
転生したら写真から人物の顔を切り抜くアプリを作ってみた件について

はじめに
こんにちは!Pythonを学び始めて2カ月目の初心者ですが、今回、学んだ知識を活かして初めてのWebアプリを作成しました。アウトプットを兼ねて、私のプロジェクトを紹介したいと思います。
どんなWebアプリ?
その名も「顔切り抜きくん」です。このアプリは、アップロードされた画像の中から顔を自動で検出し、その部分だけを切り抜いて保存することができる便利ツールです。自分好みのアイコンや素材が簡単に作れるので、ちょっとした遊びにも、クリエイティブな用途にもぴったりです。
こちらがそのアプリとgitになります
https://github.com/nankotu11011011/This-is-Final-War.git
https://mysite-tqni.onrender.com/
使ったフレームワーク:Django
今回、WEBアプリの開発にはDjangoを使いました。正直言って、このアプリ自体には「絶対にDjangoでなければいけない!」という深い理由があったわけではありません。でも、データベースへのアクセスが簡単だったり、Flaskと比べてできることが多彩だったりと、将来性を考えてDjangoを学びたいと思ったんです。
Djangoは、特にデータベースとの連携がスムーズで、ORM(オブジェクトリレーショナルマッピング)を使って、データベースの操作をPythonのコードで直感的に行えるのが魅力です。また、プロジェクトの拡張性が高いので、いろいろな機能を追加していくのも簡単。これから本格的なWeb開発を進めていく上で、Djangoのスキルは役に立つだろうな、と考えました。
こちらが「顔切り抜きくん」のUIです!見た目はシンプルで、誰でも直感的に使えるデザインを意識しました。
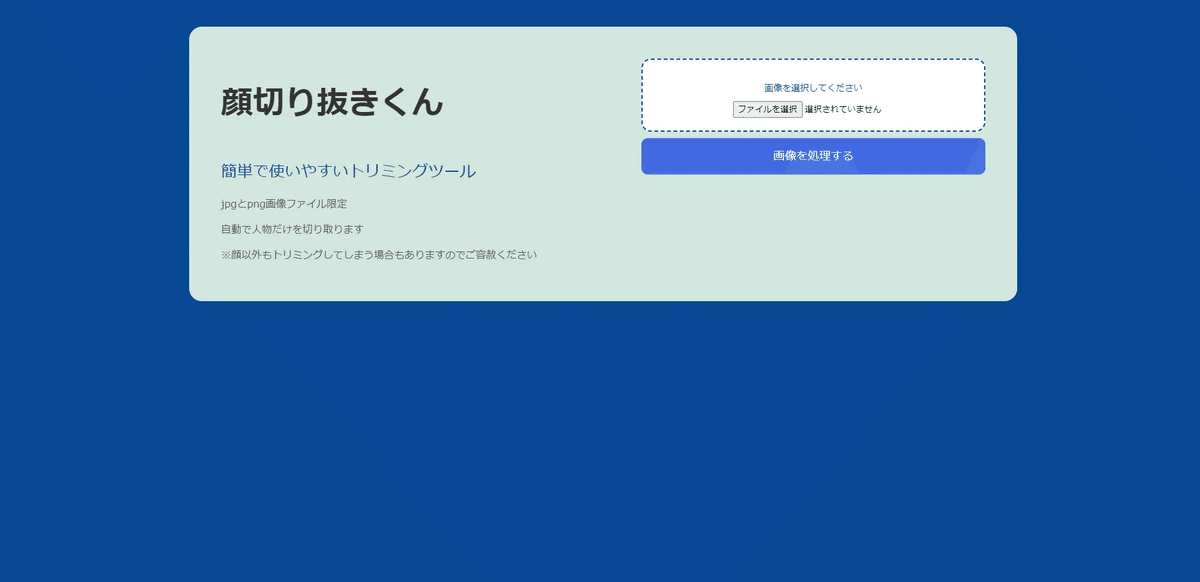
画面の左側には「顔切り抜きくん」のタイトルと簡単な説明が書いてあって、「このツールは何をしてくれるの?」っていうのがすぐにわかるようになっています。右側には、画像をアップロードするエリアがあります。ここで「ファイルを選択」ボタンを押して、切り抜きたい顔が含まれている画像を選んでから、「画像を処理する」ボタンをクリックするだけ。これで自動的に顔を検出して切り抜いてくれます!
試しに使ってみましょう
今回使う画像はこちら

人間の女性とトラですね。これを上記の手順に沿って処理します

はい、できましたね。あとこれを見ていただきたい
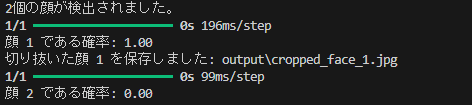
処理結果を見ていただくと2個の画像が検出されていますね、検出された顔が本当に顔であるかを学習させたモデルに判断してもらってます。
顔検出の簡単な流れ
「顔切り抜きくん」の仕組みは、ざっくり言うと二段階の認識プロセスになっています。まず、OpenCVの顔検出器を使って、画像の中から顔っぽい部分を見つけ出します。でも、それだけだと精度がイマイチなんです。なので、見つけた顔をもう一度、学習させたモデルで「本当にこれが顔かどうか」を最終チェックします。
「二段階認識って必要なの?」と思うかもしれませんが、実際に使ってみると、OpenCVの顔検出器だけでは時々「これは顔じゃないでしょ!」ってものまで顔と認識しちゃうことがあります。例えば、動物の顔とか、影とか、顔に見えるものを検出してしまうことがあるんです。
だからこそ、再度モデルに確認してもらうことが大事だと考えました。モデルに最終的な判断を任せることで、より正確な顔認識ができるようになっています。これは上記の処理結果を見てもらうと、「なるほど、確かに!」と思ってもらえるんじゃないかなと思います。
プロジェクトの構成
IMAGE_app
├── background_removal_app
│ ├── data #学習用データを収納するディレクトリ
│ │ ├── faces #顔データ
│ │ └── non_faces #非顔データ
│ ├── models #モデルを収納するディレクトリ
│ │ └── face_detection_model.h5 #モデル
│ └── src #学習や実行テストを行うディレクトリ
│ ├── _pycache_
│ ├── output #テスト結果を収納するディレクトリ
│ ├── predict.py #テストのためのファイル
│ ├── train.py #学習の実行
│ └── training_history.png
└── image_app
├── _pycache_
├── __init__.py
├── asgi.py
├── forms.py #画像アップロードフォームの定義
├── settings.py
├── urls.py #URLとviews.pyを繋ぐ定義
├── views.py #実行
├── wsgi.py
├── templates #HTMLテンプレートが格納されるディレクトリ
│ └── index.html # UI
└── db.sqlite3
└── manage.py実行手順に関するファイルの説明
まず、プロジェクトを実行するためのファイルやディレクトリについてご紹介します。これらは「顔切り抜きくん」がうまく動作するための大事な部分なので、ぜひ一緒に見ていきましょう。
1. 学習用データを収納するディレクトリ
学習のためには、「顔データ」と「非顔データ」の2種類のデータセットが必要です。今回用意したデータセットは、Kaggleからダウンロードした2000枚の人間の顔データと、2000枚の動物の顔データです。実際、人間の部位の一部や、都市や風景なども「非顔データ」に含めて学習すると、もっと汎用的なモデルができるので、そういうアプローチもいいですね。
2. トレーニングとテスト用のファイル
次に、「train.py」と「predict.py」という2つのPythonファイルを収納するディレクトリを用意します(今回の例では「src」という名前にしています)。ファイル名やディレクトリ名は、どれもわかりやすいように自由に決めて大丈夫です。
train.py: ここでは、顔検出のモデルを学習させます。たくさんのデータを食べさせて、顔をちゃんと認識できるように育てていくわけですね。
predict.py: これは、train.pyで学習させたモデルの性能をテストするためのファイルです。「ちゃんと顔を認識できてるかな?」とチェックするために使います。
この2つのファイルを使って、モデルの精度を確認します。問題がなければ、そのままviews.pyにこのモデルを使った処理を載せていく流れになります。
3. Django周りのファイルについて
Djangoの部分についても解説しますね
forms.py: ここでは、画像をアップロードするためのフォームを定義しています。ユーザーからの入力を受け取るために必要な部分ですね。
urls.py: このファイルは、ユーザーがWebページにアクセスしたときに、どのビュー(処理)を実行するかを定義します。言い換えれば、views.pyへのナビゲーションを担当しています。
views.py: ここが実際に画像を処理する部分です。アップロードされた画像を受け取って、顔検出のモデルを使って切り抜きを実行します。
templatesディレクトリ: HTMLテンプレートが保存されているディレクトリです。ユーザーインターフェースを構成するためのファイルが入っています。
モデルについて
先ほども触れたように、「顔切り抜きくん」では、検出された顔が本当に「顔」であるかを識別するために、VGG16の転移学習モデルを使用しています。ここでは、そのモデルの構築、トレーニング、そしてファインチューニングのプロセスについて詳しくご説明します。
転移学習とVGG16
VGG16は、非常に深い畳み込みニューラルネットワーク(CNN)で、ImageNetという大規模な画像データセットで事前に学習されています。この事前学習モデルは、さまざまな画像特徴を学習しており、一般的な画像認識タスクで非常に高い精度を誇ります。
転移学習では、VGG16のように事前に学習されたモデルの知識を新しいタスク(今回の場合は「顔の識別」)に活用します。これにより、少量のデータで効果的に学習ができ、トレーニング時間の短縮と精度向上が期待できます。
モデルを学習させるコードの流れ
このtrain.pyは、いわば「顔切り抜きくん」のトレーニングメニューを決めるためのコードです。つまり、ここでモデルに「顔とは何か」をたくさん教え込んで、ちゃんとした顔を認識できるようにする役割を持っています。では、このコードについて順番に説明します!
これが全体のコード
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
script_path = os.path.abspath(__file__)
script_dir = os.path.dirname(script_path)
project_root = os.path.dirname(script_dir)
def load_images_and_labels(face_directory, non_face_directory):
images = []
labels = []
# 顔画像の読み込み
for filename in os.listdir(face_directory):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(face_directory, filename)
img = cv2.imread(img_path)
if img is not None:
img = cv2.resize(img, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
labels.append(1) # 顔画像のラベルは1
# 非顔画像の読み込み
for filename in os.listdir(non_face_directory):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(non_face_directory, filename)
img = cv2.imread(img_path)
if img is not None:
img = cv2.resize(img, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
labels.append(0) # 非顔画像のラベルは0
return np.array(images), np.array(labels)
def create_or_load_model(model_path):
if os.path.exists(model_path):
print("既存のモデルを読み込みます。")
model = load_model(model_path)
else:
print("新しいモデルを作成します。")
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
output = Dense(1, activation='sigmoid')(x)
model = Model(inputs=base_model.input, outputs=output)
# ファインチューニングのために一部の層を解凍
for layer in model.layers[-4:]: # 最後の4層を訓練可能にする
layer.trainable = True
return model
def plot_training_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='training')
plt.plot(history.history['val_accuracy'], label='validation')
plt.title('Model Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='training')
plt.plot(history.history['val_loss'], label='validation')
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.savefig('training_history.png')
plt.close()
print("学習の進捗グラフが training_history.png として保存されました。")
# メインの実行部分
if __name__ == "__main__":
# データの読み込みと前処理
face_dir = os.path.join(project_root, 'data', 'faces')
non_face_dir = os.path.join(project_root, 'data', 'non_faces')
print(f"顔画像ディレクトリ: {face_dir}")
print(f"非顔画像ディレクトリ: {non_face_dir}")
X, y = load_images_and_labels(face_dir, non_face_dir)
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの作成または読み込み
model_path = os.path.join(project_root, 'models', 'face_detection_model.h5')
model = create_or_load_model(model_path)
# モデルのコンパイルと学習
model.compile(optimizer=Adam(learning_rate=0.0001), loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
# 学習履歴の可視化
plot_training_history(history)
# 更新されたモデルの保存
model.save(model_path)
print(f"モデルの学習が完了し、{model_path}に保存されました。")
# モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"テストデータでの損失: {loss:.4f}")
print(f"テストデータでの精度: {accuracy:.4f}")0.まず、必要なライブラリをインポートします
import os # ファイルやディレクトリの操作用
import cv2 # OpenCV、画像の読み込みや前処理用
import numpy as np # 数値計算や配列操作用
from sklearn.model_selection import train_test_split # データをトレーニング用とテスト用に分割
from tensorflow.keras.applications import VGG16 # 事前学習済みのVGG16モデルを使用
from tensorflow.keras.models import Model, load_model # モデルの作成と読み込み用
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D # ニューラルネットワークの層定義用
from tensorflow.keras.optimizers import Adam # モデルの最適化手法(オプティマイザー)
import matplotlib.pyplot as plt # グラフの描画と保存用
1. 画像の読み込みと前処理
まずは、モデルに教えるためのデータを準備します。この部分では、「顔」と「非顔」の画像データを読み込んで、モデルに使える形に整えています。
def load_images_and_labels(face_directory, non_face_directory):
images = []
labels = []
# 顔画像の読み込み
for filename in os.listdir(face_directory):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(face_directory, filename)
img = cv2.imread(img_path)
if img is not None:
img = cv2.resize(img, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
labels.append(1) # 顔画像のラベルは1
# 非顔画像の読み込み
for filename in os.listdir(non_face_directory):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(non_face_directory, filename)
img = cv2.imread(img_path)
if img is not None:
img = cv2.resize(img, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
images.append(img)
labels.append(0) # 非顔画像のラベルは0
return np.array(images), np.array(labels)
ここでやっていることは、Kaggleなどから集めてきた「顔」の画像と「非顔」の画像を、それぞれのディレクトリから読み込んで、モデルが理解できるように整形していることです。画像を224x224ピクセルにリサイズして、色のフォーマットも整えています。そして、「これは顔だよ」というラベルを1、逆に「これは顔じゃないよ」というラベルを0として、画像データに付けています。
2. モデルの作成または読み込み
次に、モデルを作るか、既存のモデルがあればそれを読み込んで再利用します。
def create_or_load_model(model_path):
if os.path.exists(model_path):
print("既存のモデルを読み込みます。")
model = load_model(model_path)
else:
print("新しいモデルを作成します。")
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
output = Dense(1, activation='sigmoid')(x)
model = Model(inputs=base_model.input, outputs=output)
# ファインチューニングのために一部の層を解凍
for layer in model.layers[-4:]:
layer.trainable = True
return model
ここでは、すでに学習済みのモデルファイルが存在するかを確認しています。もしあればそれを読み込んで再利用します。なければ、VGG16という有名な画像認識モデルをベースにして新しいモデルを作ります。最初から作らなくていいので、大幅に時間が節約できるのが利点です。
最後の部分では、「ファインチューニング」という手法を使っています。これは、モデルを再度訓練可能にして、より特定の顔認識タスクに最適化します。
3. モデルのトレーニング
次に、モデルをコンパイルして、トレーニング(学習)を行います。
model.compile(optimizer=Adam(learning_rate=0.0001), loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_test, y_test))
ここでは、Adamオプティマイザーという方法でモデルを訓練します。学習率は0.0001に設定し、損失関数としてbinary_crossentropyを使っています。これは2クラス(顔か非顔か)分類タスクに適した損失関数です。
そして、model.fitで実際にトレーニングを開始します。データセットをトレーニング用とテスト用に分けて、モデルがどれだけうまく学習できているかを随時チェックしながら進めます。ここでは、エポック数(学習の回数)を10回に設定していますが、もっと精度を高めたい場合は増やすことも可能です。
4. 学習の進捗を可視化
学習が終わったら、その進捗状況をグラフにして保存します。これで、どれだけモデルが改善されたかを一目で確認できます。
def plot_training_history(history):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='training')
plt.plot(history.history['val_accuracy'], label='validation')
plt.title('Model Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='training')
plt.plot(history.history['val_loss'], label='validation')
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.savefig('training_history.png')
plt.close()
print("学習の進捗グラフが training_history.png として保存されました。")
この関数では、モデルのトレーニング中の精度と損失の変化をグラフにして保存します。これで、どれだけモデルが改善されているかをビジュアルで確認できるようになります。
5. モデルの保存と評価
最後に、モデルを保存して、テストデータでその性能を評価します。
model.save(model_path)
print(f"モデルの学習が完了し、{model_path}に保存されました。")
loss, accuracy = model.evaluate(X_test, y_test)
print(f"テストデータでの損失: {loss:.4f}")
print(f"テストデータでの精度: {accuracy:.4f}")
トレーニングが完了したら、そのモデルを保存します。そして、テストデータを使って、どれだけうまくいっているのかを評価します。ここでの精度が高ければ「よし、このモデルは神!」って感じですし、低ければまたトレーニングデータやハイパーパラメータを見直して再挑戦しましょう。
次にモデルをテストするためのpredict.pyの説明
このpredict.pyは、さっき学習させたモデルをテストして、その性能をチェックするためのコードです。学習したモデルがどれだけうまく顔を認識してくれるかを、実際の画像で試してみるといった感じです。ここでは顔検出→先ほどの学習モデルで顔を識別→実際に切り取り保存→二段階識別の役割を果たしているかの確認をするので、「顔切り抜きくん」の試作品みたいな感じですね。
これが全体のコード
import os
import sys
import cv2
import numpy as np
from tensorflow.keras.models import load_model
script_path = os.path.abspath(__file__)
script_dir = os.path.dirname(script_path)
project_root = os.path.dirname(script_dir)
def preprocess_image(image):
img = cv2.resize(image, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return np.expand_dims(img, axis=0)
def detect_and_crop_faces(image_path, model, output_dir):
img = cv2.imread(image_path)
if img is None:
print(f"エラー: 画像の読み込みに失敗しました: {image_path}")
return
# 顔検出器の初期化
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# グレースケールに変換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔の検出
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
if len(faces) == 0:
print("顔が検出されませんでした。")
return
print(f"{len(faces)}個の顔が検出されました。")
for i, (x, y, w, h) in enumerate(faces):
face = img[y:y+h, x:x+w]
face_preprocessed = preprocess_image(face)
prediction = model.predict(face_preprocessed)[0][0]
print(f"顔 {i+1} である確率: {prediction:.2f}")
if prediction > 0.5: # 顔である確率が50%以上の場合のみ保存
# 切り抜いた顔を保存
output_path = os.path.join(output_dir, f'cropped_face_{i+1}.jpg')
cv2.imwrite(output_path, face)
print(f"切り抜いた顔 {i+1} を保存しました: {output_path}")
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使用方法: python predict.py <画像のパス>")
sys.exit(1)
image_path = sys.argv[1]
model_path = os.path.join(project_root,'models', 'face_detection_model.h5')
# 出力ディレクトリの作成
output_dir = os.path.join('output')
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model = load_model(model_path)
detect_and_crop_faces(image_path, model, output_dir)0. 必要なライブラリのインポート
最初に、必要なライブラリをインポートしています。ここでは、ファイル操作、画像処理、モデルの読み込みに使うものを取り込んでいます。
import os # ファイルやディレクトリ操作用
import sys # コマンドライン引数の取得用
import cv2 # OpenCV、画像の読み込みや処理用
import numpy as np # 数値計算や配列操作用
from tensorflow.keras.models import load_model # 学習済みモデルの読み込み用
1. 画像の前処理
次に、画像をモデルに入力できる形式に変換するための前処理関数を定義しています。
def preprocess_image(image):
img = cv2.resize(image, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return np.expand_dims(img, axis=0)
ここでは、OpenCVを使って画像を224x224ピクセルにリサイズし、色のフォーマットをBGRからRGBに変換しています。これは、モデルが期待する形式に合わせるためです。最後に、画像を4次元テンソル(バッチサイズを持つ配列)に変換するためにnp.expand_dimsを使っています。
2. 顔検出とトリミング処理
画像の中から顔を検出し、顔であるかどうかをモデルに判定させるメインの関数です。
def detect_and_crop_faces(image_path, model, output_dir):
img = cv2.imread(image_path)
if img is None:
print(f"エラー: 画像の読み込みに失敗しました: {image_path}")
return
# 顔検出器の初期化
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# グレースケールに変換
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 顔の検出
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
if len(faces) == 0:
print("顔が検出されませんでした。")
return
print(f"{len(faces)}個の顔が検出されました。")
for i, (x, y, w, h) in enumerate(faces):
face = img[y:y+h, x:x+w]
face_preprocessed = preprocess_image(face)
prediction = model.predict(face_preprocessed)[0][0]
print(f"顔 {i+1} である確率: {prediction:.2f}")
if prediction > 0.5: # 顔である確率が50%以上の場合のみ保存
# 切り抜いた顔を保存
output_path = os.path.join(output_dir, f'cropped_face_{i+1}.jpg')
cv2.imwrite(output_path, face)
print(f"切り抜いた顔 {i+1} を保存しました: {output_path}")
この関数でやっていることは次の通りです
画像の読み込み: 指定されたパスから画像を読み込みます。もし画像が見つからない場合、エラーメッセージを表示して処理を終了します。
顔検出器の初期化: OpenCVのカスケード分類器(事前学習済みの顔検出器)を使って、顔の位置を特定します。実は、私は当初、この顔検出機能を一から自作しようと試みました。しかし、すぐにその困難さに気づき、断念することに(笑)。そんなときに見つけたのが、OpenCVのCascadeClassifier。これほどの機能を簡単に利用できるのは、まさにPythonの強みだと改めて実感しました。
グレースケール変換と顔の検出: 画像をグレースケールに変換し、detectMultiScale関数で顔を検出します。検出された顔がなければ、その旨を伝えます。
検出された顔の処理: 複数の顔が検出された場合、それぞれの顔をトリミングして、学習済みモデルで「本当に顔かどうか」を判定します。顔である確率が50%以上であれば、その顔を保存します。
3. スクリプトのメイン部分
最後に、実行部分です。
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使用方法: python predict.py <画像のパス>")
sys.exit(1)
image_path = sys.argv[1]
model_path = os.path.join(project_root, 'models', 'face_detection_model.h5')
# 出力ディレクトリの作成
output_dir = os.path.join('output')
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model = load_model(model_path)
detect_and_crop_faces(image_path, model, output_dir)
if __name__ == "__main__"
この行は、Pythonスクリプトが「直接実行された」場合にのみ、その下のコードを実行するためのものです。具体的には、このスクリプトが他のPythonファイルからインポートされたときには実行されず、python predict.pyのようにコマンドラインから直接実行されたときだけ実行されるようにします。
こうすることで、テスト中に誤った操作や不適切な引数によるエラーを防ぐことができるんです。まさにプログラムの「安全装置」
あとの行は
モデルの読み込み: 学習済みのモデルファイルを指定してロードします。
出力ディレクトリの作成: トリミングした顔画像を保存するためのディレクトリを作成します(存在しない場合のみ)。
顔検出と処理の実行: 指定された画像パスとモデルを使って、顔を検出してトリミング処理を行います。
まとめ
このpredict.pyは、「顔切り抜きくん」がうまく機能するかどうかを確認するためのファイルです。画像を読み込んで顔を検出し、モデルが「これは顔だ!」と判断したものだけを切り抜いて保存します。その精度を確認し、Django用に調整し、views.pyに組み込みます。
Djangoでの実装まで
以下「顔切り抜きくん」のhtml UIになります
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>顔切り抜きくん</title>
<style>
body {
margin: 0;
font-family: sans-serif;
background-color: #0A4894;
display: flex;
flex-direction: column;
align-items: center;
min-height: 100vh;
}
.hako {
background-color: #D1E7DD;
width: 1200px;
border-radius: 20px;
padding: 50px;
display: flex;
justify-content: space-between;
margin-top: 50px;
}
.setumeihako {
width: 45%;
}
.gazouhako {
width: 45%;
}
h1 {
font-size: 50px;
color: #333333;
margin-bottom: 50px;
}
.subtitle {
font-size: 25px;
color: #0A4894;
margin-bottom: 20px;
}
.subtitle2 {
font-size: 16px;
color: #555555;
margin-bottom: 10px;
}
.upload-area {
background-color: #FFFFFF;
border: 2px dashed #0A4894;
border-radius: 15px;
padding: 20px;
text-align: center;
}
.upload-text {
color: #0A4894;
font-size: 14px;
margin-bottom: 10px;
}
.button {
background-color: #4169E1;
color: white;
border: none;
border-radius: 10px;
padding: 15px 0;
font-size: 18px;
cursor: pointer;
width: 100%;
margin-top: 10px;
}
.result-area {
margin-top: 20px;
width: 100%;
display: flex;
justify-content: center;
flex-wrap: wrap;
gap: 10px;
}
.result-image {
max-width: 200px;
max-height: 200px;
object-fit: cover;
}
.error-message {
color: #FF0000;
margin-top: 20px;
font-size: 16px;
}
.debug-info {
margin-top: 20px;
font-size: 14px;
color: #555555;
}
</style>
</head>
<body>
<div class="hako">
<div class="setumeihako">
<h1>顔切り抜きくん</h1>
<p class="subtitle">簡単で使いやすいトリミングツール</p>
<p class="subtitle2">jpgとpng画像ファイル限定</p>
<p class="subtitle2">自動で人物だけを切り取ります</p>
<p class="subtitle2">※顔以外もトリミングしてしまう場合もありますのでご容赦ください</p>
</div>
<div class="gazouhako">
<form method="post" enctype="multipart/form-data">
{% csrf_token %}
<div class="upload-area">
<p class="upload-text">画像を選択してください</p>
{{ form.image }}
</div>
<button type="submit" class="button">画像を処理する</button>
</form>
</div>
</div>
{% if error_message %}
<div class="error-message">
{{ error_message }}
</div>
{% endif %}
{% if debug_info %}
<div class="debug-info">
{{ debug_info }}
</div>
{% endif %}
{% if cropped_faces %}
<div class="result-area">
<p>検出された顔: {{ faces_count }}個</p>
{% for face in cropped_faces %}
<img src="data:image/jpeg;base64,{{ face }}" alt="Detected Face" class="result-image">
{% endfor %}
</div>
{% endif %}
</body>
</html>上記のコードでこのようなUIになります。

下に余白がありますが切り取った画像を表示させるためにわざとそうしてます。
必要なファイルたち:forms.pyとurls.py
Djangoのforms.pyについて
さてさて、まずはforms.pyです。このファイルでは、ユーザーが画像をアップロードするためのフォームを定義しています。「顔切り抜きくん」では、ユーザーが画像をアップロードして、それを使って顔を検出するわけですから、このフォームが超重要なんです。
from django import forms
class ImageUploadForm(forms.Form):
image = forms.ImageField(label='画像を選択')
何をしているかと言うと:
ImageUploadFormという名前のクラスを作って、Djangoのforms.Formを継承しています。つまり、このクラスがユーザーから画像を受け取るためのフォームってことです。
image = forms.ImageField(label='画像を選択')で、画像専用の入力フィールドを作成しています。これでユーザーは簡単に画像をアップロードできます。ラベルは「画像を選択」。シンプルでわかりやすいですね。
これを使うことで、Djangoのテンプレートで{{ form.image }}として表示される部分が、「画像を選択」するボタンになるんです。
Djangoのurls.pyについて
次はurls.pyです。このファイルは、アプリの中でどのURLがどの処理(ビュー)に対応するかを決める役割を持っています。Webアプリを作る上で、「このページに行ったら、こういう処理をするよ」っていうのを教える地図みたいなものですね。
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name='index'),
]
これで何が起こるのか:
from django.urls import pathで、URLパターンを定義するためのpath関数をインポートしています。
from . import viewsでは、同じディレクトリのviews.pyをインポートしています。views.pyには、ユーザーがページにアクセスしたときに実行される処理(関数)が書かれています。
urlpatternsリストには、URLとそれに対応するビュー関数が入っています。path('', views.index, name='index')って書いてあるのは、「ユーザーがトップページにアクセスしたら、views.indexという関数を実行するよ」という意味です。
なんでこんな設定が必要なの?
forms.pyの役割: これがないと、ユーザーから画像を受け取ることができません。Djangoのフォームを使うと、アップロードされた画像を安全に受け取れるし、いろいろなチェックも簡単にできます。
urls.pyの役割: これも重要!URLとビュー(ページを表示するための処理)をつなぐ役割を持っています。ユーザーがどのページを見たいのか、Djangoに教えてあげるためのファイルです。これがないと、ユーザーがアクセスしても何も返ってこなくなっちゃいます。
実行の部分:predict.pyからviews.pyへ、DjangoでのWebアプリ用にどう作り変えたか
今回のプロジェクトでは、コマンドラインで動作するpredict.pyをDjangoのviews.pyに変換して、Webアプリとして動作するようにしました。ここでは、その変化のポイントをコードを交えながら説明します!
こちらがviews.pyの全体
from django.shortcuts import render
from .forms import ImageUploadForm
import cv2
import numpy as np
from tensorflow.keras.models import load_model
import base64
import os
from django.conf import settings
# モデルを読み込む
model_path = os.path.join(settings.BASE_DIR,'background_removal_app','models', 'face_detection_model.h5')
model = load_model(model_path)
def preprocess_image(image):
img = cv2.resize(image, (224, 224))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return np.expand_dims(img, axis=0)
def detect_and_crop_faces(image):
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
cropped_faces = []
for (x, y, w, h) in faces:
face = image[y:y+h, x:x+w]
face_preprocessed = preprocess_image(face)
prediction = model.predict(face_preprocessed)[0][0]
if prediction > 0.5:
_, buffer = cv2.imencode('.jpg', face)
base64_image = base64.b64encode(buffer).decode('utf-8')
cropped_faces.append(base64_image)
return cropped_faces
def index(request):
if request.method == 'POST':
form = ImageUploadForm(request.POST, request.FILES)
if form.is_valid():
image = form.cleaned_data['image']
image_np = cv2.imdecode(np.frombuffer(image.read(), np.uint8), cv2.IMREAD_COLOR)
cropped_faces = detect_and_crop_faces(image_np)
context = {
'form': form,
'cropped_faces': cropped_faces,
'faces_count': len(cropped_faces),
'debug_info': f"処理された画像: {image.name}, 検出された顔: {len(cropped_faces)}個"
}
if not cropped_faces:
context['error_message'] = '顔が検出されませんでした。別の画像を試してください。'
return render(request, 'index.html', context)
else:
form = ImageUploadForm()
return render(request, 'index.html', {'form': form})1. コマンドライン処理からWebフォーム処理へ
変更点:
predict.pyは、コマンドラインから画像パスを受け取っていましたが、views.pyでは、ユーザーがブラウザ上で画像をアップロードする形に変更しました。
コードの違い:
predict.py
if len(sys.argv) < 2:
print("使用方法: python predict.py <画像のパス>")
sys.exit(1)
image_path = sys.argv[1]views.py:
def index(request):
if request.method == 'POST':
form = ImageUploadForm(request.POST, request.FILES)
if form.is_valid():
image = form.cleaned_data['image']
理由:
Webアプリでは、ユーザーがフォームを通じて画像をアップロードする方が簡単で直感的です。Djangoのフォーム機能を使って、画像を受け取る処理に変更しました。これにより、誰でも簡単に使えるWebアプリになります。
2. 処理結果の保存からWebページへの表示へ
変更点:
predict.pyでは処理結果の顔画像をファイルとして保存していましたが、views.pyではその結果をWebページ上に直接表示するように変更しました。
コードの違い:
predict.py:
if prediction > 0.5: # 顔である確率が50%以上の場合のみ保存
output_path = os.path.join(output_dir, f'cropped_face_{i+1}.jpg')
cv2.imwrite(output_path, face)
print(f"切り抜いた顔 {i+1} を保存しました: {output_path}")
views.py:
if prediction > 0.5:
_, buffer = cv2.imencode('.jpg', face)
base64_image = base64.b64encode(buffer).decode('utf-8')
cropped_faces.append(base64_image)
理由:
Webページ上で結果を表示することで、ユーザーは即座に処理結果を確認できます。画像をBase64でHTMLに埋め込むことで、ファイルを探す手間がなく、リアルタイムで結果が見られるようにしました。
3. 画像の読み込み方法の変更
変更点:
画像の読み込み方法を、ファイルパスからバイナリーデータに変更しました。
コードの違い:
predict.py:
img = cv2.imread(image_path)
views.py:
image_np = cv2.imdecode(np.frombuffer(image.read(), np.uint8), cv2.IMREAD_COLOR)
理由:
コマンドラインツールでは、画像のパスから直接画像を読み込んでいましたが、Webアプリではユーザーがフォームを通じてアップロードしたバイナリーデータを扱います。そのため、バイナリーデータを画像として処理するものに変更しました。
4. Djangoの設定を使ったパス設定
変更点:
モデルファイルのパス設定方法をDjangoの設定ファイルに基づいて変更しました。
コードの違い:
predict.py:
model_path = os.path.join(project_root, 'models', 'face_detection_model.h5')
views.py:
model_path = os.path.join(settings.BASE_DIR, 'background_removal_app', 'models', 'face_detection_model.h5')
理由:
Djangoのプロジェクト全体の設定に従ってファイルパスを管理することで、コードの一貫性を保ち、プロジェクト構成が変更された場合でも簡単に対応できるようにしました。settings.BASE_DIRを使うことで、コードがよりシンプルかつ管理しやすくなります。
5. エラーメッセージとデバッグ情報の表示方法の変更
変更点:
エラーメッセージやデバッグ情報の表示を、コンソールからWebページに移行しました。
コードの違い:
predict.py:
if len(faces) == 0:
print("顔が検出されませんでした。")
views.py:
if not cropped_faces:
context['error_message'] = '顔が検出されませんでした。別の画像を試してください。'
理由:
Webアプリでは、ユーザーにわかりやすく情報を伝える必要があります。コンソールではなく、Webページにエラーメッセージやデバッグ情報を表示することで、ユーザーが何が起こっているのかをすぐに理解できるようにしました。
まとめ
predict.pyからviews.pyに変えることで、コマンドラインでしか使えなかったツールが、よりインタラクティブでユーザーフレンドリーなWebアプリとして生まれ変わりました。ユーザーはブラウザ上で画像を簡単にアップロードでき、結果もすぐに確認できます。このような変更により、初心者でも簡単に使えるツールになります!
学習精度と実際の結果
改めて、今回のモデルの学習精度についてお話しします。
このアプリで使用している顔検出モデルは、事前学習済みのVGG16モデルをベースにしてトレーニングしています。学習データとして使用したのは、Kaggleから集めた2,000枚の顔画像と2,000枚の非顔画像(動物の顔や風景など)です。これらのデータを使ってモデルを訓練し、最終的なテスト結果では約85〜90%の精度を達成することができました。
実は、最初の学習でこのような高い精度を出せたのは「運が良かった」とも言えるかもしれません。しかし、これにはVGG16の転移学習の素晴らしさが大きく寄与していると思います。
転移学習の威力
VGG16は、大規模な画像データセット(ImageNet)で事前に学習されたモデルで、すでに「画像認識の達人」のようなものです。この事前学習済みモデルをベースに使うことで、ゼロからモデルを学習させるよりも少ないデータで高い精度を出せる可能性が高くなります。
つまり、VGG16の持つ豊富な「知識」を顔検出にうまく応用することで、非常に効率的に学習が進んだのです。その結果、最初の試行で予想以上に良い精度を叩き出すことができました。
トレーニング中の精度と損失の推移
以下のグラフは、トレーニング中に得られたモデルの精度(左)と損失(右)の推移を示しています。これらのグラフを使って、モデルの改善状況を常にチェックしていました。

左側のグラフ(Model Accuracy): これは、エポック(学習の反復回数)ごとのモデルの精度を示しています。
青い線(training): トレーニングデータに対する精度です。エポックが進むごとに精度が向上し、ほぼ100%に近づいています。
オレンジの線(validation): 検証データに対する精度です。こちらもトレーニングデータと同様に高い精度を保っています。エポック数が進むと、トレーニングデータと検証データの精度の差がほとんどなくなっています。
右側のグラフ(Model Loss): こちらは、エポックごとの損失の変化を示しています。損失は、モデルの予測が実際のラベルとどれだけ異なるかを示す指標です。
青い線(training): トレーニングデータに対する損失です。エポックが進むごとに急速に損失が減少し、ほぼゼロに近づいています。
オレンジの線(validation): 検証データに対する損失です。こちらも同様に急速に減少し、エポック数が進むにつれて損失がほぼゼロに近づいています。
結果の解釈と今後の改善
この学習結果のいくつかの結論
高い精度の維持:
トレーニングと検証の両方で非常に高い精度(約85〜90%)を達成しており、モデルは新しいデータに対しても適応できると考えられます。
転移学習の恩恵:
VGG16の転移学習を活用することで、少ないデータでも高い精度を達成できました。特に、顔認識のような既知のパターンに対しては、事前学習済みモデルの力が発揮されます。
モデルの安定性:
損失のグラフから、トレーニング中の損失が迅速に減少し、その後は安定していることがわかります。これにより、モデルが効果的に学習していることが確認できます。
今後の改善点:
さらに精度を向上させるためには、データの多様性を増やすことが有効です。例えば、さまざまな照明条件や角度の顔画像を追加することで、モデルの汎化能力を向上させることができます。また、ハイパーパラメータの調整(例えば学習率の調整やエポック数の増加)を行うことで、さらに高い精度を目指すことができるかもと考えられます。
直面した課題とその解決
Pythonを学び始めて2カ月、「顔切り抜きくん」というWebアプリの開発に取り組んだものの、正直言って道のりはなかなか険しかったです。コードを書くたびに新しい問題にぶつかり、それを解決していく過程で多くのことを学びました。ここでは、私が実際に直面した問題と、それをどうやって解決したのかをご紹介します。
特に大変だったのは「モデルの作り方」「デバッグとエラーハンドリングの難しさ」、そして「画像の前処理と後処理」でしたね。
1. モデルの作り方
私は初めてモデルを作るとき、どこから始めていいのか、何をどうすればいいのか、と絶望しました…。特に、どのライブラリを使って、どのようにモデルを定義し、どうトレーニングすればいいのかがさっぱりわからず、そこで調べるのにかなり時間を使いました。
解決方法: 私が試したのは、まず「転移学習」を使うことでした。VGG16という事前に学習されたモデルを利用することで、自分でモデルを一から設計する必要がなくなり、かなりの時間を節約できました。
この方法なら、すでに多くのデータで学習されているVGG16の能力を借りることができるため、自分のデータに合わせて少しの調整を行うだけで高い精度を出すことができました。
2. デバッグとエラーハンドリングの難しさ
プログラムを実行するときにエラーが出た場合、どこが悪いのか見つけるのが本当に大変でした。エラーメッセージを見ても、何を言っているのかよく分からず、「とりあえずググってみるか…」となることがしょっちゅうでした
解決方法: 「何とかしてデバッグを楽にしたい!」と考えて、print文を駆使して解決に取り組み、どこでエラーが起きているのかを追跡することにしました。例えば、コードの中にどんどんprint文を入れて、今どこまで処理が進んでいるのか、どの値が期待通りに計算されているのかを確認しました。
これにより、「何が悪いのか分からない…」というストレスがかなり減りました。
3. 画像の前処理と後処理
画像をモデルに入力する前に、適切なサイズに揃えたり、色のフォーマットを変えたりする「前処理」が必要ですが、この処理がうまくいかないことがよくありました。また、モデルが出力した結果を再び画像として保存する「後処理」も思った以上に手間がかかりました。
解決方法: 画像の前処理と後処理の問題を解決するためには、以下の方法を取りました:
前処理: OpenCVライブラリを使って、すべての画像を同じサイズ(224x224ピクセル)にリサイズし、RGB形式に変換する前処理を関数として作りました。これで、モデルに渡す前にすべての画像が正しい形式になり、エラーが減りました。
後処理: 画像の保存方法も最初はうまくいかないことが多かったので、cv2.imencodeを使って画像をエンコードし、それをBase64形式に変換してWebページに表示する方法を採用しました。これにより、保存と表示がスムーズになりました。
感想と今後の展望
この一連の作業を通して感じたのは、プログラミングというのは本当に「挑戦の連続」だということです。そして、その挑戦を通じて新しいスキルを学び、少しずつできることが増えていく楽しさを実感しました。どんなに小さな進歩でも、それが積み重なることで大きな成果に繋がっていく。その過程が、とてもやりがいのあるものでした。
今後も、今回得た知識と経験を基に、さらなる学びに挑戦し続けていきたいと思います。そして、もしこの記事を読んでいる方が同じような道を歩んでいるならば、一緒に一歩ずつ進んでいければ嬉しいです。
最後に
プログラミングは決して簡単なものではありませんが、やればやるほど楽しくなるものです。そして、問題に直面するたびに「新しい何か」を学べる貴重なチャンスでもあります。これからも一緒に成長していきましょう!