
M-1グランプリ2024をAIで分析してみた

はじめに
機械学習エンジニアをしているNSK(@naohachi89)です。先日で35歳になったのですが、何故か今年になって唐突にお笑いにハマり、昨日は生まれて初めてM-1の決勝をテレビで当日見ました。リアルタイムで見るM-1は想像以上に面白くて、最後まで誰が優勝するのか予想がつかず、結果発表までハラハラドキドキしながらテレビにかじりついていて見ていました(個人的にはバッテリィズが優勝かな〜と思っていたのですが、見事に予想を裏切られました)
M-1を見ながら、同時にXのタイムラインで様々な方々が様々な感想を述べているのを眺めていたのですが、そのときにふと思いました。
「ブロードリスニングの手法を使って、M-1に対してどのような感想が寄せられているのかを可視化したら面白いのではないか?」と。
ブロードリスニングとは、ものすごくざっくり言うと、「テクノロジーの力を使って多くの人々の意見を効率的に把握する手法」です。西尾さんが執筆されたこちらの記事等で解説されているので、詳しく知りたい方はそちらをご覧ください。
今回、ブロードリスニングを実現するOSSであるTalk-to-the-Cityから派生して機能追加を行ったツールを使ってM-1グランプリの結果をAIで分析してみました。(ちなみにこの派生版のツールの開発には私も携わっています)
分析結果
分析した結果は以下にアップしています。
https://m1-2024-tttc.netlify.app/%e3%82%af%e3%83%a9%e3%82%b9%e3%82%bf%e6%95%b020/
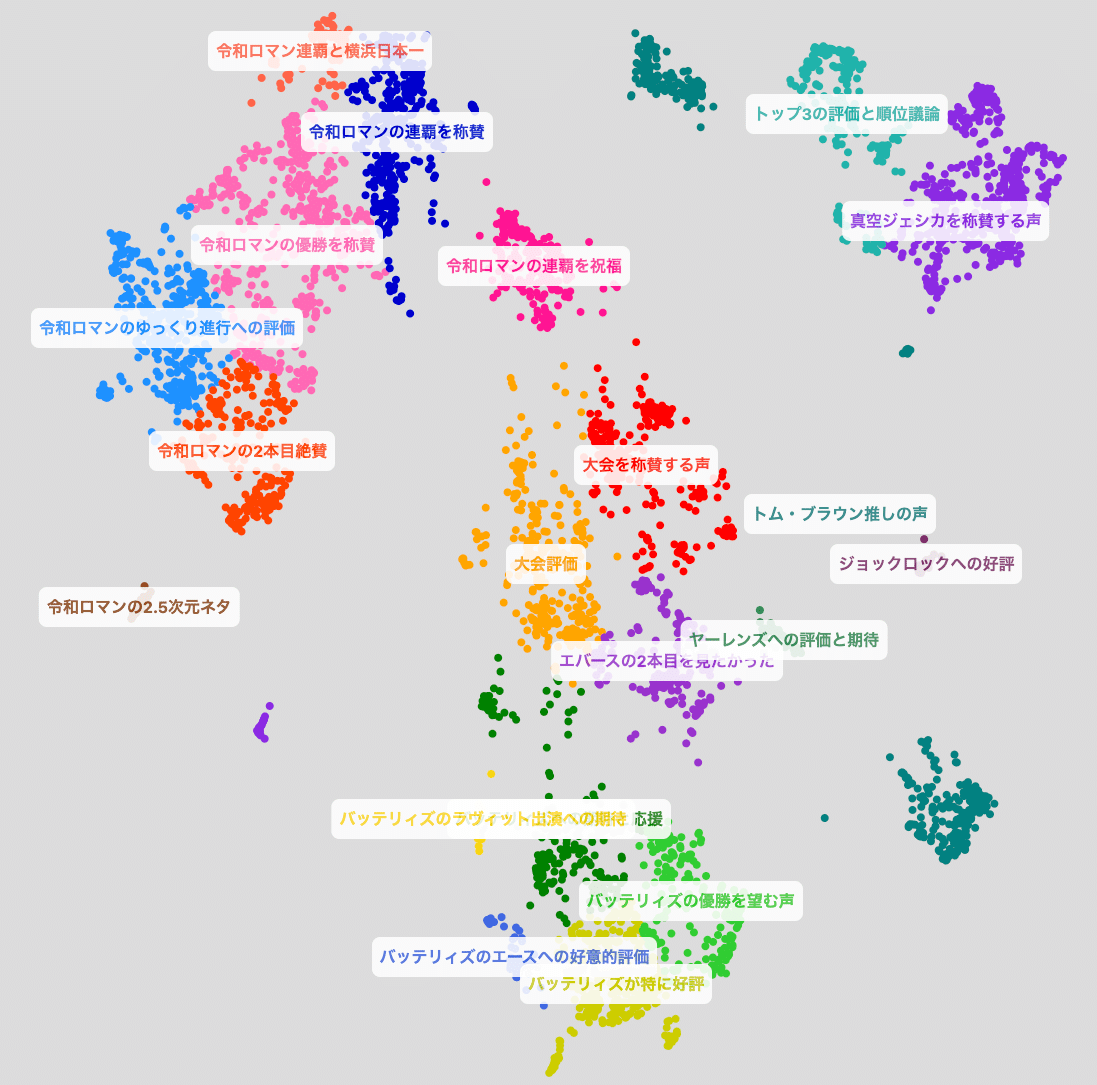
上記のマップは、各意見を二次元平面上にマッピングし、意見のまとまり(クラスタ)を作った上で可視化したものです。
レポート内部には、更に各クラスタの内容を分析した結果も記載してあるので、ご興味がある方はぜひ一度URLを開いて内容をご覧ください!
以下に、レポート中の分析結果を一部抜粋して掲載しておきます。



マップ上では、特定の条件に合致する意見をフィルタリングして表示することもできます。こちらはオリジナルのTalk-to-the-Cityにはない機能で、派生版で実装されたものです(implemented by nishio san)。この機能を使うことで、例えば、画面上部の検索フォームにコンビ名を入力することで特定のコンビについて言及している意見のみを表示できたり、意見のセンチメント(ポジティブ・ネガティブ等の意見の感情)を絞って表示することもできます。こちらの意見のセンチメント分類も、LLMで自動で行っています。

まとめ
このように、レポート上ではLLMが出力した分析結果を閲覧することが出来る他、フィルタリングを使って興味のあるトピックについて深堀りすることもできるので、お笑いファンの方やブロードリスニングに興味を持っていただけた方は、レポート上でぜひ色々操作してみてください!
レポートの前提について
ここからは少し込み入った話になりますが、今回レポート出力を行った際の前提や、LLMを使ってレポート出力していることによる制約について以下に記載しておきます。
データ収集
分析対象の元データはX APIを用いてX上のポストを収集しています
収集対象は、M1の決勝に出場した10組のコンビ名を含むポスト
収集期間は、M1の優勝者発表後
上記のようにデータを収集を収集しているため、ファイナルステージに残った3組について述べたポストが多くなるなど、データに偏りがある点にご注意ください。本当は放送時間中のデータを全て解析したかったのですが、X APIが中々にお高かったので優勝発表後のポストに絞ってレポート出力を行いました。ちなみにポストの取得をAPIで行うにはBasic以上のプランを契約する必要があるのですが、月額$200(=3万円以上)で上限1万5000件程度のツイートしか取得できず、この件数だと優勝発表後の数分程度しかツイートを取得できません。それだけ多くの方がM-1について呟いているということで、改めてM-1の影響力の大きさを思い知らされました。
制約
AIを用いて自動で分析を行っている都合上、幾つか制約があります。
レポートの冒頭にも記載していますが、今回分析対象としたデータはX上のポストであり、またLLM(ChatGPT)を使って解析を行っている都合上、事実だけが記載されているとは限りません
例えばX上のポストに嘘が含まれている場合はその内容が記載されますし、LLMが内容を解釈する過程でハルシネーションが発生する可能性があります
クラスタのタイトルと内部の意見が乖離するなど、レポートにおいて一部品質が高くない部分があります
(こちらは分析実行時時のパラメータを調整することでもう少し改善できる余地はあるのですが、今回はこの部分の調整にそこまで時間を割いていません)
Talk-to-the-Cityはまだまだ発展途上の技術で、銀の弾丸ではありません。
一方で、制約を理解して使えば効率的に意見を把握できるとても便利なツールなので、レポートを閲覧する際は上記のような制約に気をつけてご覧いただけると幸いです。