
AI DJ Project#2 Ubiquitous Rhythm — A Spontaneous Jam Session with AI リアルタイムに音楽生成するAIとの即興演奏

<<< 2021年にQosmoのwebサイトで公開された記事を転載 >>>
PERFORMANCE
OVERVIEW
AI DJ Project#2 Ubiquitous Rhythmは、AIを用いてリアルタイムに音楽を生成しながら行う即興的なDJパフォーマンスです。音楽のシーケンスを事前に用意することなく、その場でAIが作曲(生成)した音楽をDJがコントロールし、AIがそれに反応することで、一連のパフォーマンスが展開していきます。複数のAIモデルとDJが織りなす複雑な相互作用により、意外性に富んだ有機的な音楽体験を生み出すことに成功しました。
今回のパフォーマンスの中で、AIは2小節のリズム(ドラムマシンのパターン)とそれにあったベースラインを生成し続けます。またこのドラムとベースラインにあったループが、総数2万以上の同じく2小節のオーディオファイルの中から選択されます。DJはAIが生成したリズム、ベースラインと選択されたループを聴きながら、その場でドラムマシンやシンセサイザーの音色を調整し、各トラックの音量やオーディオエフェクトなどをコントロールすることで、音楽的な展開を組み立てていきます。また一般的なDJ同様にターンテーブルを使ってレコードをミックスすることもできます。これらがミックスされた音に対して、ぴったりくるであろうリズムのループがAIによって選択され、リズム生成のモデルへの入力として使われることで次のリズムパターンが生成されます。このように複数のAIモデルが相互作用する中にDJが外乱として介入することで、ゆらぎを含んだ音楽生成のフィードバック・ループが生まれました。
こうして生まれたパフォーマンスは、一人のDJだけではほぼ不可能といえるDJの形式(=その場で作曲し続ける)を実現しただけなく、機械を用いながらも前もって予測することが不可能かつ一回性の高い(=同じパフォーマンスは二度と生まれない)非常に即興性の高いパフォーマンスとなりました。演奏する側のDJも次にどのような音楽が再生されるのか、その瞬間瞬間、完全に予想することができません。AIは相対するDJ自身の創造性、音楽性を試すかのように、意外性のある新しいフレーズを繰り出してきます。
DJと複数の音楽生成モデルが相互作用することで生まれるグルーブは、人とAIが共生する新しい時代の創造性のかたちを予見するかのようです。AI DJ Projectの続編として発表した今回のパフォーマンス。結果的にDJはディスク(レコード)ではなく、AIを乗りこなす「AI Jockey」であることを求められました。その先には、おしなべてAI Jockeyたることを求められるであろう、未来のクリエイターの姿が垣間見えたように思います。


BACKGROUND
2015年前後からQosmoでは、人工知能(AI)を用いたDJシステムの開発を始め、『AI DJ Project』として世界各地でパフォーマンスを行ってきました。人間のDJ(主にQosmo代表の徳井)とAIが一曲づつ交互に選曲することで(一般にBack to Backと呼ばれます)、音楽を通して人とAIのまさに「かけ合い」「コミュニケーション」を実現するプロジェクトでした。プロジェクトの背後にある動機としては、何もDJを自動化したいということではなく、AIとして人の行為を模倣することで、DJという行為の本質を探るとともに、人には思いつかない意外性のある選曲をAIを用いて実現しようとする意思がありました。2019年にはGoogle I/Oのキーノートスピーチに招待され、15000を超える観客の前でAI DJを披露する機会にも恵まれました。

それから二年。これまでのAI DJが人のDJの行為の一部をAIに肩代わりさせてみるというチャレンジだったのに対して、今回はどんな人間のDJでも(ほぼ)不可能なこと、できないこと、すなわち、「パフォーマンス中にリアルタイムに作曲し、その場で演奏すること」に、AIの力を借りて実現することに取り組みました。すでにある曲をかけるというDJ行為そのものを再定義しようとする試みとも言えます。
TECHNOLOGY
3つのAIモデル
今回のパフォーマンスの実現にあたっては、次の三つの音楽生成のためのAIモデルが使われています。順に説明します。
リズム生成モデル
リズム→ベース 変換モデル
ループ選択モデル

1. リズム生成モデル (M4L.RhythmVAE for Ableton Live/Max for Live)
リズム生成モデルの概要 — M4L.RhythmVAE for Ableton Live/Max for Live
まずパフォーマンスのコアになるリズム生成のシステムは、DJである徳井が2019年前後から開発してきたソフトウェア・プラグインがベースになっています。人気のある音楽制作用のソフトウェア(DAW)の一つ、Ableton Live用に作られたこのプラグインは、アーティストが音楽データをドラッグ&ドロップするだけで、プログラミングなどの手間をかけることなく独自のリズム生成モデルを学習することを可能にしました。
Variational AutoEncoder(VAE)をベースにしたこのモデルは、複雑なリズムパターンを低次元のベクトル(このプラグインでは二次元ベクトル)に圧縮(エンコーディング)した上で、元のデータを復元(デコーディング)する方法をニューラルネットワークを用いて学習します。一旦学習が終わると、この低次元のベクトルをデコーダに入力することで、様々なリズムが生成されることになります。

また、生成されるパターンの特徴をある程度コントロールできるように、バスドラムやハイハットの密度などをリズム生成の条件として入力できるようにしました。DJはパフォーマンス中にこの条件をコントロールすることで、生成されるリズムを緩やかにコントロールすることが可能です。今回のパフォーマンスでは市販のダンスミュージックのMIDIデータ集に加えて、実験的な電子音楽家たちの楽曲のドラムパターンをMIDIに変換したものを、学習データとして利用しました。
2. リズム→ベース 変換モデル (M4L.Rhythm2Bassline for Ableton Live/Max for Live)
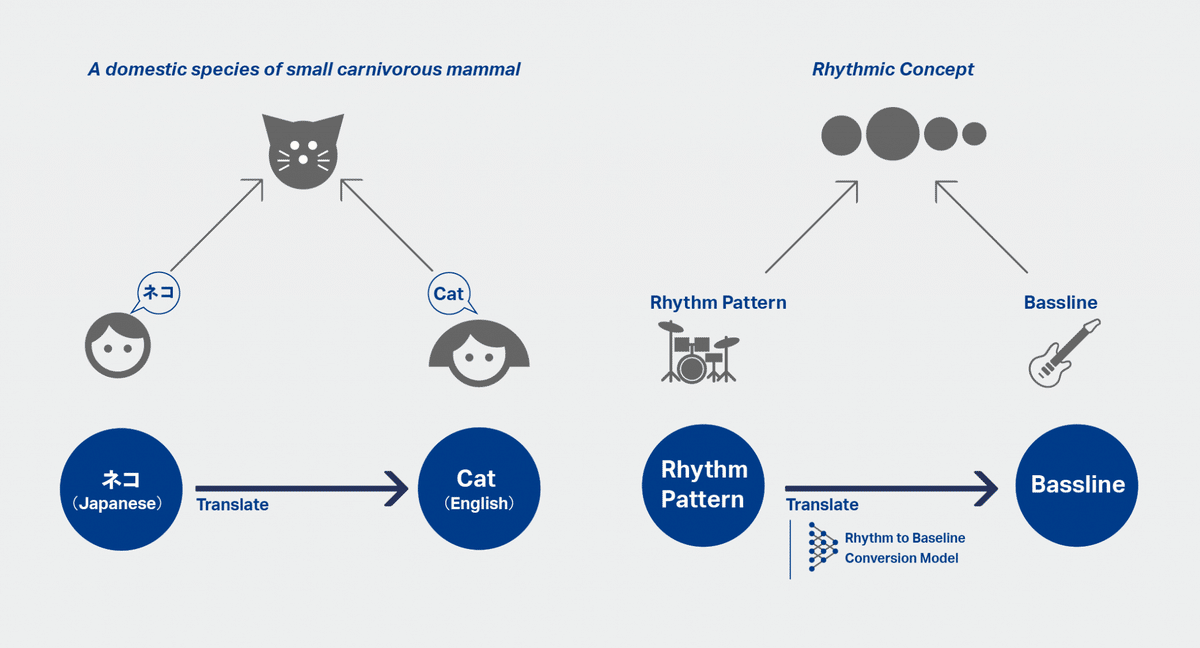
低音のベースラインもドラムのパターンと並んで、ダンスミュージックの楽曲の根幹をなす大事な要素です。ドラムとベースラインで楽曲のグルーブの大半が決定されると言っても過言ではないでしょう。そこで、ドラムのパターンとベースラインは、同じリズムのコンセプト、一つのグルーブを異なる楽器で奏でていると考えることはできないでしょうか。例えば、「ネコ」「Cat」これらが日本語と英語という異なる言語で、どちらもあの愛らしい小さな動物を表現しているようにです。大量にデータを集めることで日本語を英語に翻訳するAIモデルを学習できるのであれば、同様に大量の楽曲のデータを集めることでドラムのパターンをベースラインに「翻訳」するモデルを作ることができるのでは。これが二番目のリズム→ベース変換モデルの元になっている考え方です。
まずMIDIファイルを大量に集めた上で、ドラムとベースが同時に鳴っているパートを抽出しました。その上でドラムのパターンを入力として、そのドラムパターンと同時に鳴っているであろうベースを予測するモデル(LSTMを用いたseq2seqモデル)を学習しています。さらにこうして学習したモデルを、リズム同様にAbleton Liveのプラグインとしてまとめました。
3. ループ選択 Loop Combination Model
こうして生成したリズムとベースに対して、三つ目のモデルは適切なループ(メロディーやボーカルサンプル、サウンドエフェクトなど。DJの言葉でいうといわゆる「ウワモノ」です。)を選択します。例えば、ハウス・ミュージックの四つ打ちには、軽快なシンセリフやファンキーなボーカルサンプルを混ぜるとぴったりくるでしょうし、ロック風の8ビートのリズムにはディストーションのかかったギターリフのほうがあうでしょう。
Ableton Liveなどで曲を作ったことがある人であれば誰しも、大量にあるループの中からどれを選ぶと良いか悩んだ経験があるはずです。この「大量にあるループの中から、リズムとベースにあうループを探す」のが三つ目のモデルの役割です。
このモデルを学習するために、まず最初に大量の楽曲を集め、二小節単位のループを大量に作ります(このプロセスにも機械学習の技術が使われています)。その上で、音源分離の技術を用いて、リズム、ベース、それ以外(ピアノやギターのメロディー等)のトラックを取り出しました。


元々同じ曲から取り出したリズムとベース、ベースとメロディーのペアの組み合わせの相性は良いはずなのに対して(原曲がひどい曲でなければ)、ランダムに二つの曲を選んでそれぞれから取り出したループの組み合わせの相性は保証されていません。時には聞くに耐えない組み合わせになる場合もあります。そこで同じ曲から取り出したループの組み合わせを「良い組み合わせ」、ランダムな曲のペアから取り出したループの組み合わせを「悪い組み合わせ」とし、与えられたペアの相性を予測できるモデルを学習しました (CNNをベースにしたSiamese NetworkをTriplet Lossで学習)。
このモデルがあれば大量にあるループの中から最も相性の良いループを検索することが可能になります。
今回、パフォーマンスで用いたのは、音楽のデータセットとして公開されている楽曲から取り出した「それ以外(メロディー等)」のパート、フィールドレコーディングされたサウンドスケープの音(環境音など)とそこから特に抜き出した人間の声が入った音の三種類の音源セットです。それぞれ上記の機械学習のテクニックを用いて、それらから二小節のループを抜き出して使っています。
Behind the scene — パフォーマンスの裏側
パフォーマンスはランダムにリズムを生成するところから始まります。ベースライン生成(変換)モデルを用いて、リズムにあったベースラインが生成され、リズムとベースをミックスした音にあったループ(ウワモノ)がそれぞれの音源セット(環境音、声、音楽)から選択されます。
DJはターンテーブルを使ってレコードの音をミックスすることができるほか、生成されたシーケンスに合わせてドラムマシンやシンセサイザー(今回はARTURIA DrumBrute ImpactとSEQUENTIAL Prophet 6の二つのアナログ・ドラムマシン/シンセサイザーを利用)の音色を調整することで音楽的展開を作っていきます。また、リズム生成モデルの「条件付け(Conditioning)」の機能を用いて、音数などをコントロールすることでパフォーマンスに大きな流れを作り出すこともできます。こうしたDJの操作は、ループ選択モデルに入力される音に反映されることで、選択されるウワモノの種類にも間接的に影響を与えています。
リズム生成モデルの学習に用いたリズムパターンをあらかじめて音声ファイルとして書き出しておくことで、ループ選択モデルはウワモノを選択するだけでなく、ぴったりくるリズムを選択することもできるようにしました。こうして選択されたリズムパターンは、リズム生成モデルへの入力として使われ、次のリズムの展開をリードしていきます(リズム生成モデルが、エンコーダとデコーダからなるVAEモデルを利用していたことを思い出してください)。
こうして、3つのAIモデルと一人のDJが直接的、間接的に与えあう相互作用とフィードバックループが、生成される音楽に適度な予測不可能性とゆらぎをもたらしました。
今回のパフォーマンスでは、何が起きているのかをなるべくダイレクトに表現するためのインタフェースのレイヤーとビジュアル表現のレイヤーの二つのレイヤーに分けました。AR(Augmented Reality)技術を用いて、DJの目の前の空間に仮想的に表示されるインタフェースには、リズムとベース生成モデルが生成するシーケンスや選択されたループが表示され、刻々とアップデートされていきます。DJの背後には、音楽の展開に合わせて、オーディオを可視化するビジュアルが表示され、パフォーマンスの雰囲気を高めています。(ARを用いた表現はDentsu Craft Tokyoのテクニカルチームによるものです。)




参考文献
[1] リズム生成モデル (M4L.RhythmVAE for Ableton Live/Max for Live)
[2] リズム→ベース 変換モデル (M4L.Rhythm2Bassline for Ableton Live/Max for Live)
[3] ループ選択 (Loop Combination Model)
Credit
Machine Learning & Performance: Nao Tokui (Qosmo, Inc.)
Visual Programming: Shoya Dozono (Qosmo, Inc.)
Visual Research: Ryosuke Nakajima (Qosmo, Inc.)
AR System: Hiroyoshi Murata (Dentsu Creative X, Inc.), Yuki Tanabe (Dentsu Creative X, Inc.)
Videographer: Sota Suzuki (Dentsu Creative X, Inc.)
Producer: Ryotaro Omori (Dentsu Creative X, Inc.)
Logo Design: Naoki Ise (Qosmo, Inc.)