
Whisper-turbo-mlxとBlackHoleでMTGリアルタイム文字起こし

背景
Whisper-turboと、それに対応したmlxが出たこともあり、ローカルMacのCPUでもリアルタイム文字起こしできないか試した。また、社内MTGをSlackハドルで行うことが多いため、MTG中に文字起こしし続けてくれるようにしてみた。以下、Macユーザー向けなので注意
事前準備と環境設定
HomebrewでBlackHoleのインストール
音声の仮想的なルーティングを可能にするために、まずはBlackHoleを導入する。自分は16チャンネル版をインストールしてしまったので、後の設定がそれに対応している。(実際には2チャンネル版で十分かと)
brew install blackhole-16chAudio MIDI設定での機器セット作成
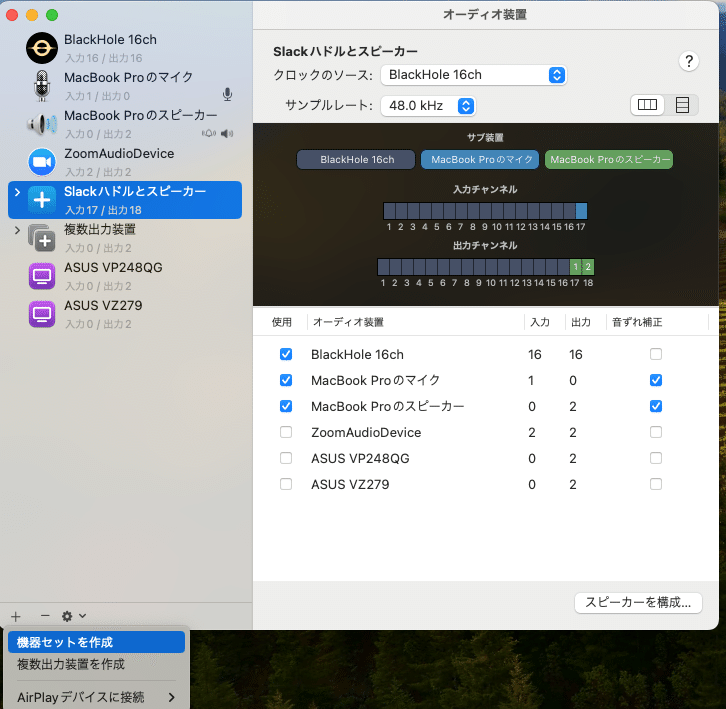
次に、Audio MIDI設定アプリケーションを用いて新しいオーディオデバイスセットを作成する。具体的には、BlackHoleと使用中のマイク、スピーカーを組み合わせて以下のように設定する。
Audio MIDI設定を開く
左下の+から、「機器セットを作成」を選択し、BlackHoleとマイク、スピーカーを選択。
必要なら適当に名前をつける
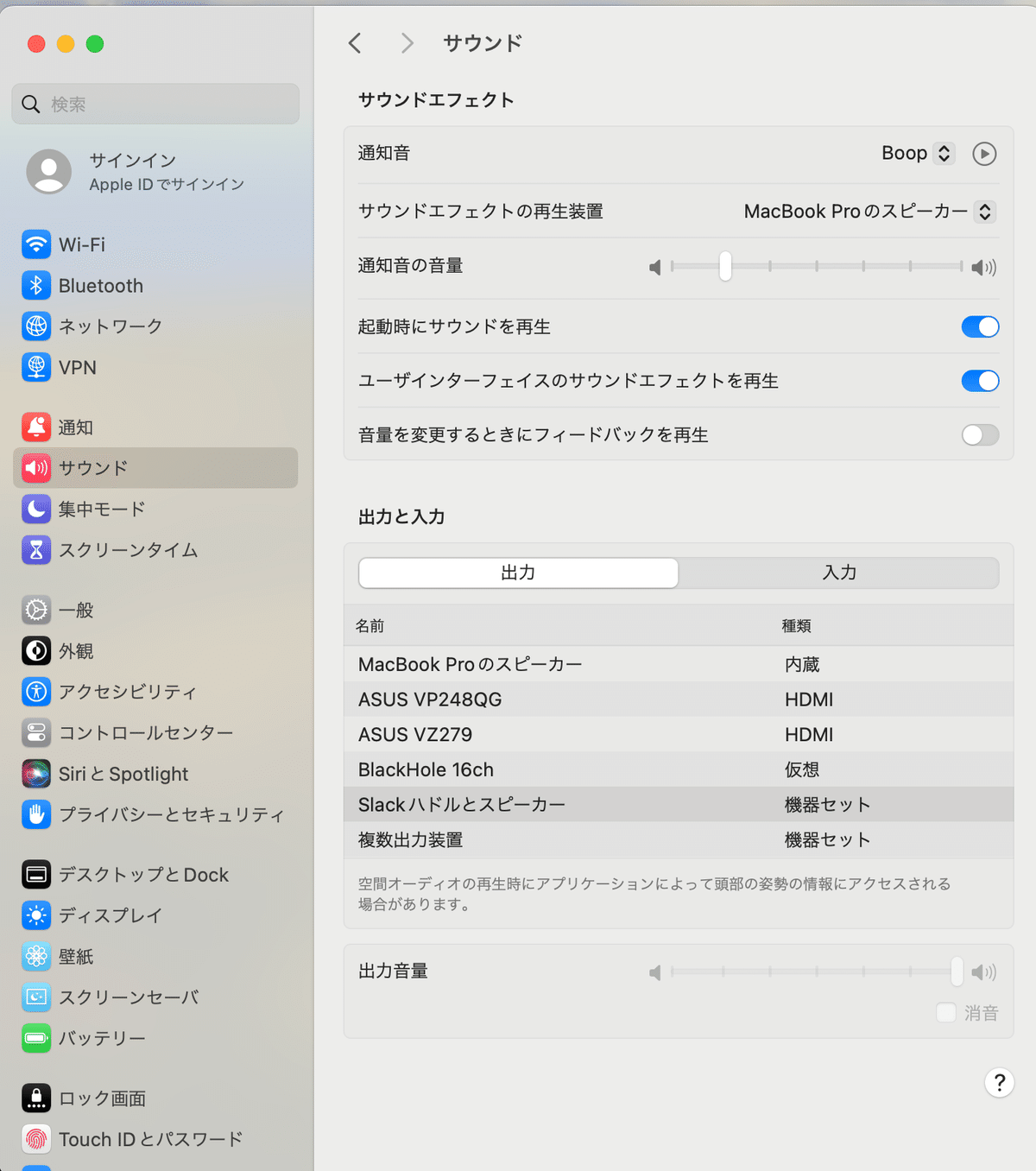
サウンドの設定
出力を先ほど作成した機器セットを選択
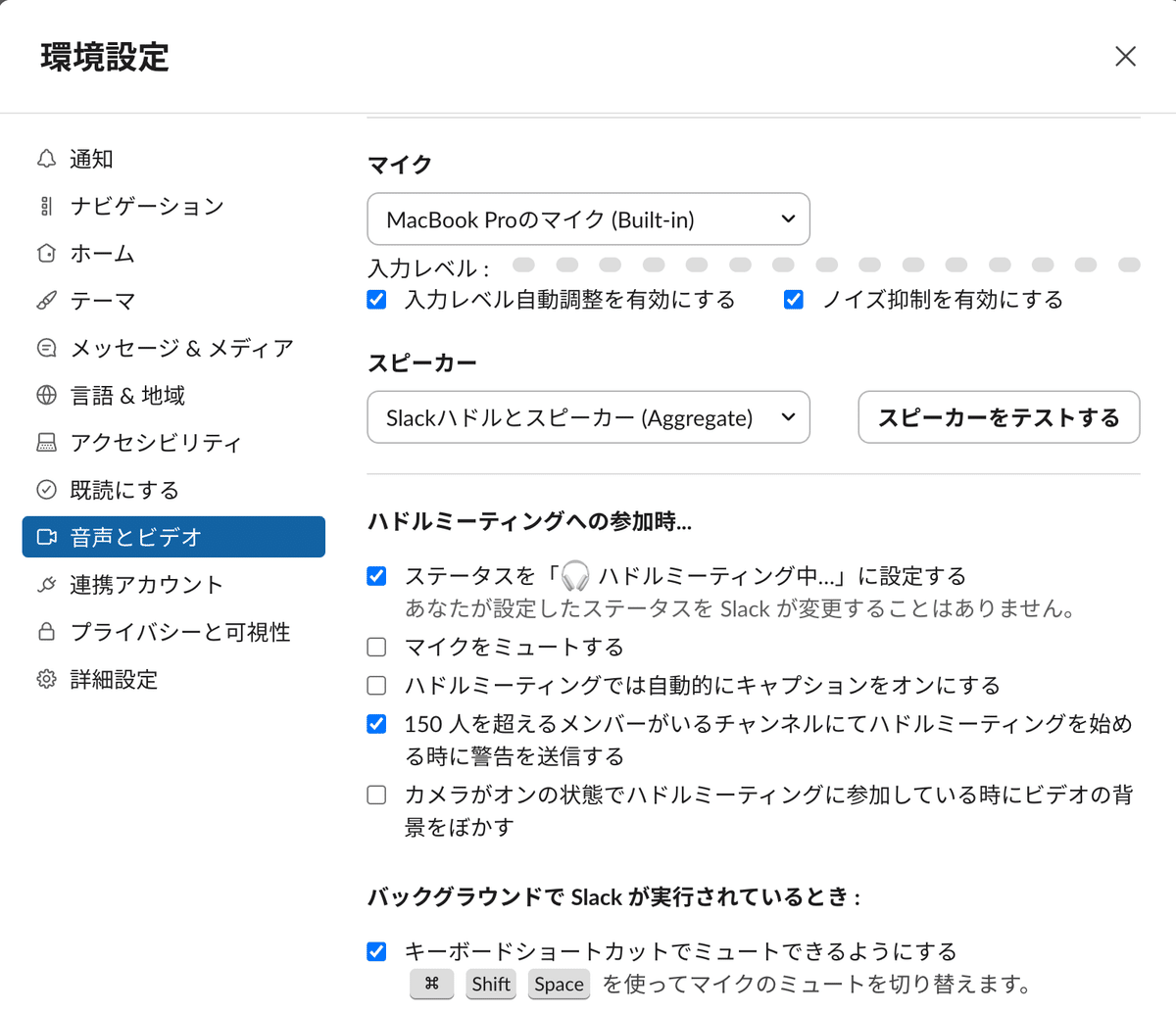
Slackの環境設定でマイクとスピーカーの入出力確認
サウンド設定を変更する際には、Slackの環境設定にも反映されるぽいが、念のため以下を確認する
command + , で環境設定を開く
スピーカーが先ほど作成した機器セットになっていることを確認
スピーカーをテストするで、音声が聞こえているかも確認
依存ライブラリのインストール
私はryeを使っているので以下のコマンドを実行、
rye add openai-whisper ffmpeg-python sounddevice scipy mlx-whisper pydub librosa
rye syncdependencies = [
"openai-whisper>=20240930",
"ffmpeg-python>=0.2.0",
"sounddevice>=0.5.0",
"scipy>=1.14.1",
"mlx-whisper>=0.3.0",
"pydub>=0.25.1",
"librosa>=0.10.2.post1",
]pipの場合は、
pip install openai-whisper ffmpeg-python sounddevice scipy mlx-whisper pydub librosaコード
作成したコードは以下
import mlx_whisper
import sounddevice as sd
import scipy.io.wavfile as wav
import numpy as np
import tempfile
import threading
import signal
import sys
import argparse
import time
import queue
def transcribe_audio(audio_file, show_timestamp, start_time):
text = mlx_whisper.transcribe(audio_file, path_or_hf_repo="mlx-community/whisper-turbo")["text"]
if show_timestamp:
elapsed_time = time.time() - start_time
elapsed_time_str = time.strftime("%H:%M:%S", time.gmtime(elapsed_time))
text = f"[{elapsed_time_str}] {text}"
print(text)
def capture_slack_audio(duration=10, sample_rate=16000, mic_channel=16, speaker_channel=0):
# print("Slackハドルとスピーカーでの録音を開始します...")
# デバイス名でデバイスIDを取得
device_name = "your device set name" # ここを自分が設定した機器セット名に
input_device = None
devices = sd.query_devices()
for idx, device in enumerate(devices):
if device_name in device['name']:
input_device = idx
break
if input_device is None:
raise ValueError(f"デバイス名 '{device_name}' が見つかりませんでした。")
# デバイスを設定
sd.default.device = (input_device, None) # 出力はなし
# 音声キャプチャ
audio_data = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=17, dtype='float32')
sd.wait()
# マイク入力とスピーカー出力を選択
mic_audio = audio_data[:, mic_channel]
speaker_audio = audio_data[:, speaker_channel]
# 2つのチャンネルを結合
combined_audio = np.column_stack((mic_audio, speaker_audio))
# float32からint16に変換
combined_audio_int16 = (combined_audio * 32767).astype(np.int16)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as temp_audio_file:
wav.write(temp_audio_file.name, sample_rate, combined_audio_int16)
return temp_audio_file.name
def real_time_transcription(show_timestamp):
start_time = time.time()
audio_queue = queue.Queue()
def capture_audio():
while not stop_event.is_set():
slack_audio_file = capture_slack_audio(duration=10)
audio_queue.put(slack_audio_file)
def process_audio():
while not stop_event.is_set():
try:
audio_file = audio_queue.get(timeout=1)
transcribe_audio(audio_file, show_timestamp, start_time)
except queue.Empty:
continue
capture_thread = threading.Thread(target=capture_audio)
process_thread = threading.Thread(target=process_audio)
capture_thread.start()
process_thread.start()
capture_thread.join()
process_thread.join()
def signal_handler(sig, frame):
print("録音を停止します...")
stop_event.set()
transcription_thread.join()
sys.exit(0)
# argparseの設定
parser = argparse.ArgumentParser(description="Slackハドルとスピーカーの音声を録音し、文字起こしを行います。")
parser.add_argument('--show-timestamp', action='store_true', help='文字起こしテキストの左側に経過時間を表示します')
args = parser.parse_args()
# メイン処理部分
stop_event = threading.Event()
transcription_thread = threading.Thread(target=real_time_transcription, args=(args.show_timestamp,))
print("録音を開始します...")
transcription_thread.start()
signal.signal(signal.SIGINT, signal_handler)
signal.signal(signal.SIGTERM, signal_handler)
signal.pause()
capture_slack_audio関数のdevice_name部分を、上記の設定した機器セット名にすると良い。
結果
rye run python speech_to_text.py --show-timestamp録音を開始します...
Fetching 4 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 53261.00it/s]
[00:00:11] このようにほぼリアルタイムで話している内容が表示されます
[00:00:21] 現在10秒間隔で文字起こししていますけどこれの間隔を変えるなど好きに設定してみてください
[00:00:32] この出力された文字テキストを活用して他のプロンプトフレームワークと結合させることでもっと面白いことができるようになるかもしれません
[00:00:42] 終わる際は今はCtrl Cになっております
^C録音を停止します...まとめ
今回の試みでは、MacとWhisper-turboを用いることで、ローカルMacのCPUでも、ある程度の高い精度でSlackハドルを文字起こしできることが確認できた。さらなる調整が必要ではある。(例えば、無音の部分では「Thank you」などと誤って文字起こしされることがある。) realtime apiを使い続けるにはまだ高コストなので、このような文字起こし結果も使っていきたい。