
Predictを用いてダイレクトメールのレスポンスを予測する

はじめに
ニューラルネットワークは人間の脳の活動を模倣した情報処理手法です。線形、非線形を問わず幅広い応用範囲があり、また煩雑な前処理も必要なく分析作業が容易に行えることなどから、今後のデータマイニングの主役になるものと期待されています。
ここでは、ソフトウェアとして「ニューラルワークス Predict」を用い、「ダイレクトメールのレスポンスの予測」の事例を通して、「ニューラルネットワークによるデータマイニング」の方法についてご紹介します。
■ ニューラルワークス Predict
Excelのアドインとして組み込まれ、データの準備から結果の出力やグラフ化が簡単に行えます。高度な知識がなくても容易に使いこなせる画期的な分析ツールです。NeuralWorks Predictをインストールすると、Excelのメニューバーに「Predict」メニューが表示されます。
■ 事例
取り上げた事例は定量的なデータは全く含まれておらず、説明変数、被説明変数とも、定性的なデータです。数量化理論Ⅱ類モデルといわれるものです。
ニューラルワークス Predictを使えば、このようなモデルも容易に分析することができます。
データを準備する
ある会員制通信販売会社におけるダイレクトメールのレスポンスの分析をニューラルネットワークで行います。表1が使用するデータの一部です。全部で210件のデータがあります。
会員を職業、性別、年齢、地域、年収の5アイテムで層別化し、それぞれに対するダイレクトメールのレスポンスの有無を調査したものです。
各列の内容は次のとおりです。
<項目(カテゴリ数)> <カテゴリ>
職業(3) :自営業、会社員、公務員
性別(2):男、女
年齢(2):45歳未満、45歳以上
地域(10):北海道、東北、北陸、関東、中部、関西、中国、四国、九州、沖縄
年収(3):多い、普通、少ない
レスポンス(2) :有り(○)、無し(×)
210件のうち、レスポンス有り(○)が114件、レスポンス無し(×)が
96件でした。

ニューラルネットワークモデルを作成する
1.最初に、試用版に付属するExcelファイル「ダイレクトメール.xls」を開きます。
2.メニュー「Predict」-「新規」をクリックします。
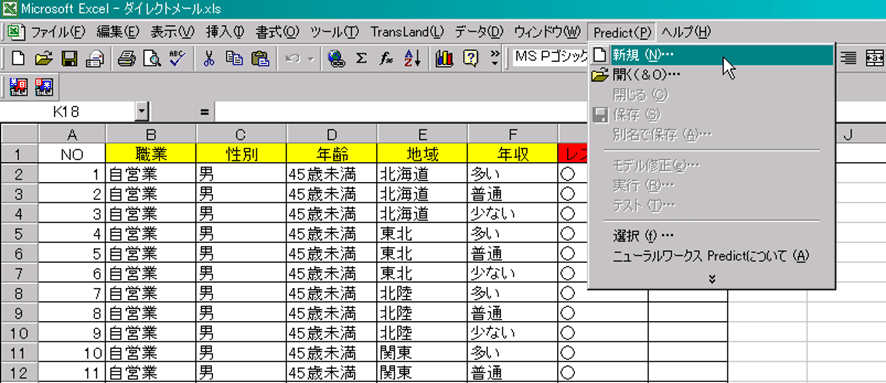
3.次に、ニューラルネットワークモデルそのものについての設定を行います。これ以降順次表示されるダイアログボックスで、メッセージ通りに入力して「次へ」ボタンをクリックします。
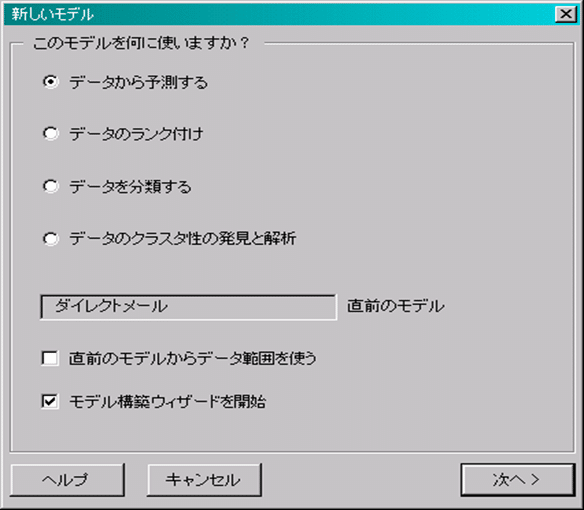
■「モデルのタイプ」で分析のタイプを選択します。この事例では、ダイレクトメールのレスポンス有無の判別を行うので、「データから予測する」を選択します。
■ 「直前のモデルからデータ範囲を行う」チェックは新規作成のためOFFにする。
■ 「モデル構築ウィザード」チェックはONにする。

■ 「次へ」をクリックする。
4.モデル構築画面(ステップ1/6)を入力します。
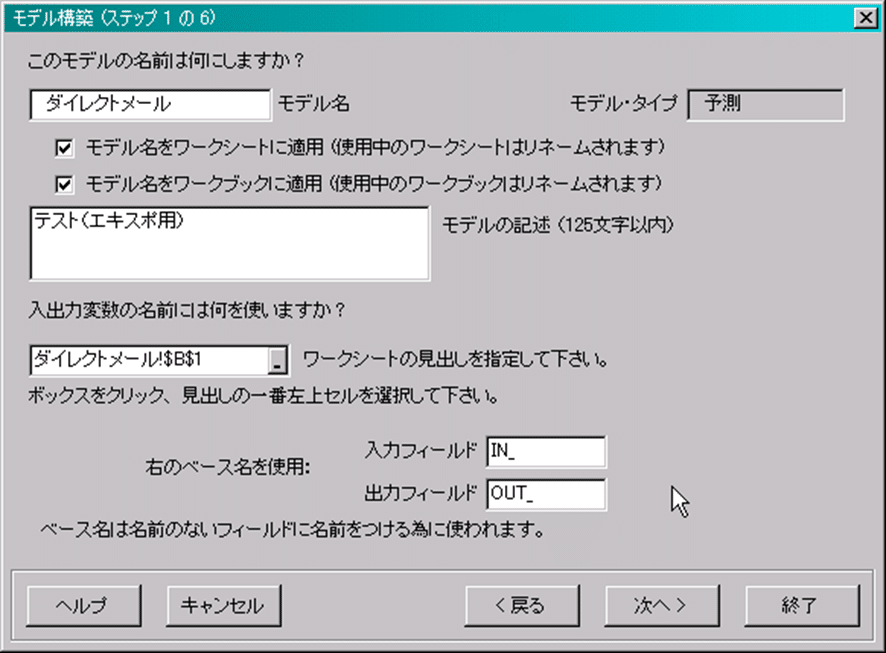
■ 「モデル名」を入力する
■ 「モデル・タイプ」は「図3-1 新しいモデルの指定」で指定されたタイプが表示される
■ 「モデル名をワークシートに適用」をチェックするとエクセルのワークシート名がモデル名になります。
■ 「モデル名をワークブックに適用」をチェックするとエクセルのブック名がモデル名になります。
■ 「モデルの記述」に入力する(125文字以内)。
■ 「入出力変数の名前」をコメントの通り指定する。(ここでは$B$1となる)
■ 「入出力フィールドの名前」を入力する。特に指定がなければデフォルト値でよい。
5.モデル構築画面(ステップ2/6)を入力します。

■ 「最初の入力データ・レコード」を指定する。(ここでは、$B$2:$F$2)
■ 「2番目の入力データ・レコード」を指定する。(ここでは、$B$3:$F$3)
■ 「すべての入力データ・レコード」を指定する。(ここでは、$B$2: $F$211)
6.モデル構築画面(ステップ3/6)を入力します。
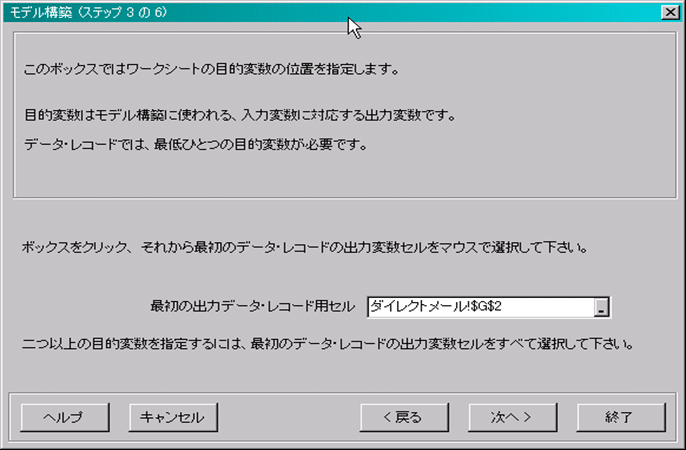
■ 「最初の出力データ・レコードセル」を指定する。(ここでは、$G$2)
7 .モデル構築画面(ステップ4/6)を入力します。
■ 「雑音のレベル」で雑音のレベルを選択します。ここではデフォルトの「一般的な雑音データ」を選びます(株式市場問題などでは「ひどい雑音データ」、数式から作成されたデータでは「クリーンなデータ」を選びます)。
■ 「データの変換レベル」でデフォルトの「一般的なデータ変換」を選択します。
8 .モデル構築画面(ステップ5/6)を入力します。
■ 「変数選択のレベル」を指定します。ここではデフォルトの「包括的な変数選択」を選択します。
■ 「最適化のレベル」を指定します。ここではデフォルトの「包括的なネットワーク検索」を選択します。
9 .モデル構築画面(ステップ6/6)を入力します。

■ 入力内容を確認し、「学習」ボタンをクリックします。
10 .完了画面が表示されます。ここでニューラルネットワークモデルが作成されます。
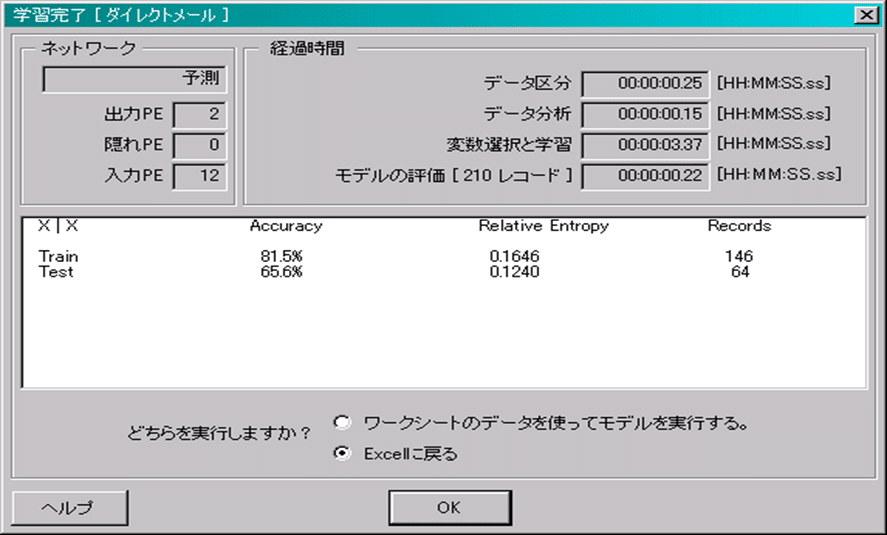
作成したモデルを使って予測する
実際の入出力データを使って学習したネットワークモデルが完成しました。このモデルを使って、予測を行ってみましょう。
1.メニュー「Predict」-「実行」をクリックします。
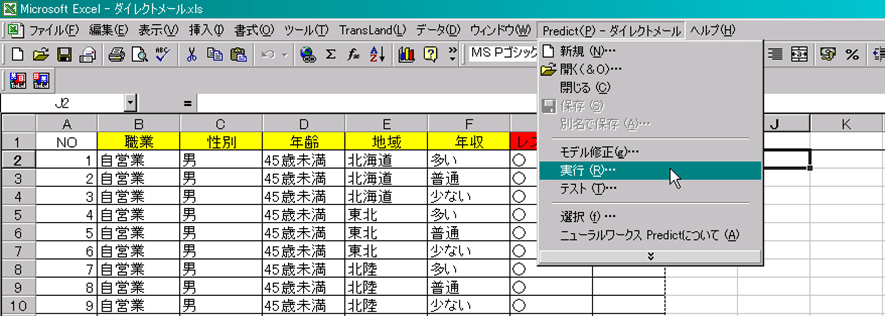
2.次のダイアログボックスで、予測に使用する入力/出力データのセル範囲を設定します。ここではすべての入力データに対する予測値を求めてみましょう。入力のセル範囲(B2:F211)/出力のセル範囲(H2)を指定して、「実行」をクリックします。
5.予測値が表示されました。この画面上のデータに対しては、すべて正しく判別されていることがわかります。
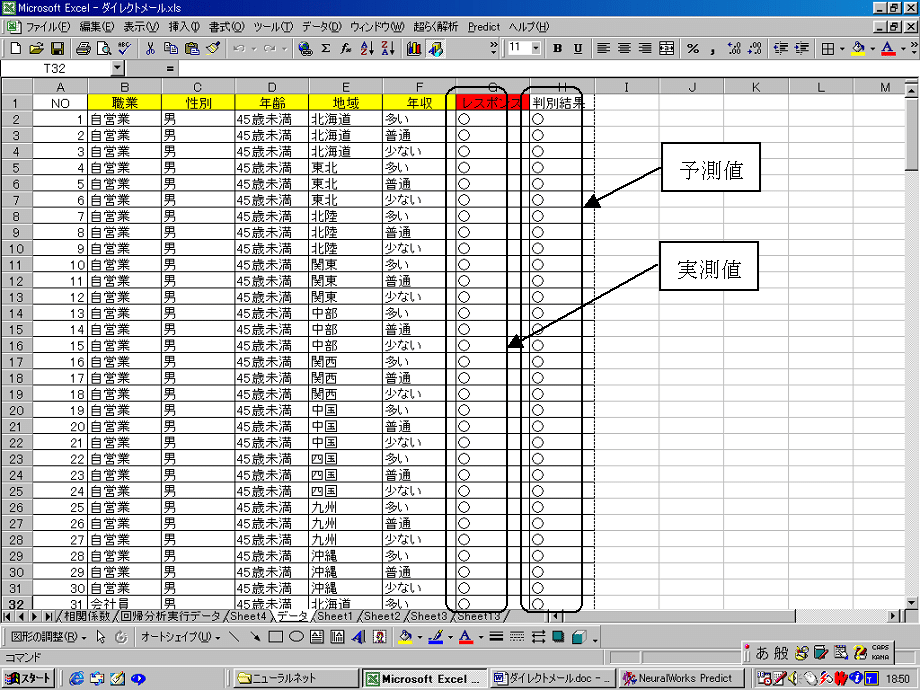
個別データの判別状況は画面をスクロールすれば見られますが、トータルとしてのモデル能を知るためには、PredictのTestコマンドを利用します。ではこの機能を使ってモデルの性能に関するレポートを出力してみましょう。
性能レポートを出力する
Testコマンドを実行してワークシート上にモデルの性能レポートを出力しましょう。
1.メニュー「Predict」-「テスト」をクリックします。

2.次のダイアログボックスで、テストを行いたいデータ区分を指定して、「OK」をクリックします。
■ 「出力結果」にを表示するワークシート上のセル範囲の左上端セルを指定します。セルJ2を設定します。
性能レポートを確認する
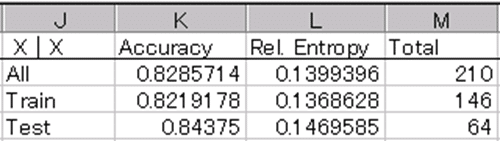
表2がTest実行結果の出力です。
1.第1行のAccuracyは正判別率で、正判別件数/全件数で計算されます。当然1に近いほど良い値です。Rel.Entropyはモデルの「あてはまり具合」を表します。0に近いほどモデルの入力データへのあてはまり具合の良いことを示します。Totalはトータルのデータ件数です。
2.また、J列のAll、Train、Testはデータ区分を表し、Trainは学習用、Testはテスト用のデータセットで、AllはTrainとTestのデータセットを合わせたものです。TrainとTestのデータは、ランダムに全体の70%と30%(デフォルト)の割合で選ばれます。
3.Allの行を見ると、Accuracy 0.8285714、Rel.Entropy 0.1399396、Total 210となっています。これは、正判別率が82.86%(210件中146件)、Rel.Entropyは比較的小さい値になっており、あてはまり具合がよいことを表しています。
4.TrainとTestでも、ほぼ同じ傾向が見られます。
回帰分析の予測結果と比較する
他の分析ツールで予測すればどのような結果が出るのでしょうか。関心のあるところです。そこで一番身近な回帰分析で予測してみましょう。
被説明変数がこの事例の[ダイレクトメールのレスポンス有り、無し]や、[合格、不合格]のようにグループ数が2つのときは回帰分析で分析可能です。グループ数が3つ以上になると、ニューラルネットワークやその他の判別分析用のソフトウェアを使う必要があります。
回帰分析で解析するには、定性的なデータを [0,1]データに置きかえます。
Excelの回帰分析で解析しますが、Excelの回帰分析の変数の個数には制約があります。幸いこの事例はその上限値内なので実行可能です。
途中経過は省略しますが、回帰分析を行うと、年齢アイテムを削除して、職業、性別、地域、年収の4つのアイテムを使うとき最適の回帰式が得られます。
この回帰式を使って、判別予測をしたものが、図19のI列に表示されています。表示された範囲では、回帰分析の結果もすべて正しい判別が行われています。
すべてのデータ(210件)についての予測結果は、正判別数169件(正判別率 80.48%)、誤判別数41件(誤判別率 19.52%)でした。
ニューラルネットワークと回帰分析の予測結果をまとめたものが表3です。

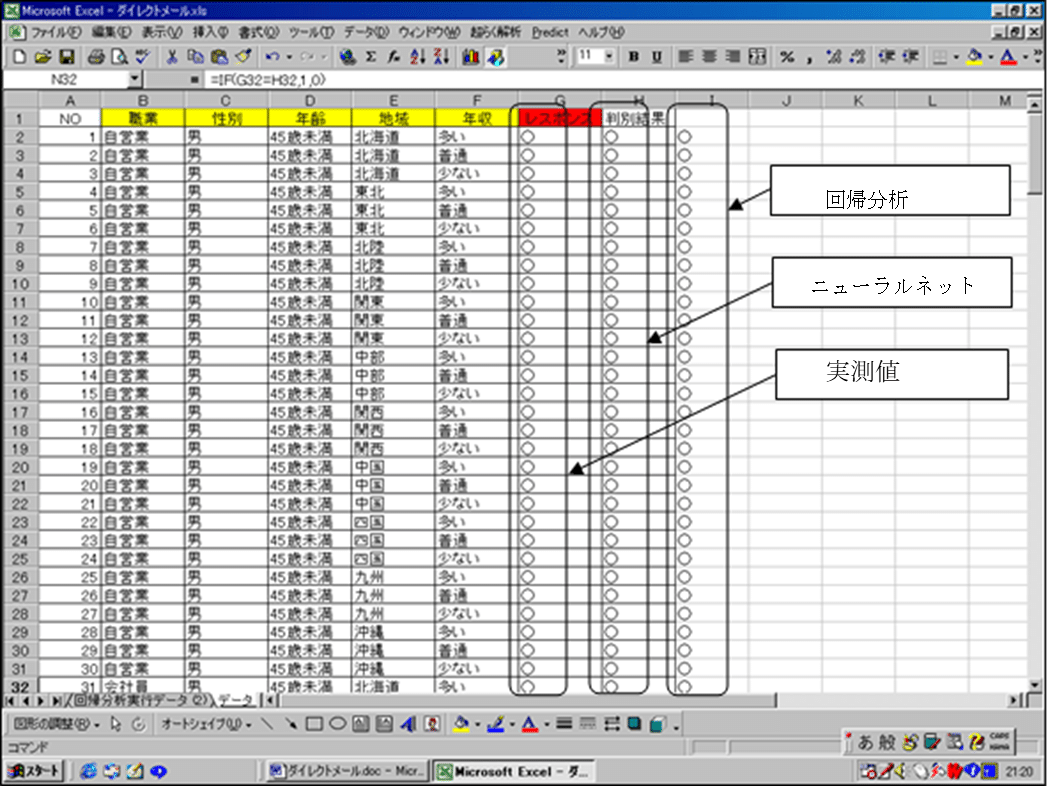
新しいデータに対する予測を行う
新しく追加されたデータに対する予測をやってみましょう。

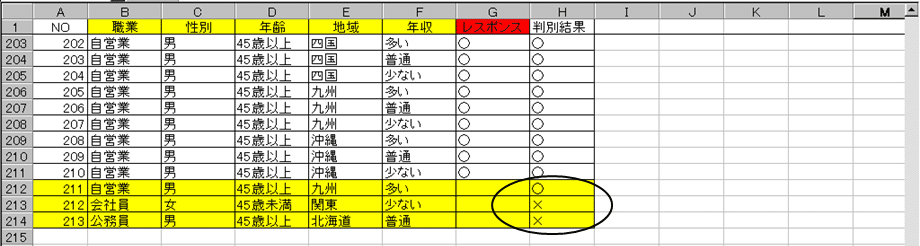
図17 のNO211~213の3人の新会員が加入しました。この3人についてダイレクトメールのレスポンスを予測しましょう。
1.210件のデータに加えて、3人のデータを追加しましょう。
2.メニュー「Predict」-「Run」をクリックします。
3.「Run Formula Inputs」ダイアログボックスで新しいデータのセル範囲B212:F214を指定し、「OK」をクリックします(図21)。

4.「Run Formula Outputs」ダイアログボックスで、予測値を出力するセル範囲の先頭(セルH212)を指定し、「GO」をクリックします。
5.図19のように新しく追加されたデータに対する予測値が出力されます。
ダイレクトメールのレスポンス率を高める
レスポンスの有り・無しに対して、職業、性別、年齢、地域、年収がどのように影響を及ぼしているのかを調べてみます。表1のままでは分析に不向きですので、クロス表を作成して分析を行います。
「ニューラルワークス Predict」はExcelに組み込みのツールですので、Excelの機能がすべて利用できます。ここでは、Excelの「ピボットテーブル」機能を使ってクロス表を作成します。
操作方法は、Excelの「データ」メニューから「ピボットテーブルとピボットグラフ」を選択し、表示されるウイザードウイザードにしたがって操作するとクロス表が作成されます。

1.職業とレスポンスの有無
表4は、「ピボットテーブル」機能を使って求めたクロス表に、レスポンス率(%)の項目を加え、さらにExcelの「並べ替え」機能を使って、レスポンス率の高い順に並べ替えたものです。

この表から職業によってレスポンスの有無にちがいがあるといえるのでしょうか。
このようなケースで、有意なちがいがあるかどうかを判定するには、χ2(カイ2乗と読みます)判定法という統計手法を用います。一定の計算式にしたがって求めた判定値が正の数であればちがいがあると判定されます。
表4の場合、χ2判定値を求めると40.9となり、正数ですので、ちがいがあるといえます。したがって、レスポンス率を高めるには、レスポンス率の高い自営業の人に、次いで会社員の順にDMを打つことになります。
2.性別とレスポンスの有無
表5は、性別とレスポンスの有無のクロス表です。

χ2 判定値が38.9となり、正数ですので、男性のレスポンス率が高いといえそうですが、実は所帯主である男性の名前になっているものの、実際は女性がレスポンスを出していることが多く、性別によるちがいは見られませんでした。
3.年齢とレスポンスの有無
45歳以上の会員のレスポンス率が高いので、レスポンス率を高めるには45歳以上の会員を増やしてDMを打つことになります。
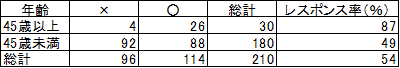
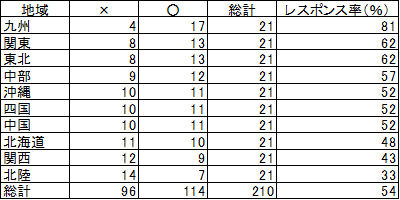
4.地域とレスポンスの有無
表7を分析の結果、レスポンス率の最も高い九州と、最も低い北陸は「外れ値」であると判定されました。「外れ値」とは、数値データのなかで、極端に大きな、あるいは小さな値をとるデータのことで、例外値ともいいます。「外れ値」の原因を追求することで、有益な知見が得られることがあります。ここでは、九州と北陸の原因を追求することによって、レスポンス率を高めるヒントが得られるかも知れません。
5.年収とレスポンスの有無
表7では、年収が「普通」が最もレスポンス率が高く、「多い」、「少ない」の順になっていますが、χ2 判定値は -1.58で、マイナス値ですので、現在のデータではたまたまこの順位になっているものの、これら3項目の間にはレスポンス率に関して優先順位はありません。
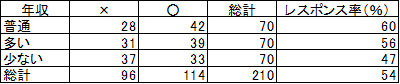
まとめ
「ニューラルワークス Predict」は、ニューラルネットワークの知識がなくても容易に使いこなせます。Excelのアドインとして組み込まれていますので、「Excelでデータを準備」→「Predictで分析」→「Excelで加工・可視化・分析」→「Predictで分析」といったサイクルを迅速にまわすことができ、双方の特長を最大限に活用して効率的にデータマイニングを行える非常に優れた分析ツールです。
※弊社では、データ分析プロジェクトにまつわる様々なご相談に、過去20年以上に渡るプロジェクト経験に基づき、ご支援しています。社内セミナーの企画等、お気軽にご相談いただければ幸いです。
製品カタログ