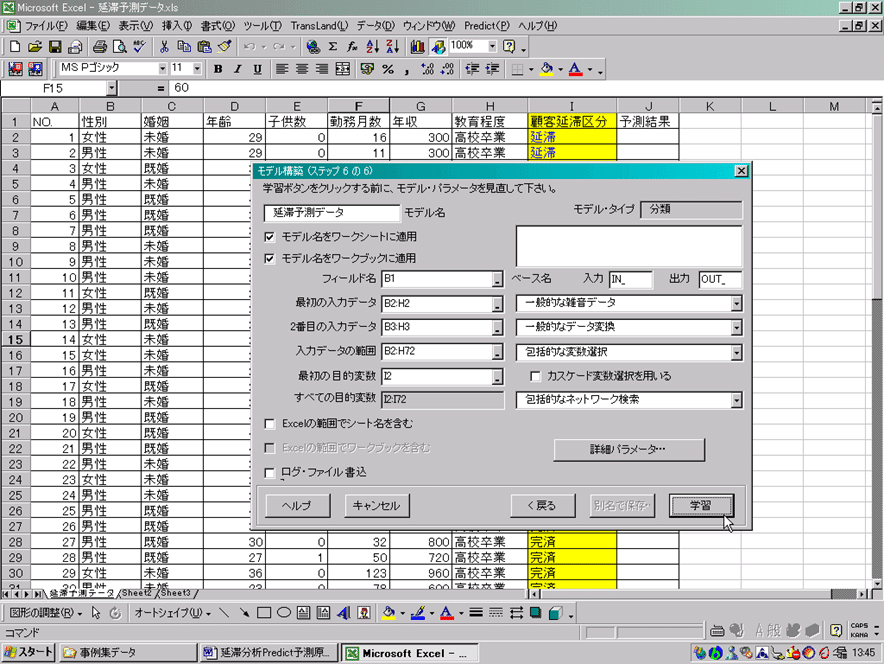
「モデル構築」ダイアログボックスが表示されます。以下の通り指定して、「学習」ボタンをクリックします(図3)。
・ 「モデル名」を“延滞予測データ”とします。
・ 「ワークシートに適用」/「ワークブックに適用」をオンにします。
・ 「フィールド名」B1とします。
・ 「最初の入力データ」に1番目の入力データの範囲(B2:H2)を指定します。
・ 「2番目の入力データ」に2番目の入力データの範囲(B3:H3)を指定します。
・ 「入力データの範囲」にすべての入力データのセル範囲(B2:H72)を指定します。
・ 「最初の目的変数」に1番目の出力データのセル範囲の先頭を指定します。ここでは「顧客延滞区分」項目の第1番目であるセルI2を指定します。
・ 「雑音レベル」でノイズ(雑音)のレベルを選択します。ここではデフォルトの 「一般的な雑音データ」を選びます。
・ 「変数選択レベル」で変数選択のレベルを指定します。ここではデフォルトの 「包括的な変数選択」を選びます。
・ 「最適化レベル」でモデルの最適化のレベルを指定します。ここではデフォルトの 「包括的なネットワーク検索」を選びます。
「学習」ボタンをクリックしたらたら、保存ダイアログ画面が表示されます。名前 (この事例の場合、「延滞予測データ」と名づけました)を付けて「保存」をクリックします。この時拡張子npr(NeuralWorks Predict)が自動的に付加されます。この後自動的モデル作成が実行され完了画面が表示されます。(図4)

これで、モデル作成が完了しました。
3.作成したモデルを使って予測する。
実際の入出力データを使って学習したネットワークモデルが完成しました。このモデルを使って、予測を行ってみましょう。
1.メニュー「Predict」-「実行」をクリックします(図5) 。

次のダイアログボックスで、予測に使用する入力データのセル範囲を設定します。ここではすべての入力データに対する予測値を求めてみましょう。(図6)
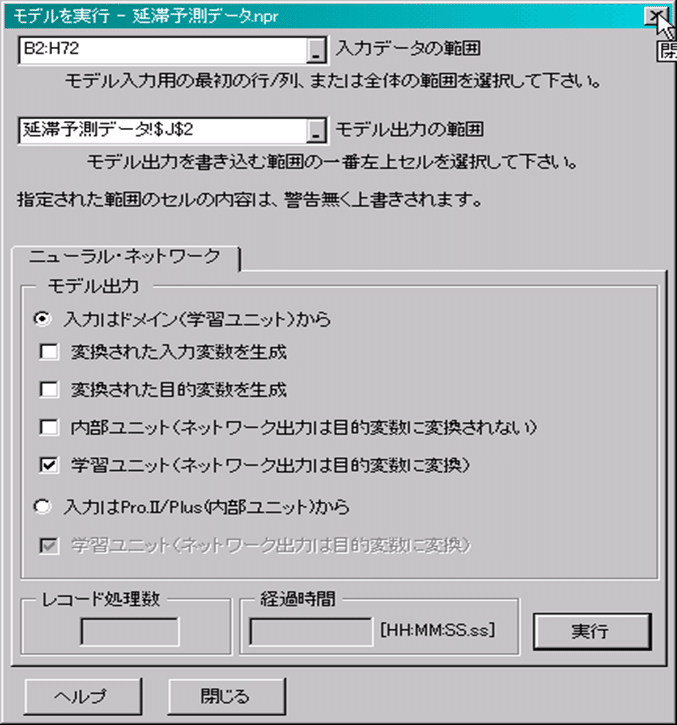
・ 「入力データの範囲」を(B2:H72)と入力します。
・ 「出力データの範囲」を予測値を出力するセル範囲の先頭セルを指定します。ここでは、「予測結果」の列に出力するため、セルJ2を指定します。
「実行ボタン」をクリックすると予測値が出力されました。この画面上のデータに対しては、すべて正しく判別されていることがわかります(図7)。

ではここでニューラルネットワークを使って、どれくらいの精度で予測できているのかを確認するために、PredictのTestコマンドを利用します。この機能を使うことによって、トータルとしてのモデルの性能を知ることができます。さっそくモデルの性能に関するレポートを出力してみましょう。
手順
1.メニュー「Predict」-「テスト」をクリックします(図8)。

次のダイアログボックスで、結果出力範囲およびテストを行いたいデータ区分を指定して、「テスト」をクリックします(図9)。
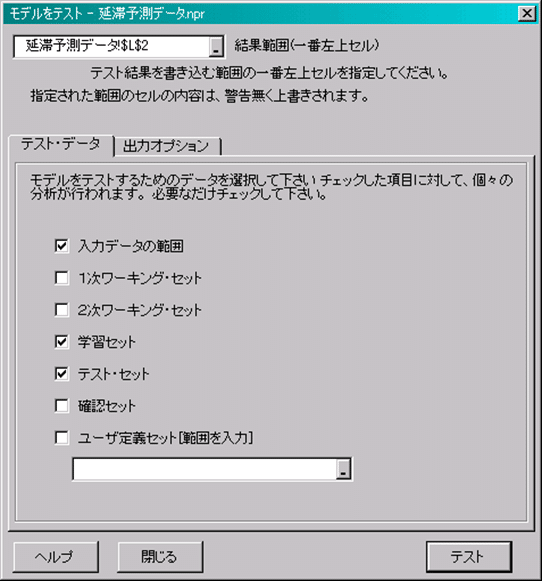
表2がTest実行結果の出力です。

★Accuracy:判別結果の精度を表します。数値が1に近いほど、モデルの性能が良いことになります。
★Rel. Entropy:モデルの当てはまり具合を表します。0に近いほど、モデルの入力データへの当てはまり具合が良いことを示します。
★Total:トータルのデータ件数です。
また、All、Train、Testはデータ区分を表し、Trainは学習用、Testはテスト用のデータセットで、AllはTrainとTestのデータセットを合わせたものです。TrainとTestのデータは、ランダムに全体の70%と30%(デフォルト)の割合で選ばれます。
Allの行を見ると、Accuracy=1、Rel.Entropy=0.00084344 、Total=71となっています。これは、正判別率が100%(71件中71件)、Rel.Entropyは0.084%と限りなく0に近い値になっており、あてはまり具合がよいことを表しています。
TrainとTestでも、ほぼ同じ傾向が見られます。
4.新しいデータに対する予測を行う。
新しく追加されたデータに対する予測を行ってみましょう(図10)。
図10のNO.72~74に3人のデータがあります。はたしてこの3人は延滞なく支払うことができるのでしょうか?
手順を説明します。

手順
1.メニュー「Predict」-「実行」をクリックします。(図11)
2.「入力データの範囲」で新しいデータのセル範囲(B73:H75)を指定します。
3.「モデル出力の範囲」で、予測値を出力するセル範囲の先頭(セルJ73)を指定します。
4.図12のように新しく追加されたデータに対する予測値が出力されます。

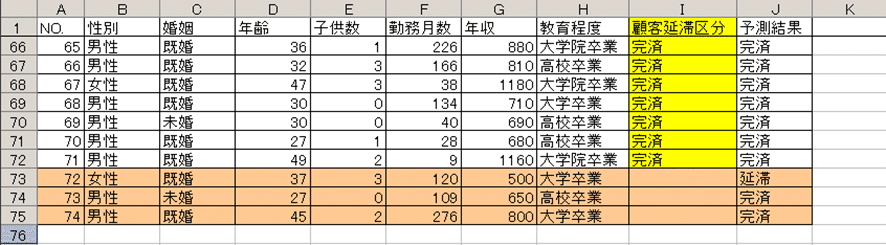
ご覧のように、NO.72の女性の属性からは、「延滞する」と予測されます。
NO.73と74の男性の属性からは「完済する」と予測されました。
クレジットカードについては与信枠が大きくなれば当然利用可能額も大きくなり、リスクは拡大する可能性があります。カード会社としては利用状況、支払い状況で何か異常があれば、利用残高の増大を防止する次のアクションを早急に取る必要が出てきます。
こ のように過去のデータに基づいて、新しいデータに対して予測ができるということは、かなり有益な判断材料となることはいうまでもありません。
リスクマネージメントは、的確な判断をスピーディに行う必要があり、ニューラルネットワークなら高度な専門知識がなくても複雑なデータの予測も簡単に分析できるので、かなり有効なツールといえます。
弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。
社内セミナーの企画等、お気軽にご相談いただければ幸いです。