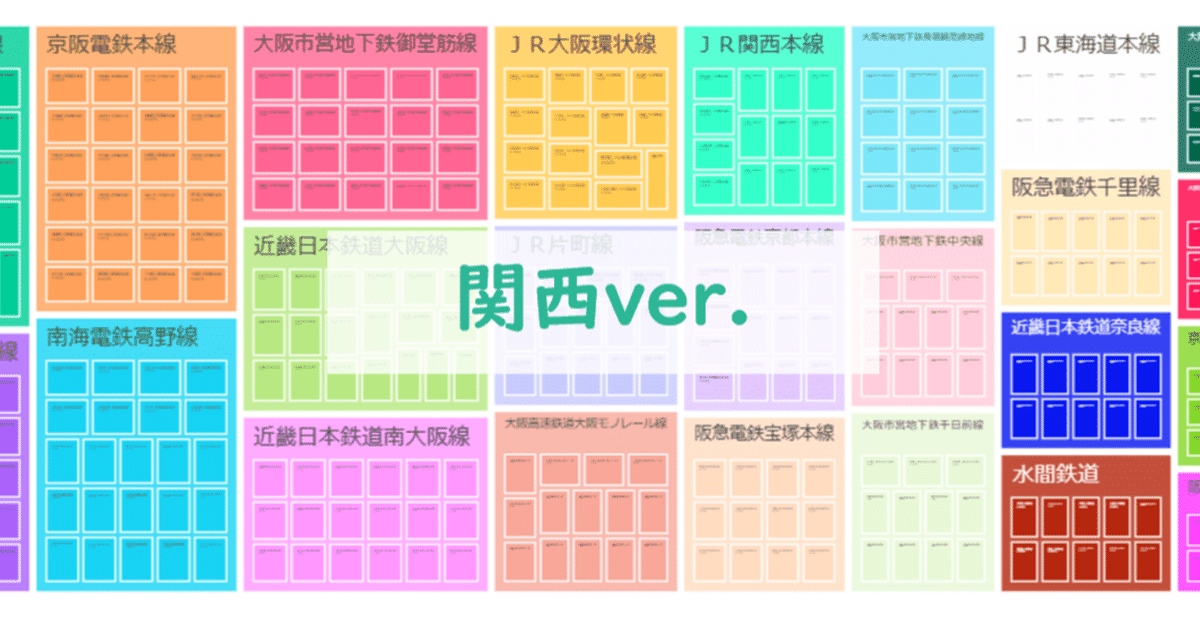
【暇つぶし】関西の駅の乗降客数をツリーマップにした、だけ。

以前、「東京メトロ」の乗降客数をツリーマップにして遊んでみました。
で、↑と同じように「関西の主要駅」のツリーマップを作ってみました。暇つぶしです。
グニグニ動くグラフが作れるPythonのPlotlyというライブラリを使用してます。
データ分析ではご法度の「目的なき可視化」ですが、楽しんで頂ければ幸いです。
ツリーマップってなに
データの量を「四角形の大きさ」で表し、階層構造を「入れ子の四角形」で表す手法です。
要素の階層関係とデータ量が一覧で把握できる点が便利です。

仮想通貨が盛り上がってた時期に、↑のような図をみた方も多いのではないでしょうか。
以前は「Jupyter Notebook」を使いましたが、今回は「Google Colaboratory」を使用してみます。前から気になってまして。
Google Colabとは、Jupyter Notebookを必要最低限の労力とコストで利用でき、ブラウザとインターネットがあれば今すぐにでも機械学習のプロジェクトを進めることが可能なサービスです。
※上記リンクより
作った🚃
こちらに載っている情報を活用させて頂きました。
完成形は、こんな感じ。

四角の大きさを「乗降客数」にしたバージョンはこちら。

グニグニと触れるグラフです。自宅待機の暇つぶしに作成してみました。
データは↓からダウンロードできるような、何らか集計されたものがあれば、色々試せます。
楽しんで頂けたら幸いです。
やり方でおま
◆データの準備
コチラのサイトの↓の部分をコピペして、
↓
エクセル等に張り付けたあと、csvとして保存します。
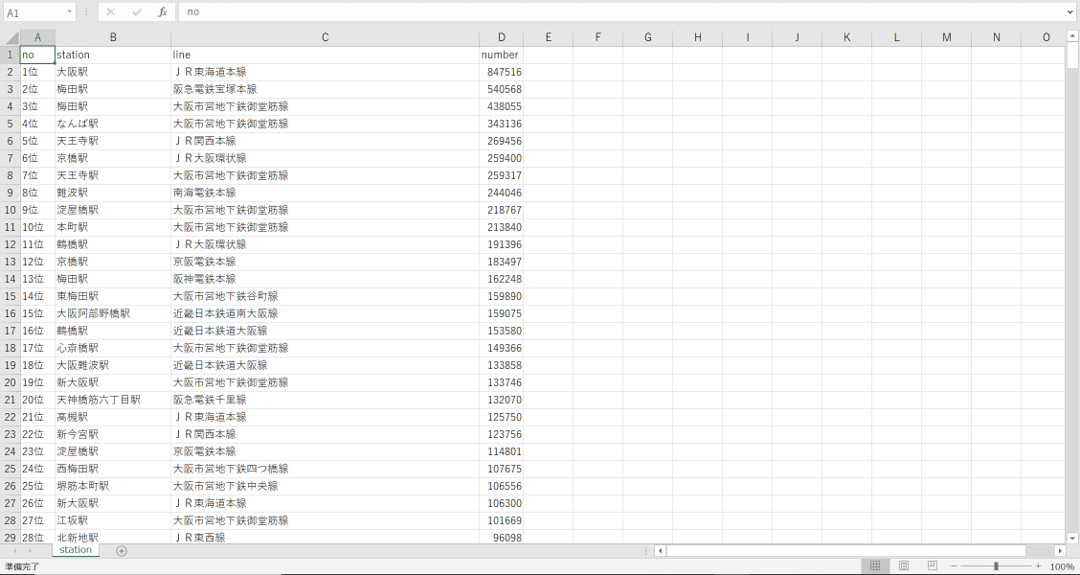
ファイル名は、「station.csv」とでもしておきましょう。
◆Google Colabの準備
説明は割愛します。↓をご参考に「Google Colab」を立ち上げます。
◆データの取り込み
ライブラリのインポート
#ライブラリのインポート
import pandas as pd
import ioファイルのアップロード
from google.colab import files
uploaded = files.upload()こちらを実行すると↓のような、「ファイル選択」ボタンが出てくるので、先ほどの「station.csv」をアップします。

◆データの読み込み
#データの読み込み
df=pd.read_csv(io.StringIO(uploaded['station.csv'].decode('UTF-8')), header=0)
#確認
df.head()◆データの加工
#駅名と沿線名が合わさった列を作る
df["station&line"] = df.station + "_" + df.line
#確認
df.head()
#ライブラリのインポート、その2
import plotly.express as px
import plotly.graph_objects as goplotlyの引数に使うlistを用意します。
#駅名、乗降客数それぞれのlistを作ります
station = []
for i in df["station&line"]:
station.append(i)
number = []
for i in df["number"]:
number.append(i)#長さが同じlistになっているかの確認
print(len(station))
print(len(number))◆まず、駅名だけのツリーマップ
#駅名×乗降客数の大きさのツリーマップ
fig = go.Figure(go.Treemap(
labels = station,
parents = [""]*len(station),#ここでは便宜上こうしておく
values = number,#labelsの要素に対応する値をいれる
textinfo = "label+value+percent entry"
))
#描画
fig.show()
こんな感じの、眼がチカチカするぐらいカラフルなツリーマップが出てくると思います。
◆沿線ごとにグループにしたツリーマップ
大きい四角の中に、小さい四角(入れ子構造)が入っているツリーマップを作ります。
#入れ子構造にするには、labelsとparentsの引数で、親子関係になるlistを作ります
#駅名と沿線名を入れる空のlistを用意
station_and_line = []
#まずは、stationから1個ずつappendする
for i in station:
station_and_line.append(i)
#沿線名も1個ずつappendする
for i in df["line"].unique():
station_and_line.append(i)
#確認
print(station_and_line)
print(len(station_and_line))#入れ子構造の親側のlistを用意します。
#空のlistを用意
parents = []
#駅名の親は、沿線名なのでlineの要素を入れます
for i in df["line"]:
parents.append(i)#沿線名の親は無いので、空白のlist要素を入れます
#一度、dummyのlistを用意
dummy = []
for i in [""]*len(df["line"].unique()):
dummy.append(i)
#dummyのlistから1個ずつ「""」を入れていく
for i in dummy:
parents.append(i)print(station_and_line)
print(len(station_and_line))
print("-----")
print(parents)
print(len(parents))#乗降客数は無視して、一度作ってみる
fig_2 = go.Figure(go.Treemap(
labels = station_and_line,
parents = parents,
#values = number,
textinfo = "label+value+percent entry"
))
#描画
fig_2.show()
◆これの四角の大きさを、乗降客数にする
最後に、入れ子構造になったツリーマップの四角を乗降客数によって大きさが変わるようにします。
#line名だけのデータフレームを作ります
line_unique = pd.DataFrame(data = df.line.unique(), columns=["line"])
#確認
line_unique.head()#groupbyして、沿線合計を出します
df_groupby_line = df.groupby(by="line").sum()
#このままだと沿線名の順番が変わってしまう
df_groupby_line.reset_index().head()#groupbyでsum集計した各沿線の値を沿線名の順番通りに突合
df_line_sum = pd.merge(line_unique, df_groupby_line.reset_index(), on ="line")
#確認
df_line_sum.head()これで、きれいに順番通りになった各沿線の合計乗降客数のデータフレームが出来上がりました。

#確認
print(len(number))
print(len(df_line_sum))#駅別の乗降客数と、沿線別の乗降客数合計を入れるlistを作ります
#空のlistを用意します
number_of_station_and_line = []
#駅別の乗降客数を入れます
for i in number:
number_of_station_and_line.append(i)
#沿線別の乗降客数合計を入れます
for i in df_line_sum["number"]:
number_of_station_and_line.append(i)#各listの長さが一緒か確認
print(station_and_line)
print(len(station_and_line))
print("------------------------")
print(parents)
print(len(parents))
print("------------------------")
print(number_of_station_and_line)
print(len(number_of_station_and_line))
3つのlistの長さが一緒かどうか確認します。ここで一緒じゃなかったら、この項の初めからやり直します。
fig_3 = go.Figure(go.Treemap(
labels = station_and_line,
parents = parents,
values = number_of_station_and_line,
textinfo = "label+value+percent entry"
))
#描画
fig_3.show()
このようなグラフが描画されたら成功です。お疲れさまでした。
後は、心ゆくまでグニグニお触りください。
↓に以上までの使用したcsvデータとスクリプトが書かれたファイルをアップします。
関東編はコチラ
やっぱり、電車のデータは↓のように地図上に可視化した方が面白いですし、わかりやすいですね。
よかったらどうぞ。
その他にも色々やってます
いいなと思ったら応援しよう!
