
BLACKPINKのメンバーを画像判定【Aidemy成果物】

2023年6月29日 追記
スクレイピングの関係でデザインを一部変更したので完成画像を差し替えました。黒い点とフッターの背景色がうまく変更できておりませんが、今後再挑戦します。
自己紹介ときっかけ
現在は、事務の仕事をしています。
何かスキルを身に着けて仕事をしたいと思い、興味のあったAI開発の道へ行こうと決意。独学でpythonなどを学びましたが、何か作品を作るまでには至らず、思い切ってAidemy Premium Planの「AIアプリ開発コース3か月」を受講しました。
概要
テーマについては、興味のあった画像認識を選択し、好きなアイドルの顔判定アプリを作成することにしました。アイドルの人数が多すぎても画像集めなどで苦労しそうでしたので、4人組のBlackPinkのメンバーをAIで顔判定することにしました。
実行環境
Windows11
Python 3.11.4
Google Colaboratory
Visual Studio Code 2022
#ライブライインポート
!pip install icrawler
!pip install keras
!pip install tensorflow
!pip install h5py
from icrawler.builtin import GoogleImageCrawler,BaiduImageCrawler, BingImageCrawler
import os, glob
import random
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Input, Sequential, Model
from tensorflow.keras.models import load_model, save_model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D,Input
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from tensorflow.keras.applications.vgg19 import VGG19
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.optimizers import SGD, Adam
from tensorflow.keras import optimizers
from google.colab import files
from tensorflow.keras.callbacks import EarlyStopping画像収集
収集方法
メンバーの顔画像は、icrawlerを利用して350枚収集しました。350枚と設定しましたが、実際にはそれの半分ぐらいしか保存されていませんでした。
keywords = ["BlackPink_Jennie","BlackPink_Jisoo","BlackPink_Lisa","BlackPink_Rose"]
max_num = 350
for keyword in keywords:
crawler=BingImageCrawler(storage={'root_dir':'drive/MyDrive/seikabutu/img_' + keyword})
crawler.crawl(keyword = keyword, max_num=max_num)
画像精査(顔検出と画像の分割)
顔の検出を行い、Google Driveに保存された画像を目視で精査していきます。
判断基準としては、複数人写りこんでいる、物や髪の毛等で顔の一部が隠れてしまっている、重複して保存されている画像、半目だったり完全に横向きになっている顔等は除外しました。
この時点で画像は平均して172枚になりました。
メンバー間で収集画像枚数にばらつきがあっても良いか聞いたところ、数枚程度ならそんなに問題にならないとのことでしたので、そのまま進めました。
#カスケード分類器
HAAR_FILE="/content/drive/MyDrive/seikabutu/haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(HAAR_FILE)
#画像サイズ
image_size=150
names = ["img_BlackPink_Jennie","img_BlackPink_Jisoo","img_BlackPink_Lisa","img_BlackPink_Rose"]
for name in names:
# 入力する画像ファイルのディレクトリ
output_path = "/content/drive/MyDrive/seikabutu/{}/".format(name)
# 顔の切り抜きが成功した時に出力するディレクトリ
file_1 = "/content/drive/MyDrive/seikabutu/{}_face_true/".format(name)
# 顔の切り抜きが失敗した時に出力するディレクトリ
file_2 = "/content/drive/MyDrive/seikabutu/{}_face_false/".format(name)
# 画像のフォルダ作成、読み込み
file_list = glob.glob(output_path + "{}*.jpg".format(name))
os.makedirs(file_1)
os.makedirs(file_2)
print(os.listdir(output_path))
for filename in os.listdir(output_path):
print(output_path + filename)
#img = cv2.imread(filename)
img = cv2.imread(output_path + filename)
# 画像が読み込めない場合
if img is None:
print(filename)
print()
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
face= cascade.detectMultiScale(img_gray, minSize=(150, 150))
# 顔の切り抜きを実行し、画像ファイルを保存
if len(face) >0:
for x,y,w,h, in face:
image=img[y:y+h,x:x+w]
cv2.imwrite(file_1 + "{}_{}".format(name,str(filename)),image)
else:
# 顔の切り抜きができなかった時はそのまま保存
cv2.imwrite(file_2+"{}_{}".format(name,str(filename)),img)
#画像の分割
import shutil
names = ["img_BlackPink_Jennie","img_BlackPink_Jisoo","img_BlackPink_Lisa","img_BlackPink_Rose"]
path="/content/drive/MyDrive/seikabutu/"
for name in names:
os.makedirs("{}{}_test".format(path,name),exist_ok=True)
files =glob.glob(os.path.join("{}{}_face_true/*jpg".format(path,name)))
random.shuffle(files)
for i in range(len(files)//4):
shutil.move(str(files[i]),"{}{}_test".format(path,name))
画像の水増し
収集画像が少なかったので、画像の水増しを行ないました。
names = ["img_BlackPink_Jennie","img_BlackPink_Jisoo","img_BlackPink_Lisa","img_BlackPink_Rose"]
path="/content/drive/MyDrive/seikabutu/"
#水増し手法
def scratch_image(img,thr=True,filt=True,resize=True,rotate=True):
methods = [thr,filt,resize,rotate]
img_size=img.shape
filter1=np.ones((3,3))
size=tuple([int(img_size[0]/2),int(img_size[1]/2)])
mat = cv2.getRotationMatrix2D(size, 15, 1.0)
#オリジナル画像データを配列に格納
images=[img]
#print(images)
#手法に用いる関数
scratch =np.array([lambda x:cv2.threshold(x,100,255,cv2.THRESH_TOZERO)[1],
lambda x:cv2.GaussianBlur(x,(3,3),0),
lambda x:cv2.resize(cv2.resize(x,(img_size[1]//2,img_size[0]//2)),(img_size[1],img_size[0])),
lambda x:cv2.warpAffine(x,mat,img_size[::-1][1:3])
])
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
# methodsがTrueの関数で水増し
for func in scratch[methods]:
images = doubling_images(func, images)
return images
for name in names:
os.makedirs("{}{}_train".format(path,name),exist_ok=True)
files=glob.glob(os.path.join("{}{}_face_true/*".format(path,name)))
for i,filename in enumerate(files,start=1):
img=cv2.imread(filename)
images_list=scratch_image(img)
output_path="{}{}_train".format(path,name)
for v, img in enumerate(images_list,start=1):
cv2.imwrite("{}/{}_{}_{}.jpg".format(output_path,name,str(i),str(v)),img)モデルの作成と学習
今回はVGG16を利用して転移学習しました。
from google.colab import files
names = ["img_BlackPink_Jennie","img_BlackPink_Jisoo","img_BlackPink_Lisa","img_BlackPink_Rose"]
path="/content/drive/MyDrive/seikabutu/"
X_train = []
X_test = []
y_train = []
y_test = []
#学習データ・テストデータをリストに代入
for i,name in enumerate(names):
files=glob.glob(os.path.join(path + name + "_train/*jpg"))
print(files)
for file in files:
image = load_img(file)
image=img_to_array(image)
image = cv2.resize(image,dsize=(150,150))
X_train.append(image)
y_train.append(i)
for i,name in enumerate(names):
files=glob.glob(os.path.join(path + name+ "_test/*jpg"))
for file in files:
image = load_img(file)
image = img_to_array(image)
image = cv2.resize(image,dsize=(150,150))
X_test.append(image)
y_test.append(i)
#学習データ・テストデータをシャッフル
tr =list(zip(X_train,y_train))
print(tr)
random.shuffle(tr)
X_train,y_train = zip(*tr)
te = list(zip(X_test,y_test))
random.shuffle(te)
X_test,y_test = zip(*te)
#Numpy配列に変換
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
#正解ラベルをOne-hot形式に変換
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの定義
input_tensor = Input(shape=(150,150,3))
vgg16 = VGG16(include_top=False,weights="imagenet",input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256,activation="sigmoid"))
top_model.add(Dense(128,activation="sigmoid"))
top_model.add(Dense(4,activation="softmax"))
model = Model(inputs = vgg16.input, outputs = top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=optimizers.SGD(lr=1e-4,momentum=0.9),metrics=["accuracy"])
history = model.fit(X_train,y_train,batch_size=32,epochs=50,verbose=1,validation_data=(X_test,y_test))
model.save('saved_model/model.h5')
#精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
#グラフを作成
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax = fig.add_subplot(1,2,1)
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
ax.plot(range(epochs), loss, marker = '.', label = 'loss')
ax.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
ax.legend(loc = 'best')
ax.grid()
ax.set_xlabel('epoch')
ax.set_ylabel('loss')
accuracy=history.history['accuracy']
val_accuracy=history.history['val_accuracy']
epochs=len(accuracy)
ax2 = fig.add_subplot(1,2,2)
ax2.plot(range(epochs), accuracy, marker = '.', label = 'accuracy')
ax2.plot(range(epochs), val_accuracy, marker = '.', label = 'val_accuracy')
ax2.legend(loc = 'best')
ax2.grid()
ax2.set_xlabel('epoch')
ax2.set_ylabel('accuracy')
plt.show()
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' )
画像は150x150にリサイズし学習回数は50回にしました。
WEBサイド作成
HTML/CSS
HTMLとCSSでレイアウトを作成していきます。
ベースはAidemyの講座で取り扱ったもの、卒業生の方のを参考に色や画像は自分の好みに変更しました。仕上がりを確認しながら進めたかったので、Codepenというサイトにコードを入力しながら作成しました。
Flask
学習したモデルを使い、アップロードした画像のメンバーが誰なのかを判定するFlaskサイドを制作します。
import os
import base64
import numpy as np
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential,load_model
from tensorflow.keras.preprocessing import image
classes = ['Jennie', 'Jisoo', 'Lisa', 'Rose']
image_size = 150
UPLOAD_FOLDER = 'uploads'
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5',compile=False)
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('No file')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('No file')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
print(filepath)
#受け取った画像を読み込みnp形式に変換
img = image.load_img(filepath, target_size=(image_size, image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = 'This member is ' + classes[predicted] + '.'
return render_template('index.html',answer=pred_answer)
return render_template('index.html',answer='')
#return render_template('index.html',answer='')
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
model.h5の容量が大きすぎてGithub LFSを利用してアップロードしたり、renderへのデプロイがなかなかうまくいかず苦戦しました。
画面確認

Google画像でblackpinkと検索し、一人で写っている画像を使い確認します。
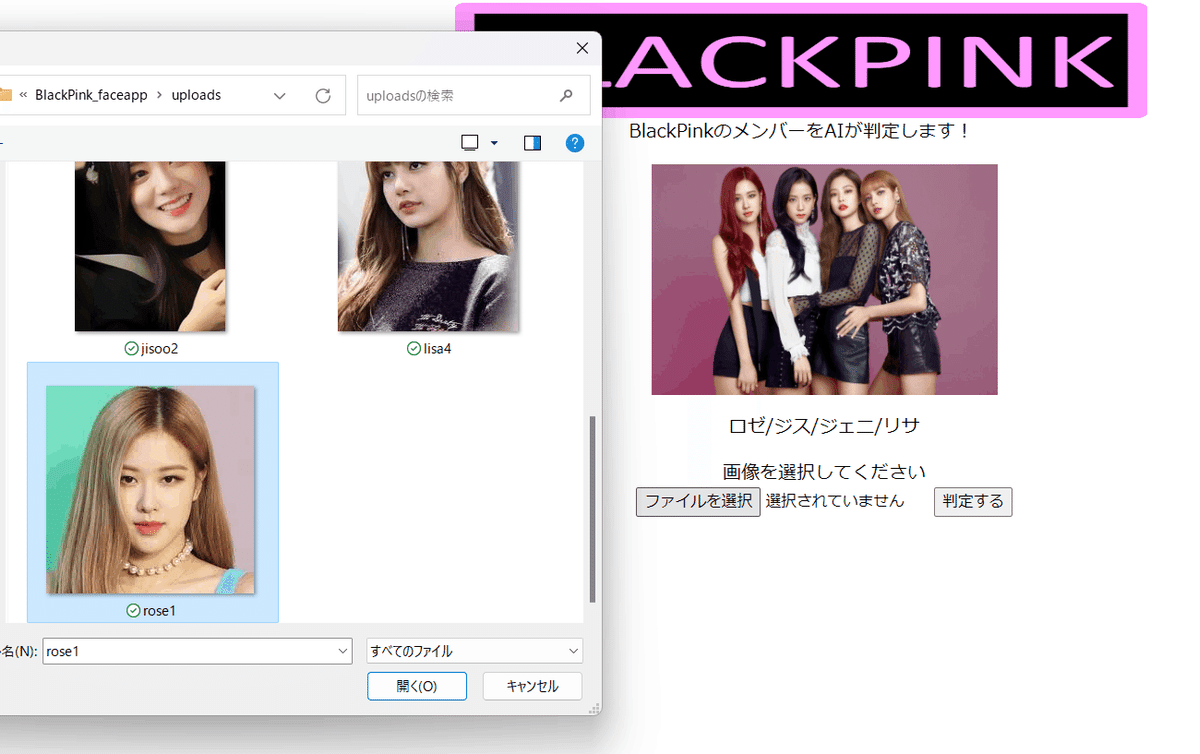

何度か画像を変えて試しましたが、「Rose」の判定が多くなってしまいます。精度が65%でしたので判定にばらつきが見られたのではないでしょうか。収集画像枚数を増やす、画像サイズを200にする、複数あるKerasのモデルをいくつか試してみて精度が上がるものを採用しても良かったと思います。
モデル作成までは順調に進んでいたのですが、Flaskの作成や、Renderへのデプロイで数日要してしまうなど思いもよらぬところで苦戦しました。PCのバージョン確認や、最新の情報を調べてから取り組むべきだと思いました。
まとめ
AIアプリ開発コースを3か月受講してみて、わからない所をチューターの方に聞けたのは非常に良かったと思います。早朝や夜遅くに学習することが多かったので、なかなか技術カウンセリングを活用できず、勿体なかったと今になって思います。自分で調べることも大事ですが、わかりやすく説明して下さり、その場で疑問に感じた事をすぐに聞ける環境があったのは良かったです。
成果物に取り組むことで、講座内で曖昧だったところがこのことか!と気づけたり、復習の機会となりしっかり身に付いて良かったと思います。