Twitterを用いて感情分析/株価予測をしてみた

はじめに
大手広告代理店でバリバリの営業マンだったが、pythonを活用したデータ分析などに興味をもち、Aidemyで勉強中。pythonエンジニアか、スキルを携えた新たな働き方を検討中。
Aidemyで学んだ事を備忘録として記載したいと思います。
●ツイートの取得
このコードではある特定のアカウントのツイートを取得します。
ここでは\"NIKKEI BUSINESS DAILY(日経産業新聞)\"のツイートを取得してみます。
from requests_oauthlib import OAuth1Session
import json
import datetime, time, sys
import tweepy
import csv
consumer_key = '' # Consumer Keyを記載
consumer_secret = '' # Consumer Secretを記載
access_token = '' # Access Tokenを記載
access_secret = '' # Accesss Token Secertを記載
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
#ツイート取得
tweet_data = []
tweets = tweepy.Cursor(api.user_timeline,screen_name = "@nikkei_bizdaily",exclude_replies = True)
for tweet in tweets.items():
tweet_data.append([tweet.id,tweet.created_at,tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
tweet_data
with open('./tweets.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id", "text", "created_at", "fav", "RT"])
writer.writerows(tweet_data)●感情分析
自然言語処理を用いて、テキストがポジティブな意味合い、またはネガティブな意味合いを持つかを判断します。
判断の基準となるものに極性辞書があり、あらかじめ形態素にポジティブかネガティブが定義された辞書中に定義されています。
import MeCab
import re
import pandas as pd
# MeCabインスタンスの作成.引数を無指定にするとIPA辞書になります.
m = MeCab.Tagger('')
# テキストを形態素解析し辞書のリストを返す関数
def get_diclist(text):
parsed = m.parse(text) # 形態素解析結果(改行を含む文字列として得られる)
lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする
lines = lines[0:-2] # 後ろ2行は不要なので削除
diclist = []
for word in lines:
l = re.split('\t|,',word) # 各行はタブとカンマで区切られてるので
d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]}
diclist.append(d)
return(diclist)
pn_df = pd.read_csv('./6050_stock_price_prediction_data/pn_ja.csv', encoding='utf-8', names=('Word','Reading','POS', 'PN'))
word_list = list(pn_df['Word'])
pn_list = list(pn_df['PN'])
pn_dict = dict(zip(word_list, pn_list))極性辞書を参照してPNの値を返すところの実装を行います。
import numpy as np
# 形態素解析結果の単語ごとのdictデータにPN値を追加する関数
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm'] # 個々の辞書から基本形を取得
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound' # その語がPN Tableになかった場合
word['PN'] = pn
diclist_new.append(word)
return(diclist_new)
# 各ツイートのPN平均値を求める
def get_mean(dictlist):
pn_list = []
for word in dictlist:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean
dl_old = get_diclist("明日は晴れるでしょう。")
# get_diclist("明日は晴れるでしょう。")を関数add_pnvalueに渡して働きを調べる
dl_new = add_pnvalue(dl_old, pn_dict)
print(dl_new)
# またそれを関数get_meanに渡してPN値の平均を調べる
pnmean = get_mean(dl_new)
print(pnmean)PN値の変化をグラフで表示してみます。
import matplotlib.pyplot as plt
%matplotlib inline
df_tweets = pd.read_csv('./tweets.csv', names=['id', 'date', 'text', 'fav', 'RT'], index_col='date')
df_tweets = df_tweets.drop('text', axis=0)
df_tweets.index = pd.to_datetime(df_tweets.index)
df_tweets = df_tweets[['text']].sort_index(ascending=True)
# means_listという空のリストを作りそこにツイートごとの平均値を求める。
means_list = []
for tweet in df_tweets['text']:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_tweets['pn'] = means_list
df_tweets = df_tweets.resample('D').mean()
# 日付をx軸PN値をy軸にしてプロット。
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)
# df_tweets.csvという名前でdf_tweetsを再び出力。
df_tweets.to_csv('./6050_stock_price_prediction_data/df_tweets.csv')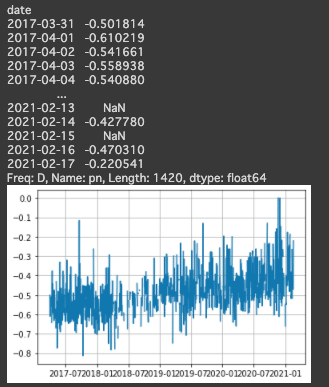
グラフの結果を見ると全体的に負の値が多いように感じられるので、
この結果を調整するために標準化を行います。
x_std = (df_tweets['pn'] - df_tweets['pn'].mean()) / df_tweets['pn'].std()
df_tweets['pn'] = x_std
# またPNを日付ごとの平均に変え、プロット
df_tweets = df_tweets.resample('D').mean()
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)●時系列データの取得
日経平均株価の過去のcsvデータを取ってきて保存します。
時系列データの終値に注目して予測を行います。
import pandas as pd
from io import StringIO
import urllib
# 上記の関数を使い日経平均株価の時系列データを取得
url = "https://indexes.nikkei.co.jp/nkave/historical/nikkei_stock_average_daily_jp.csv"
def read_csv(url):
res = urllib.request.urlopen(url)
res = res.read().decode('shift_jis')
df = pd.read_csv(StringIO(res))
# 必要のない最後の行を取り除いています
df = df.drop(df.shape[0]-1)
return df
# dfというdataframeで保存し、出力
df = read_csv(url)
# indexを日付にした後、時系列にする
df["データ日付"] = pd.to_datetime(df["データ日付"], format='%Y/%m/%d')
df = df.set_index('データ日付')
# カラムから'始値', '高値', '安値'を取り除いて、日付が古い順に並べる
df = df.drop(['始値', '高値', '安値'], axis=1)
df = df.sort_index(ascending=True)
df.to_csv("./time_data.csv")データの欠損値を取り除きます。具体的にはデータの欠損値のある行を削除します。
df = pd.read_csv("./time_data.csv" , index_col="データ日付")
# dfとdf_tweetsの二つのテーブルを結合し、Nanを消去
df_tweets = pd.read_csv('./6050_stock_price_prediction_data/df_tweets.csv', index_col='date')
table = df_tweets.join(df, how='right').dropna()
# table.csvとして出力
table.to_csv("./table.csv")●株価予測
テクニカル分析を用いて株価の予測を行います。
過去三日間の日経平均株価の時系列の変化とPN値の変化を特徴量にして次の日の株価の上下の予測を行い、訓練データとテストデータの二つに分け、訓練データを標準化したのち、訓練データの平均と分散を用いてテストデータの標準化を行います。
from sklearn.model_selection import train_test_split
X = table.values[:, 0]
y = table.values[:, 1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False)
X_train_std = (X_train - X_train.mean()) / X_train.std()
X_test_std = (X_test - X_train.mean()) / X_train.std()
# df_trainというテーブルを作りそこにindexを日付、カラム名をpn値、終値にしてdf_train.csvという名前でdataフォルダ内に出力
df_train = pd.DataFrame(
{'pn': X_train_std,
'終値': y_train},
columns=['pn', '終値'],
index=table.index[:len(X_train_std)])
df_train.to_csv('./df_train.csv')
# テストデータについても同様にdf_testというテーブルを作り、df_test.csvという名前でdataフォルダ内に出力
df_test = pd.DataFrame(
{'pn': X_test_std,
'終値': y_test},
columns=['pn', '終値'],
index=table.index[len(X_train_std):])
df_test.to_csv('./df_test.csv')PN値と株価の変化を表示することを行います。
rates_fd = open('./df_train.csv', 'r')
rates_fd.readline() #1行ごとにファイル終端まで全て読み込む
next(rates_fd) # 先頭の行を飛ばす
exchange_dates = []
pn_rates = []
pn_rates_diff = []
exchange_rates = []
exchange_rates_diff = []
prev_pn = df_train['pn'][0]
prev_exch = df_train['終値'][0]
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csvの1列目日付
pn_val = float(splited[1]) # table.csvの2列目PN値
exch_val = float(splited[2]) # table.csvの3列目株価の終値
exchange_dates.append(time) # 日付
pn_rates.append(pn_val)
pn_rates_diff.append(pn_val - prev_pn) # PN値の変化
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化
prev_pn = pn_val
prev_exch = exch_val
rates_fd.close()
print(pn_rates_diff)
print(exchange_rates_diff)3日間ごとのPN値と株価の変化を表示してみます。
INPUT_LEN = 3
data_len = len(pn_rates_diff)
tr_input_mat = []
tr_angle_mat = []
for i in range(INPUT_LEN, data_len):
tmp_arr = []
for j in range(INPUT_LEN):
tmp_arr.append(exchange_rates_diff[i-INPUT_LEN+j])
tmp_arr.append(pn_rates_diff[i-INPUT_LEN+j])
tr_input_mat.append(tmp_arr) # i日目の直近3日間の株価とネガポジの変化
if exchange_rates_diff[i] >= 0: # i日目の株価の上下、プラスなら1、マイナスなら0
tr_angle_mat.append(1)
else:
tr_angle_mat.append(0)
train_feature_arr = np.array(tr_input_mat)
train_label_arr = np.array(tr_angle_mat)
# train_feature_arr, train_label_arrを表示
print(train_feature_arr)
print(train_label_arr)何とか実行する事ができました( ◠‿◠ )
おわりに
データ分析、データサイエンスの領域に、興味が出てきましたので、今後の学習の方向性の照準としたいと思います。