
Pythonで「スタバの店舗データ」を地図にプロットして分析してみた

下記のnoteで実施した、いろんな集計・分析のやり方解説版noteです。
こんな方におすすめです
集計・分析にはPythonを使用しています。下記のような方のご参考になるかと思います。
・文系マーケターで、今、データ分析を勉強中の方。
・特に企業内で、出店戦略、エリアマーケティング、広告・販促戦略、顧客調査などで、地理情報を扱う方が多い方。
・専用ツールがあるが、それが使いづらく、自前で何かできないかな〜、と思ってる方。
・Pythonを学習し始めて、基礎的なことは理解して、何か面白いことできないかな〜と悩んでいる方。
このnoteで出来るようになること
・pythonを用いた基本的集計(merge、pivot_table、groupby含)
・foliumという地図上に色々できる便利なライブラリの基本的な使い方
・plotlyというこれまた便利なライブラリの基本的な使い方
実務でも活かしやすいと思います。それでは、楽しんで頂けたら幸いです。
分析環境の準備
いつものJupyter notebookを使います。
データ分析をする上でとても便利でおすすめなので、まだの方はこれを機にどうぞ。インストールの仕方がわからない方は、こちらがおすすめです。
☕️下準備(前処理・欠損値の確認など)
データの用意
下記からcsvをダウンロードできます。
ライブラリのimport
#基本的なデータ処理のためのライブラリ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsデータの読み込み
#データの読み込み
df = pd.read_csv("/Users/[あなたのディレクトリ]/directory.csv") まず、どんなデータかざっと把握する
#確認
df.head()
店名(StoreName)や所在地(StreetAddress)、緯度経度(Longitude, Latitude)など、各店舗の基本情報が列挙されてます。
#各列のユニークバリューを取得する。数値データの際は平均値と標準偏差を取得する関数を作る
def see_unique(df):
print("●Unique values")
print("")
#各列のデータタイプを表示する
for i in df.columns:
column_numbers = df.columns.get_loc(i)
if df[i].dtype == 'int' or df[i].dtype == "float":
print("#",column_numbers," ",i,": ",df[i].dtype)
print("Ave.",df[i].mean()," , ","SD",round(df[i].std(),1))
print("")
else:
print("#",column_numbers," ",i,": ", df[i].dtype)
print(df[i].unique())
print("")
see_unique(df)
前処理を少々と、欠損値の確認をします。
取り扱いやすくするように列名を調整します
def care_columns_name(df):
#取り扱いやすいように、列名のなかに含まれてる記号をアンスコに変更する
print("The column names have been changed to make them easier to handle below. \n")
#列名を取得して、スペースを_に置換する
print(df.columns)
replaced_columns = df.columns.str.replace(" ", "_").str.replace('-', '_').str.replace('$', '').str.replace('\n', '_').str.replace('/', '_')
df.columns=replaced_columns
print("↓\n")
print(replaced_columns)
#Pandasでは扱えない記号やスペースなどが列名に入ってるのを'_'に変換する
care_columns_name(df)
#欠損値の確認
def kesson_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
kesson_table = pd.concat([null_val, percent], axis=1)
kesson_table_ren_columns = kesson_table.rename(columns = {0 : '欠損数', 1 : '%'})
return kesson_table_ren_columns
🗾まず、サクッと集計を
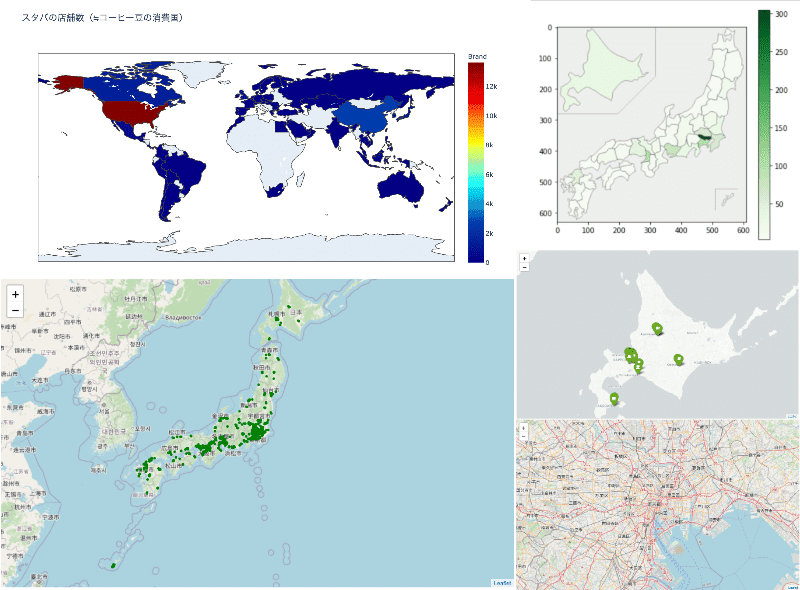
準備が整ったので、日本の都道府県別の店舗数を集計します。
日本の店舗データだけ抽出してdfを作る
#日本だけ取り出す
starbucks_jp = df[df.Country == 'JP']
#index振り直し
starbucks_jp = starbucks_jp.reset_index(drop = True)
#確認
starbucks_jp.head()都道府県(state_province列)が番号しかないので、県名を追加したほうがわかりやすいので加工します。
こちらのサイトの対応表が使えそうなので、csvで用意しました。お使いのPCにDLしてください。もしくはクリップボードコピーでも可です。
#state_provinceの番号を都道府県名に変更したい
#元データはここからコピーできます
#https://makitani.net/shimauma/knowledge/japan-prefecture-code
#コピペでデータを取り込み
#prefecture_code = pd.read_clipboard()
#csvに一旦保存
#prefecture_code.to_csv("/Users/[あなたのディレクトリ]/prefecture_code.csv")
#一旦csvにした都道府県と番号の対応表を読み込む
prefecture_code = pd.read_csv("/Users/[あなたのディレクトリ]/prefecture_code.csv")こちらも取り扱いやすいように列名を変更します
#こちらも扱いやすいように列名を変更します
prefecture_code.rename(
columns=
{'都道府県コード': 'State_Province',
'都道府県':'prefectures_jp'},
inplace=True)
#不要な列の削除
prefecture_code.drop(columns= 'Unnamed: 0', inplace= True)
#番号をint型にしておく
prefecture_code.State_Province = prefecture_code.State_Province.astype('int')
#確認
prefecture_code.head()
突合元データと都道府県一覧をmergeする
#突合元の列もint型に変更しておく
starbucks_jp.State_Province = starbucks_jp.State_Province.astype('int')
#mergeする
starbucks_jp = pd.merge(starbucks_jp, prefecture_code, on='State_Province')
#確認
starbucks_jp.head()
元データの右側に、都道府県名が入ってるので突合できています。
ナンバリングする
これはmustではありませんが、一応整理しておきます。
#番号と都道府県名の列でナンバリングする
starbucks_jp["no_prefectures"] = 0
for i in range(len(starbucks_jp)):
starbucks_jp["no_prefectures"][i] = str(starbucks_jp.State_Province[i]) +'_' + str(starbucks_jp.prefectures[i])
#確認
starbucks_jp.no_prefectures.unique()
ここまで前処理です。お疲れ様です。
都道府県別でサクッと集計
#都道府県別の店舗数を集計してみる
starbucks_jp_gb = starbucks_jp.groupby("no_prefectures")
#都道府県単位でcount集計して格納
starbucks_jp_gb_count = starbucks_jp_gb.count().sort_values(by="Brand", ascending=False)
#index振り直し(任意)
starbucks_jp_gb_count.reset_index(inplace = True)
#描画
plt.figure(figsize= (10,15))
sns.barplot(x='Brand', y='no_prefectures', data=starbucks_jp_gb_count,palette="Blues_d")
--- ✂︎ おまけ ✂︎ ---
経営スタイル別のクロス集計
元データに「Ownership_Type」という経営管理体制別の列があったので、それでクロス集計してみました。
#経営スタイル別のクロス集計のためのpivot_tableを作る
starbucks_jp_pivot = pd.pivot_table(
starbucks_jp,
columns="Ownership_Type",
index="no_prefectures",
values= "Brand",
aggfunc="count",
#margin = Trueで行列の合計が出せる
margins=True,
#合計の行列の名前を設定
margins_name='total'
).sort_values(by = 'total', ascending= True)
#描画 積み上げ棒グラフでみてみる
starbucks_jp_pivot.drop(labels='total', axis=0).drop(columns='total', axis=1).plot.barh(stacked=True, figsize=(5,10))
--- ✂︎ ---
📍地図にプロットしてみる
ライブラリのimport
#地図にプロットする用のライブラリをimportします
import folium--- ✂︎ --- ご参考 --- ✂︎ ---
過去にfoliumをインストールしておかないとimportできないので、インストールしていない方は下記をJupyterNotebook上で実行してインストールした後、↑を実行してください。
ターミナルからのインストールでももちろん大丈夫です。
! pip install folium ![]()
--- ✂︎ ---
地図に日本全国のスタバをプロットする
初めに、プレーンな地図を読み込みます
#プレーンな地図を用意する
map1 = folium.Map(
#初期位置のセット
location=[35.681167, 139.767052],
#初期表示の拡大具合のセット
zoom_start = 11,
#地図のスタイルの選択 どれか一つ選んで#をはずしてください
tiles = "OpenStreetMap"
#tiles="cartodbpositron"
#tiles = "Stamen Toner"
#tiles = "Stamen Terrain"
)
#描画
map1
--- ✂︎ --- 参考 --- ✂︎ ---
下記のような地図のスタイルを選択できます。

--- ✂︎ ---

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕