
Python初心者が、Google Mapのクチコミデータで感情分析してみた

はじめに
これまで、メーカーでデータ分析や数値管理の仕事を7年、IT企業でWebエンジニアを2年ほど経験してきました。分析手法の幅を広げ、ビジネス領域でもっと価値提供できるようになりたいと思うようになり、2024年3月からAIやデータ分析に特化したオンライン講座でデータ分析の学習をしています。
この記事は、そのカリキュラムの最終課題として取り組んだ内容をまとめたものになります。
開発環境
MacBook Pro
Chrome
Google Colaboratory
分析のテーマについて
お店などを選ぶ際、私にとって欠かせない存在となっているGoogleのレビューですが、星の数とクチコミにどのくらい相関があるのだろうかと気になり、調べてみることにしました。
これは個人的な感覚になりますが、お店で不快な思いをしない限り、低評価をつける人は少ない気がしています。なので、クチコミがすごくポジティブな内容でなくても高評価が多くなり、結果的に相関が大きくなることはないのでは?というのが最初にぼんやり考えていた仮説です。
この分析では、Googleのレビューデータに対し、2種類の形態素解析ツールと2種類の極性辞書を掛け合わせた計4パターンで、クチコミテキストの感情を数値化し、レビュー評価との相関を確認しました。1つのパターンに絞って実装を始めたのですが、だんだん他のパターンの相関も気になってきたので4つに増やしました。
分析の流れ
以下のステップで分析を行いました。
Google Places API (New)でクチコミデータを取得
極性辞書 (単語感情極性値対応表と日本語評価極性辞書読)のデータを取得
janomeとMeCabで形態素解析の出力結果を確認
クチコミデータの形態素解析と感情スコアの計算
感情スコアの可視化
感情スコアとクチコミ評価の相関を確認
以下、上記のステップに沿った詳細説明となります。
分析の詳細
1. Google Places API (New)でクチコミデータを取得
APIでデータを取得した流れは以下の通りです。
Google Cloudにログインし、プロジェクトを作成
Google Maps Platform > APIとサービス メニューに移動
Places API (New)を有効化
APIキーを取得
なお、Places API (New)は無料トライアルとして使用開始すると、$200のクレジットが付与されます。この範囲内の使用であれば無料ということです。
ただ、どのくらいのデータ量まで取得すれば無料枠に収まるのかがわからず不安だったので、以下のように条件を絞ってデータを取得することにしました。
対象地域:東京都の中心から半径5メートル以内
業種:レストラン
店の種類:お寿司屋さん
import pandas as pd
import requests
import time
api_key = "your_api_key"
location = "35.6895,139.6917" # 東京都の中心の緯度と経度
radius = 5000 # 東京都の中心から半径5キロメートルの円内
query = "寿司"
# 特定のエリア内のお寿司屋さんを検索
def search_places(api_key, query, location, radius, next_page_token=None):
url = "https://maps.googleapis.com/maps/api/place/textsearch/json"
params = {
"query": query,
"location": location,
"radius": radius,
"type": "restaurant", # レストランに限定
"language": "ja", # 日本語で結果を取得
"key": api_key
}
if next_page_token:
params["pagetoken"] = next_page_token
response = requests.get(url, params=params)
if response.status_code != 200:
print(f"Error during search places: {response.status_code}")
return None
return response.json()
# 特定の場所のレビューを取得
def get_place_details(api_key, place_id):
url = "https://maps.googleapis.com/maps/api/place/details/json"
params = {
"place_id": place_id,
"fields": "name,reviews,formatted_address",
"language": "ja", # 日本語で結果を取得
"key": api_key
}
response = requests.get(url, params=params)
if response.status_code != 200:
print(f"Error during details fetch: {response.status_code}")
return None
return response.json().get("result", {})
# 全ての結果を収集する
def get_all_places(api_key, query, location, radius):
all_places = []
next_page_token = None
while True:
data = search_places(api_key, query, location, radius, next_page_token)
if not data:
break
all_places.extend(data.get("results", []))
next_page_token = data.get("next_page_token")
if not next_page_token:
break
time.sleep(2) # APIのリクエスト制限を避けるために待機
return all_places
# データの取得と保存
all_places = get_all_places(api_key, query, location, radius)
all_reviews = []
for place in all_places:
place_id = place["place_id"]
details = get_place_details(api_key, place_id)
if not details:
continue
place_name = details.get("name")
formatted_address = details.get("formatted_address")
reviews = details.get("reviews", [])
for review in reviews:
all_reviews.append({
"place_name": place_name,
"address": formatted_address,
"rating": review["rating"],
"text": review["text"],
"time": review["relative_time_description"]
})
time.sleep(2)
df = pd.DataFrame(all_reviews)
df.to_csv("sushi_reviews.csv", index=False, encoding='utf-8-sig')
print("Data saved to sushi_reviews.csv")
df.to_csv("sushi_reviews.csv", index=False, encoding='utf-8-sig')によって生成されたCSVファイルは、Google Colaboratoryのワークスペース内に保存されます。
このファイルをローカルフォルダにダウンロードします。
from google.colab import files
files.download("sushi_reviews.csv")Google Colaboratoryのフォルダに保存し、pandasで読み込みます。
# レビューデータの読み込み
review_df = pd.read_csv('/content/drive/MyDrive/ReviewAnalysis/sushi_reviews.csv')
review_df.head(10)一度のAPI実行で取得できるクチコミデータは300件、1つのお寿司屋さんにつき取得できるのは5件のようです。意外と少ない…

レビューデータの前処理を以下の内容で行い、cleaned_textという列に格納します。
URLの削除
アルファベット、数字、ひらがな、カタカナ、漢字以外を削除
不要なスペースの削除
import re
def clean_text(text):
text = re.sub(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', '', text)
text = re.sub(r'www\.(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', '', text)
text = re.sub(r'[^A-Za-z0-9ぁ-んァ-ヶ一-龥々ー]', ' ', text)
text = re.sub(r'\s+', ' ', text).strip()
return text
review_df['cleaned_text'] = review_df['text'].apply(clean_text)
review_df.head(10)
2. 極性辞書 (単語感情極性値対応表と日本語評価極性辞書)のデータを取得
それぞれ、以下のサイトからダウンロードします。
Google Colaboratoryのフォルダに保存し、pandasで読み込みます。
# 単語感情極性値対応表の読み込み
pn_df = pd.read_csv('/content/drive/MyDrive/ReviewAnalysis/pn_ja.txt')
pn_df.head()単語、読み、品詞、感情スコア(-1以上1以下)のデータが確認できます。

pn_df.tail()の結果も確認しておきます。

# 日本語評価極性辞書の読み込み
pn2_df = pd.read_csv('/content/drive/MyDrive/ReviewAnalysis/pn.csv.m3.120408.trim')
pn2_df.head()単語、感情区分、単語の詳細情報が確認できます。

pn2_df.tail()の結果も確認します。

まず、単語感情極性値対応表を、単語をKey、感情スコアをValueにもつ辞書型に変換します。
pn_df = pd.read_csv('/content/drive/MyDrive/ReviewAnalysis/pn_ja.txt', sep=':', encoding='utf-8', names=['Word', 'Reading', 'POS', 'PN'])
pn_df = pn_df[['Word', 'PN']].dropna()
pn_dict = dict(zip(pn_df['Word'], pn_df['PN']))
print(pn_dict)
次に、日本語評価極性辞書を変換します。感情スコアを具体的な数値で示した単語感情極性値対応表とは異なり、e、p、n…のように単語ごとに感情タイプが割り当てられています。このままでは感情スコアを算出できないので、以下のような変換を行います。
p:1
e:0
n:-1
そして、単語をKey、感情スコアをValueにもつ辞書型に変換します。
pn2_df = pd.read_csv('/content/drive/MyDrive/ReviewAnalysis/pn.csv.m3.120408.trim', names=['word_pn_data'])
pn2_df = pn2_df['word_pn_data'].str.split('\t', expand=True)
pn2_df = pn2_df[(pn2_df[1] == 'p') | (pn2_df[1] == 'n') | (pn2_df[1] == 'e')]
pn2_df = pn2_df.drop(pn2_df.columns[2], axis=1)
pn2_df[1] = pn2_df[1].replace({'p': 1, 'n': -1, 'e': 0})
pn2_dict = dict(zip(pn2_df[0], pn2_df[1]))
print(pn2_dict)
3. janomeとMeCabで形態素解析の出力結果を確認
janomeをインストールします。
pip install janomeMeCabをインポートしようとするとエラーが発生したので、インポートする前に以下のコードを実行します。

!apt-get update
!apt-get install -y mecab libmecab-dev mecab-ipadic-utf8 swig
!pip install mecab-python3
!mkdir -p /usr/local/etc
!cp /etc/mecabrc /usr/local/etc/mecabrcjanomeとMeCabをインポートして、形態素解析結果がどのようなフォーマットなのかを確認します。tokenizeメソッドの返り値はgeneratorなので、for文で取り出します。
import MeCab
from janome.tokenizer import Tokenizer
# 確認用テキスト
sample_text = "これは、文章を形態素に分割し、形態素ごとに品詞などの情報を付与した結果を確認するためのサンプルです。"
print("---janome---")
tokenizer = Tokenizer()
janome_outputs = tokenizer.tokenize(sample_text)
for janome_output in janome_outputs:
print(janome_output)
print()
print(type(janome_outputs))
print()
print("---MeCab---")
mecab = MeCab.Tagger("-Ochasen")
mecab_outputs = mecab.parse(sample_text)
print(mecab_outputs)
print(type(mecab_outputs))

サンプルテキストにおいては、分割結果に差はありませんでした。
4. クチコミデータの形態素解析と感情スコアの計算
極性辞書から形態素の感情スコアを検索するには、形態素と極性辞書のKeyが一致する必要があります。そのため、形態素解析の結果から原型を取得します。
MeCabについては、parseメソッドの返り値が文字列(str)でした。なのでsplitlines()で1行ごとに分割したリストに対してfor文をまわし、タブごとに分割した文字列をリスト化します。先ほど確認したサンプルの形態素解析結果に基づき、左から3番目のデータを指定することで原型を取得できました。
mecab_outputs = mecab.parse(sample_text)
words = [line.split('\t')[2] for line in mecab_outputs.splitlines() if line != 'EOS' and len(line.split('\t')) > 2]
print(words)
一方janomeについては、tokenizeメソッドの返り値がgeneratorでした。janomeの公式ドキュメントを参考に、Tokenオブジェクトに対してbase_formプロパティを使用して原型を取得することができました。
tokens = tokenizer.tokenize(sample_text)
words = [token.base_form for token in tokens]
print(words)
get_sentiment_score関数を作成します。引数に形態素解析ツール名と極性辞書を渡すことにより、以下4パターンでクチコミテキストごとの平均感情スコアが計算できるようにしました。
形態素解析:janome × 極性辞書:単語感情極性値対応表
形態素解析:MeCab × 極性辞書:単語感情極性値対応表
形態素解析:janome × 極性辞書:日本語評価極性辞書
形態素解析:MeCab × 極性辞書:日本語評価極性辞書
関数を実行して得られた感情スコアを、review_dfの新たな列に追加します。
import numpy as np
def get_sentiment_score(text, analyzer, dict):
if analyzer == 'janome':
tokens = tokenizer.tokenize(text)
words = [token.base_form for token in tokens]
elif analyzer == 'mecab':
parsed_text = mecab.parse(text)
words = [line.split('\t')[2] for line in parsed_text.splitlines() if line != 'EOS' and len(line.split('\t')) > 2]
pn_list = [dict[word] for word in words if word in dict]
return np.mean(pn_list) if pn_list else 0
# レビューデータに感情スコアを追加
review_df['sentiment_score_ja_pn'] = review_df['cleaned_text'].apply(get_sentiment_score, args=('janome', pn_dict))
review_df['sentiment_score_me_pn'] = review_df['cleaned_text'].apply(get_sentiment_score, args=('mecab', pn_dict))
review_df['sentiment_score_ja_pn2'] = review_df['cleaned_text'].apply(get_sentiment_score, args=('janome', pn2_dict))
review_df['sentiment_score_me_pn2'] = review_df['cleaned_text'].apply(get_sentiment_score, args=('mecab', pn2_dict))
review_df.head(10)
5. 感情スコアの可視化
ヒストグラムで、感情スコアの分布状況を確認してみます。
import matplotlib.pyplot as plt
def plot_histogram(ax, df, column, title):
ax.hist(df[column], bins=20, edgecolor='k')
ax.set_title(title)
ax.set_xlabel('Sentiment Score')
ax.set_ylabel('Frequency')
# サブプロット作成
fig, axs = plt.subplots(2, 2, figsize=(10, 10))
# 各サブプロットにヒストグラムをプロット
plot_histogram(axs[0, 0], review_df, 'sentiment_score_ja_pn', 'Sentiment Score Distribution (janome + pn_dict)')
plot_histogram(axs[0, 1], review_df, 'sentiment_score_me_pn', 'Sentiment Score Distribution (mecab + pn_dict)')
plot_histogram(axs[1, 0], review_df, 'sentiment_score_ja_pn2', 'Sentiment Score Distribution (janome + pn2_dict)')
plot_histogram(axs[1, 1], review_df, 'sentiment_score_me_pn2', 'Sentiment Score Distribution (mecab + pn2_dict)')
plt.tight_layout()
plt.show()4つのヒストグラムを見て感じたのは以下の点です。
形態素解析ツールによる差はほとんどない
単語感情極性値対応表で計算した感情スコアはマイナスのクチコミ件数が多い
日本語評価極性辞書で計算した感情スコアはプラスのクチコミ件数が多い

6. 感情スコアとクチコミ評価の相関係数を計算
散布図で、感情スコアとクチコミ評価の相関を確認してみます。
import seaborn as sns
def plot_scatter(ax, df, x_col, y_col, title):
sns.scatterplot(ax=ax, x=x_col, y=y_col, data=df)
ax.set_title(title)
ax.set_xlabel('Rating')
ax.set_ylabel('Sentiment Score')
# サブプロットを作成
fig, axs = plt.subplots(2, 2, figsize=(12, 10))
# 各サブプロットに散布図をプロット
plot_scatter(axs[0, 0], review_df, 'rating', 'sentiment_score_ja_pn', 'Rating vs Sentiment Score (janome + pn_dict)')
plot_scatter(axs[0, 1], review_df, 'rating', 'sentiment_score_me_pn', 'Rating vs Sentiment Score (mecab + pn_dict)')
plot_scatter(axs[1, 0], review_df, 'rating', 'sentiment_score_ja_pn2', 'Rating vs Sentiment Score (janome + pn2_dict)')
plot_scatter(axs[1, 1], review_df, 'rating', 'sentiment_score_me_pn2', 'Rating vs Sentiment Score (mecab + pn2_dict)')
plt.tight_layout()
plt.show()4つの散布図を見て感じたのは以下の点です。
形態素解析ツールによる差はほとんどない
日本語評価極性辞書で計算した感情スコアの方が、各クチコミ評価におけるばらつきがやや大きい
クチコミ評価が高いからといって感情スコアが高いとは言えなさそう

次に、相関係数を計算してみます。
def calculate_correlation(df, x_col, y_col, analysis_type):
correlation = df[x_col].corr(df[y_col])
print(f"Correlation between {x_col} and {y_col} [{analysis_type}]: {correlation}")
calculate_correlation(review_df, 'rating', 'sentiment_score_ja_pn', 'janome + pn_dict')
calculate_correlation(review_df, 'rating', 'sentiment_score_me_pn', 'mecab + pn_dict')
calculate_correlation(review_df, 'rating', 'sentiment_score_ja_pn2', 'janome + pn2_dict')
calculate_correlation(review_df, 'rating', 'sentiment_score_me_pn2', 'mecab + pn2_dict')どの組み合わせもほぼ同じ相関係数となりました。ヒストグラムからは、使用する極性辞書によって感情スコアの度数分布に違いがみられましたが、相関関係をみると4つのパターンの間に大きな違いはないということですね。

一般的に、0.25は「弱い相関がある」という程度なので、今回の分析に関しては、「クチコミ評価の点数とクチコミテキストの感情スコアの間には弱い相関がある」という結果になりました。
分析の振り返り
この結果を見ると、最初にぼんやりと考えていた仮説はあながち間違いではないのか…?という気もしますが、このような結果が得られた理由や改善点について考えてみました。
今回取得した300件のレビューデータにおけるクチコミ評価の分布を確認すると、高評価が圧倒的に多く、低評価が少ないことがわかります。
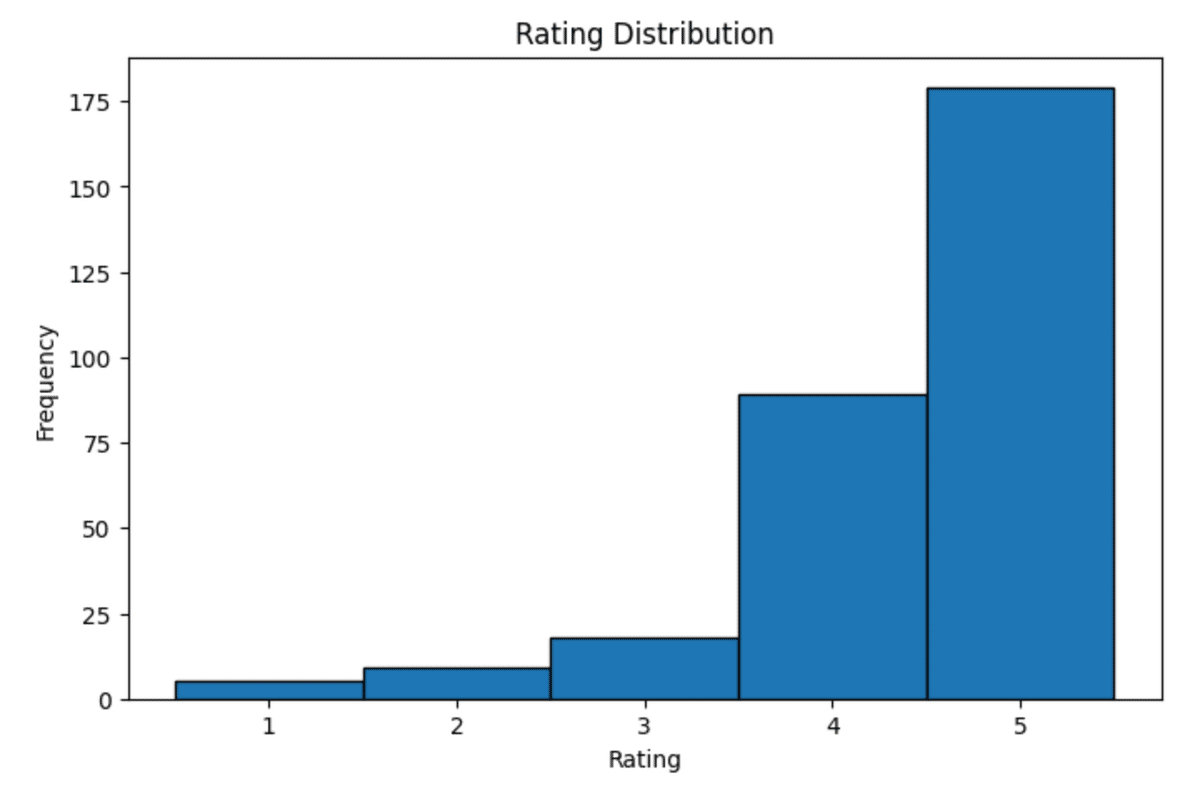
低評価のサンプルが少なすぎたが故に、相関係数が小さくなった可能性が考えられそうです。もし、低評価のクチコミテキストの感情スコアも低いサンプルがもっと多ければ、相関係数は大きくなるかもしれません。APIで取得するデータを東京都全域に広げたり、対象のお店を全ての飲食店に設定するなど、データ件数を大幅に増やして再分析してみても良いかもしれません。ちなみに、上記のコードでGoogle Places API (New)を1回実行した結果、かかった金額は250円未満でした。なので無料枠でもそこそこのデータ量を収集することは可能そうです。
また、今回の感情分析では、文脈単位での感情判定ができていない点も気になります。形態素解析によって、クチコミテキストが意味を持つ最小の言語単位に分割されるため、例えポジティブな文脈であっても、分割された単語のスコアが極性辞書においてマイナスであれば、実態と大きく異なる感情スコアとなることが考えられます。実際に、取得したクチコミテキストを一つ一つ目視で確認してみると、直感的にネガティブ要素は皆無なのに、感情スコアが意外と低いなと感じるものもありました。
まとめ
長文にも関わらず、最後までお読みいただきありがとうございます。
今回の分析では、Google Places API (New)で取得したクチコミデータに対し、2つの極性辞書と2つの形態素解析ツールを使用して感情スコアを計算し、クチコミ評価との相関を見てきました。
結果としてはどの組み合わせも「弱い相関がある」というものでした。振り返りで挙げたような考察や改善点を反映してみるとまた違った結果が得られるかもしれません。