
はじめてのR&データ分析(仮説検定)

※今回は別のアカウントで公開していた記事を引っ張ってきました。なので少し系統が異なります。
元々データ分析を学んでいたのでそれを整理した記事です。
-----------------------------------------------------------
様々なデータを分析し、そこから意味や傾向を読み取る。
そしてそこから今後のビジネスの方針や適切なキャンペーンを決定する。情報化社会の今日、このPDCAサイクルを生み出すのに最も適しているデータ分析の言語は『R言語』です。
R言語はJavaやC言語、Pythonと比べて知名度が低く、多くのITエンジニアにも馴染みがありません。
しかし、ビックデータ解析がビジネスの要となっている今は「そのためのプログラミング言語」と言っても過言ではないR言語の需要が高まっています。
このnoteでは、初級編ということで、統計学の予備知識がない人でも、Rを使って統計分析ができるように、ざっくり説明していきます!今回扱うのはタイトルにもあるように仮説検定です。
(めちゃくちゃ色々省いてます。反響があれば、追記で主な分布や、分析方法の見分け方等を書きます。間違えてる部分等あれば遠慮なくご指摘ください。)
ではまずR言語とは、
オークランド大学の Ross Ihaka と Robert Gentleman により開発されたもので、オープンソース・フリーソフトウェアの統計解析向けのプログラミング言語及び開発実行環境を指します。
登場時期は1993年と、Javaの1995年よりも2年も早く生まれています。Java同様、改良を重ねていますが、意外にも新しい言語というわけではないのです。
R言語に最も近い言語はPythonだと思いますが、統計解析に関してはR言語の方が抜群に簡単です。
また、オープンソース(※1)で、
フリーソフト(無料)なので、
* 自由にカスタマイズが可能
* 自分で問題の発見や解決ができる
* 開発元の倒産などで使えなくなることはない
などメリットが沢山あります。
※1 ソースコードが公開されていて・中身を改造したり・改造したものを配ったりすることを許可されているソフトウェアのライセンスのこと
さらに、データの操作に対しても非常に柔軟性が高いです。ある程度の知識(統計検定3級~2級)程度あれば、ほぼ自由自在にデータを処理することが可能です。
私個人の感覚では、
・統計検定 3級 ➡ 統計解析の基礎中の基礎を固めるもの
・統計検定 2級 ➡ 大まかな分布や、統計方法の理解をするもの
といったイメージです。
2級以上は持っておいた方が良いと思います。正直準1級、1級はかなり難しいです。1級は神様レベルにすごいです。
ではでは本題です。
Rを用いて統計分析を始めましょう!
Rは先ほども述べた通り、フリーソフトです。
このnoteを読んで気になった方は「R インストール 仕方」とかで適当にググっていれてみてください。
インストールして起動したら多分こんな画面が出ます。↓
結構簡素ですよね。
この左上に出てきた「R Console」に1+1とか入力すれば2を返してくれます。ただこれだと使いにくい。。
Rを使いやすくする方法を紹介します。
「Rコマンダー」や「Rstudio」というフリーソフトを用いれば、
より楽に扱えます。おすすめです。
シンプルな画面でそこまで複雑でないデータを扱うならRコマンダー、より操作性があり綺麗で見易い画面を好み、複雑なデータを扱うならR studioを勧めます。R studioでは、コマンドの先端を入力するだけでその後に続くコマンドの順番や候補を示してくれます。便利です。
どちらも慣れてしまえば使いやすくなるので、Rコマンダーを極めるのも不利ではありません。使いやすい方を使うのが良いと思います。
R コマンダーはこんな感じ↓
R studioはこんな感じ↓
要望があれば、R コマンダーでの分析方法も紹介しますが、今回はR studioを用いて説明していこうと思います。R studioのインストール方法は割愛させていただきます。『R studio インストール方法』などでググってください。
ダウンロードしたらまず、Rstudioを起動し、
左上の「File」をクリックし、
New Fileか New Projectを選択します。
「New File」なら、次で「R Script」か「R Notebook」を選択するといいと思います。
今回はNew File→ R Scriptで開きました。
これで土台は整いました。
保存はしておかないと消えます。
※(「File」を開き、「Save」を押すと保存できます。)
では、ここからデータをR studioに挿入していきます。エクセルからデータを挿入することももちろんできますが、説明が長くなるので今回はサンプルのデータを使います。Rには多くのデータサンプルが元から入っているので、そのうちの1つ、Titanic(タイタニック)を使います。
R studioの画面は4分割されています。↓
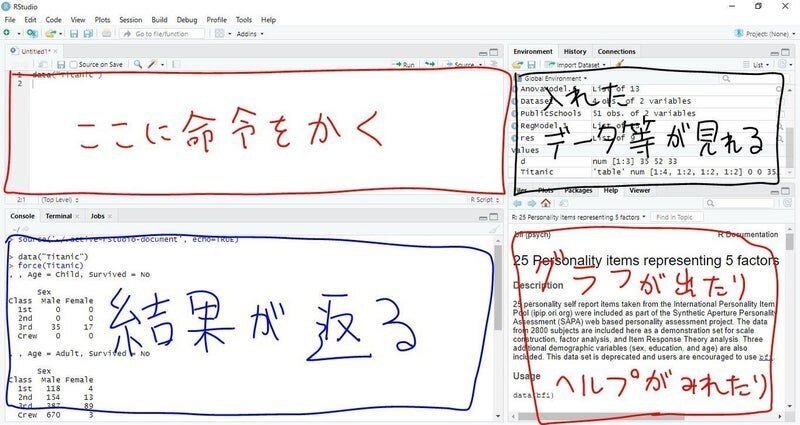
左上の(ここに命令をかく)と書いた場所に
x<-data.frame(Titanic)copy
と書いて「Ctrl+Shift+Enter」を同時押しで実行します。
x という名前の箱にTitanicのデータを入れてみました。
そうすると右上の(入れたデータ等が見れる)と書いたところに x という名前のデータが入っていると思います。
x<-data.frame(Titanic)
xcopy
「x」とデータ名を入力すれば、内容が確認できます。
内容はこんな感じ↓
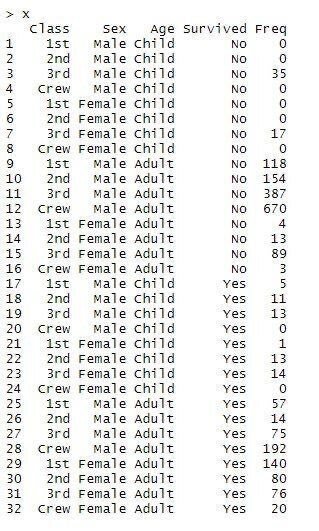
このデータセットは、遠洋定期船(タイタニック)の致命的な初航海の乗客の運命についての情報が与えられています。タイタニックは映画で有名なので、イメージがつきやすいかと思います。
データの要素は以下の4つです。
・経済的地位(Class) 1st , 2nd , 3rd , Crew
・性別(Sex) Male , Female
・年齢(Age) Adult , Child
・生存(Survived) Yes , No
経済的地位は客船のクラスを表しており、1st>2nd>3rdとリッチです。
Crewは働いてる人ですね。Freqは頻度です。同じ条件の人をまとめて人数で表しています。頻度でまとめられると、今後の検定がしにくくなるので、頻度表示をなくして、2201人の乗客すべてのデータに変形させます!
install.packages("epitools")
library(epitools)
x.new <- expand.table(Titanic)copy
epitoolsというパッケージをインストールし、libraryで読み込みました。
それをx.newに代入してみました。できていれば2201人分のデータに変形できているはずです。
ではここから本題に入ります!!
統計学でよく使う仮説検定を行っていきます!
仮説検定とは、名前の通り仮説が採択されるか棄却されるかを検定することです。仮説検定の流れはこんな感じ ↓
①まずデータを見て、仮説を立てる。
②そこから適切な分析を用いて仮説を検証していく。
③結果から、「仮説通りだったか or 異なったか」、「意外な要素が見つかったか」を確認します。
(④そこから得られる知見はどんなものかを考えます。)
※データにはデータの形式や内容に合わせて適切な分析方法があります。
なんでもこれから説明するやり方で分析すればいいということはありません。データが質的か量的か、順序尺度であるか否かなど、細かい判断が必要になるので、そこは要学習です。
長くなりますが、仮説検定をするうえで、避けて通れない「帰無仮説」と、「対立仮説」について説明します。
帰無仮説とは、差がない,効果がないなど、○○ないといった形で否定されることを前提として立てられる仮説です。しかし、必ずしも否定形で用いるわけではなく、主張したい説の方を対立仮説とし、その逆を帰無仮説とする場合もあります。この仮説が棄却されると対立仮説が成立します。
対立仮説とは、帰無仮説が成立しないと判断された場合に採択される、帰無仮説に対立する仮説です。
出力されたP値が0.05より小さい場合、帰無仮説を棄却し、対立仮説を採択するという手順をとります。
今回のTitanicのデータを見て、帰無仮説と対立仮説を立て、仮説検定をしてみましょう!
帰無仮説・・・「経済的地位(Class)と救助されるかどうか(Survived)には関連がない」
対立仮説・・・「経済的地位(Class)と救助されるかどうか(Survived)には関連がある」
という仮説が立てられます。関連のあるなしをみていきます。
分析方法はピアソンのカイ二乗検定です。( 説明しようと思って書いたんですが、本当に長くなってしまったので割愛します(泣) が、ピアソンのカイ二乗検定を選んだ理由は、データが順序を考慮しない名義尺度の二元分割表だからです。)
今回必要となるのは、ClassとSurvivedの2つのデータです。
4つあった要素から、ClassとSurvivedだけ抽出します。
x.new1<-x.new[,c("Class","Survived")]copy
次に、二元表を作っていきます!
x.new2<-table(x.new1)copy
tableという関数を使ってx.new1のデータを二元表にしました。
こんな感じになります↓
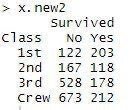
ここまでデータ加工ばかりしてきましたが、やっと希望の形になったので、データをカイ二乗検定( chisq.test )にかけます。
result<-chisq.test(x.new2)
resultcopy

結果、カイ二乗値は190.4
自由度は3、p値は0.05を大きく下回っています。
p値が0.05より小さいので、帰無仮説を棄却し、対立仮説を採択します。
よって、
【結論】経済的地位と救助されるかどうかには関連がある。
といえるわけです。
仮説検定はあらゆる分野で使われています。
・新薬の研究で、○○という薬には効果がある、ない
・ダイエットに効果がある、ない
など様々なことを科学的に判断することができます。
ぜひ一度、Rと統計学について学んでみてください。
最後まで読んでくださり、ありがとうございました。