
C言語でハフマン符号化実装してみた

はじめに
どーも、たまちゃんです。みなさんハフマン符号化ってご存じですか?タフマンではなくハフマンです。情報理論について学ぶとき必ず通る情報源符号化の一つの手段ですね。文字の出現頻度に応じてその文字を表現するビット長を変えることでデータ圧縮を行う。木構造をボトムアップ式に作っていくあれです。軽く解説するので、知ってるよって人は飛ばしておっけい。
ハフマン符号化の手順とか
今回はわかりやすくするためにアルファベットを4つだけ使います。それぞれをビットで表し区別しようとすると、

4種類の文字を2進法で区別するのでこんな感じに表せます。これをハフマン符号化していきます。
各アルファベットとその出現割合をセットにしたノードを作り、重み最小2つのノードを選んで両者を子に持つ木を作る。そしてこの木の重みを2つの子の重みの和とする。これを1つの木になるまで繰り返すと完成です。文字読むより図を見たほうがこれは早いですね。

符号化結果は根から各アルファベットまでたどって0と1を回収していけばいいので、

こうなりますね。
出現確率が低い文字を長く符号化し、高い文字を短く符号化することで、文章全体をより短い文字数で表すことができます。これがハフマン符号化の手順。
それで作ったコードをご紹介。ポインタと構造体を使ってみるとても良い練習になりました。
コード全体
まずはコード全体を載せておきます。ド素人のコードなのでツッコミどころがあるかもしれませんが優しくしてくださいお願いしますなんでもしますから。
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <math.h>
#include <stdbool.h>
int count_alp(char* text, int length, int* count){
char alphabet[26] = {'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
for (int i=0; i<26; i++){
count[i] = 0;
}
for(int i=0; i<length; i++){
text[i] = tolower(text[i]);
for (int j=0; j<26; j++){
if (text[i] == alphabet[j]){
count[j]++;
break;
}
}
}
}
int ratio_alp(int* count, double* ratio){
int sum = 0;
for(int i=0; i<26; i++){
sum = sum + count[i];
}
for(int i=0; i<26; i++){
ratio[i] = (double)count[i]/sum;
}
printf("This text has %d characters\n", sum);
}
double entropy_alp(double* ratio){
double entropy = 0;
for (int i=0; i<26; i++){
if (ratio[i] != 0){
entropy = entropy - ratio[i]*log2(ratio[i]);
}
}
return entropy;
}
typedef struct node{
struct node* parent;
int zeroone;
char alp;
double ratio;
}Node;
int main(void){
FILE *fp;
int c;
char fname[] = "text.txt";
fp = fopen(fname, "r");
if(fp == NULL){
printf("Such file is not found.\n");
return -1;
}
else{
printf("The file is opened.\n");
}
int n = 0;
while (fgetc(fp) != EOF){
n++;
}
fseek(fp, 0, SEEK_SET);
char* buf = (char *)malloc((n+1)*sizeof(char));
char* bp = buf;
while((c = fgetc(fp)) != EOF){
*bp = (char)c;
bp++;
}
*bp = '\0';
int count[26];
count_alp(buf, n, count);
double ratio[26];
ratio_alp(count, ratio);
double entropy = entropy_alp(ratio);
printf("Entropy is %lf.\n", entropy);
//各アルファベットのノードを作成
char alphabet[26] = {'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
Node* address_list[26];
for (int i=0; i<26; i++){
address_list[i] = malloc(sizeof(Node));
address_list[i]->parent = NULL;
address_list[i]->zeroone = -1;
address_list[i]->alp = alphabet[i];
address_list[i]->ratio = ratio[i];
}
Node* address_leaflist[26];
for (int i=0; i<26; i++){
address_leaflist[i] = address_list[i];
}
for(int times=1; times<26; times++){
//確率が最も小さい2つのノードを見つける
double min = 1, secmin = 1;
int min_address_index , secmin_address_index;
for(int i=0; i<26;i++){
if(address_list[i] != NULL)
if (address_list[i]->ratio < secmin){
if(address_list[i]->ratio <= min){
secmin = min;
secmin_address_index = min_address_index;
min = address_list[i]->ratio;
min_address_index = i;
}
else{
secmin = address_list[i]->ratio;
secmin_address_index = i;
}
}
}
//符号化結果を格納。
address_list[min_address_index]->zeroone = 0;
address_list[secmin_address_index]->zeroone = 1;
//新しいノードの作成と古いノードの内容を一部更新
Node* new_Node = malloc(sizeof(Node));
new_Node->parent = NULL;
new_Node->alp = NULL;
new_Node->zeroone = -1;
new_Node->ratio = address_list[min_address_index]->ratio + address_list[secmin_address_index]->ratio;
address_list[min_address_index]->parent = new_Node;
address_list[secmin_address_index]->parent = new_Node;
address_list[min_address_index] = new_Node;
address_list[secmin_address_index] = NULL;
}
//ノードをわたっていって符号語を求める
int code_length[26];
for(int i=0; i<26; i++){
printf("%c: ", alphabet[i]);
if (ratio[i] == 0){
printf("The character does not appear.\n");
continue;
}
int rev[26];
for(int j=0; j<26; j++){
rev[j] = -1;
}
Node* tmp;
tmp = address_leaflist[i];
int count = 0;
while(true){
rev[count] = tmp->zeroone;
tmp = tmp->parent;
if(tmp == NULL) break;
count++;
}
code_length[i] = count;
count--;
while(0<=count){
printf("%d", rev[count]);
count--;
}
printf("\n");
}
//平均符号語長を求める
double average_code_length = 0;
for(int i=0; i<26; i++){
average_code_length = average_code_length + ratio[i]*(double)code_length[i];
}
printf("Average_code_length is %lf.\n", average_code_length);
free(buf);
fclose(fp);
}まずはプログラムの流れを考える
私はコードを書き始める前は、何をやりたいのか、そのためにはどのような手順で処理を行えば実現できるのか、そのために必要なデータやデータ構造は何なのか、の3つを考えるようにしています。そうすればこんがらがらずにコーディングができますからね。
今回やりたいのはアルファベットのハフマン符号化。ただそれを実装できればいいです。ハフマン符号化の手順は上記した通りで、それを手作業で行うのと同じようにプログラムで表現できないか考えていきます。やっていることを大まかに表すと、
①各アルファベットに対応したノードを作り、それが全て一つの木構造の中に入るまでノード同士を統合し新しいノードを作成する。
②木をたどって符号化結果を得る。
この二つです。
さらにその二つの細かい手順を見ていくと、
①
(i)統合対象ノードから出現割合が最低、最低から二番目の物を見つける。
(ii)その二つを統合した親ノードを作る。
(iii)統合させたノードを統合対象からはずす。
これを25回繰り返す。
②
(i)葉ノードの親を、符号化結果を得ながらたどる。
(ii)親が無いノードまで言ったらそれがルートノードだから符号化結果を出力。
これを各アルファベットについて繰り返す。
って感じですね。
ではこれを行うために必要なデータを考えていきます。
考えられるのは
符号化対象英文(char*)とその長さ(int)。
文章に現れる各アルファベットの数(int list)。
そこから得られる各アルファベットの出現確率(double list)。
もう一つが各ノードを表す構造体(Node)です。
そしてこの構造体は要素として、
親ノードへのポインタ(Nodeへのポインタ)。
符号化結果(0か1)。
出現割合(double)。
あとは葉ノードであればアルファベット(char)の4つを持てばよさそう。
データの取得の準備とデータ構造の定義
とゆうわけでまずはその必要なデータとやらを得ていきます。それを実現するのが以下の部分。
int count_alp(char* text, int length, int* count){
char alphabet[26] = {'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
for (int i=0; i<26; i++){
count[i] = 0;
}
for(int i=0; i<length; i++){
text[i] = tolower(text[i]);
for (int j=0; j<26; j++){
if (text[i] == alphabet[j]){
count[j]++;
break;
}
}
}
}
int ratio_alp(int* count, double* ratio){
int sum = 0;
for(int i=0; i<26; i++){
sum = sum + count[i];
}
for(int i=0; i<26; i++){
ratio[i] = (double)count[i]/sum;
}
printf("This text has %d characters\n", sum);
}
double entropy_alp(double* ratio){
double entropy = 0;
for (int i=0; i<26; i++){
if (ratio[i] != 0){
entropy = entropy - ratio[i]*log2(ratio[i]);
}
}
return entropy;
}
typedef struct node{
struct node* parent;
int zeroone;
char alp;
double ratio;
}Node;
int main(void){
FILE *fp;
int c;
char fname[] = "text.txt";
fp = fopen(fname, "r");
if(fp == NULL){
printf("Such file is not found.\n");
return -1;
}
else{
printf("The file is opened.\n");
}
int n = 0;
while (fgetc(fp) != EOF){
n++;
}
fseek(fp, 0, SEEK_SET);
char* buf = (char *)malloc((n+1)*sizeof(char));
char* bp = buf;
while((c = fgetc(fp)) != EOF){
*bp = (char)c;
bp++;
}
*bp = '\0';・関数count_alp → 英文とその長さを与えると、文章に現れる各アルファベットの数(int list)を変数countに返す。
・関数ratio_alp →文章に現れる各アルファベットの数(int list)を与えると、各アルファベットの出現確率(double list)を変数ratioに返す。
・関数entropy_alp →各アルファベットの出現確率からそのエントロピーを返す。
・構造体Node→親ノードへのポインタparent(Nodeへのポインタ)、符号化結果zeroone(int)、出現割合ratio(double)、アルファベットalp(char)を持つ。
・main内の最初→ファイルから英文を取り出してそれをbuf(char*)、その長さn(int)に格納。
これで必要なデータとデータ構造を得ることができますので、ここからはこれを用いてハフマン符号化のアルゴリズムを実現していきます。
アルゴリズムの実装
まずは上記の"①木の作成"を行っていきます。それがコードの以下の部分。
int count[26];
count_alp(buf, n, count);
double ratio[26];
ratio_alp(count, ratio);
double entropy = entropy_alp(ratio);
printf("Entropy is %lf.\n", entropy);
//各アルファベットのノードを作成
char alphabet[26] = {'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'};
Node* address_list[26];
for (int i=0; i<26; i++){
address_list[i] = malloc(sizeof(Node));
address_list[i]->parent = NULL;
address_list[i]->zeroone = -1;
address_list[i]->alp = alphabet[i];
address_list[i]->ratio = ratio[i];
}
Node* address_leaflist[26];
for (int i=0; i<26; i++){
address_leaflist[i] = address_list[i];
}
for(int times=1; times<26; times++){
//確率が最も小さい2つのノードを見つける
double min = 1, secmin = 1;
int min_address_index , secmin_address_index;
for(int i=0; i<26;i++){
if(address_list[i] != NULL)
if (address_list[i]->ratio < secmin){
if(address_list[i]->ratio <= min){
secmin = min;
secmin_address_index = min_address_index;
min = address_list[i]->ratio;
min_address_index = i;
}
else{
secmin = address_list[i]->ratio;
secmin_address_index = i;
}
}
}
//符号化結果を格納。
address_list[min_address_index]->zeroone = 0;
address_list[secmin_address_index]->zeroone = 1;
//新しいノードの作成と古いノードの内容を一部更新
Node* new_Node = malloc(sizeof(Node));
new_Node->parent = NULL;
new_Node->alp = NULL;
new_Node->zeroone = -1;
new_Node->ratio = address_list[min_address_index]->ratio + address_list[secmin_address_index]->ratio;
address_list[min_address_index]->parent = new_Node;
address_list[secmin_address_index]->parent = new_Node;
address_list[min_address_index] = new_Node;
address_list[secmin_address_index] = NULL;
}まず関数count_alpと関数ratio_alpを実行し、変数count,ratioを得ます。ついでにエントロピーを計算して出力。
次に①を始めるために、各アルファベットのノードを作成。①内での繰り返しにおいて、統合対象となるノードを格納するaddress_listとは別に、②で葉ノードから符号化結果をたどるために、葉ノードへのポインタを持つaddress_leaflistも別に作っておきます。
そしてここから①がスタート、統合対象となるノードの中から、出現割合が最も小さい2つのノードを見つけます。多くても26ノードなので線形探索で行っています。ここで出現割合最小と二番目に最小であるノードの出現割合の値と、それがaddress_listの何番目のノードなのかを得ておきます。そして統合対象となったノードに符号化結果(0or1)を格納。
統合対象となるノードが決まったので、新しいノードを作成し、必要なくなったノードをaddress_listから除外します。具体的には、新ノードのratioは元となったノードのratioの和とすること、元となったノードのparentを新ノードへのポインタとすること、address_listから元となった2つのノードを消し、新たに新ノードを加えること。を主に行います。
以上が①の内容。これを25回繰り返せば、最初に作った各アルファベットのノードが全て1つの木の中に納まります。
次に②の内容。
//ノードをわたっていって符号語を求める
int code_length[26];
for(int i=0; i<26; i++){
printf("%c: ", alphabet[i]);
if (ratio[i] == 0){
printf("The character does not appear.\n");
continue;
}
int rev[26];
for(int j=0; j<26; j++){
rev[j] = -1;
}
Node* tmp;
tmp = address_leaflist[i];
int count = 0;
while(true){
rev[count] = tmp->zeroone;
tmp = tmp->parent;
if(tmp == NULL) break;
count++;
}
code_length[i] = count;
count--;
while(0<=count){
printf("%d", rev[count]);
count--;
}
printf("\n");
}
//平均符号語長を求める
double average_code_length = 0;
for(int i=0; i<26; i++){
average_code_length = average_code_length + ratio[i]*(double)code_length[i];
}
printf("Average_code_length is %lf.\n", average_code_length);
free(buf);
fclose(fp);
} 各葉ノード(address_leaflistに格納されている)から、ノードのzerooneを取得していきながら親ノードをたどっていっています。親ノードがNULLだったら符号化結果は得られているので、これでハフマン符号化は完了です。
ただし、ルートノードから符号化したいアルファベットまでのルートを辿った結果を符号化結果としたいので、親を辿っていって得られたものを逆順に出力するようにしています。ハフマン符号化についての記事とか見ると親からたどったものを結果としているので、それに合わせただけです。多分そんなことしなくても符号化はできてるんじゃないかな。確証もてないからこうした気がします。
んで最後に平均符号語長を出力しておしまい!普段は8ビットで表しているアルファベットが一体何ビットで表せるようになったかな!?
実行してみた
実際に以下のニュース記事に対して実行した結果がこちら。
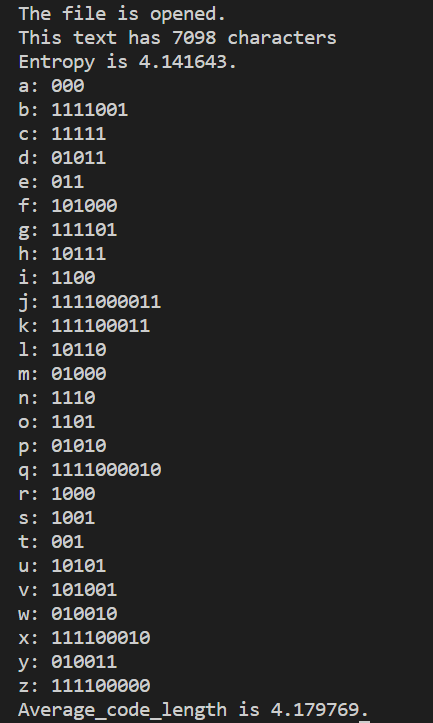
英単語でよく出てくるaとかeは短く、あんま出てこないqとかxは長くなっててよさそうですね。あと、「平均符号語長>=エントロピー」を満たしており、情報源符号化定理に反していないこともわかります。
とゆーわけでハフマン符号化の実装完了!拙いコードかもしれませんが参考にしてみてください。