
Python: timeデータ同士の引き算

実務でスケジュールに関するデータをPythonで加工する機会があったので、メモとして残します。
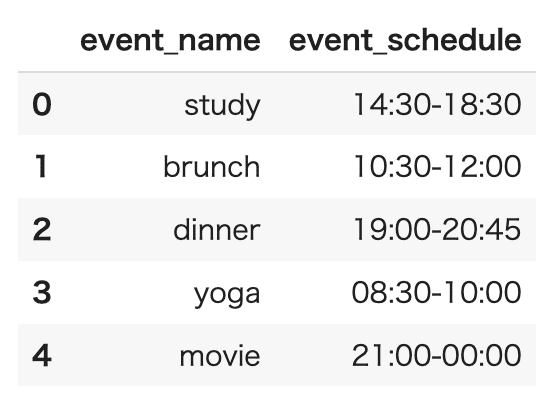
以下のようなイベントのスケジュールデータを元に、開始時間と終了時間を分割し、それぞれのイベントの合計時間を計算するのが目標です。※ここでは、サンプルデータのイベントは全て同日(日は跨がない)として計算します。
まず、イベント名とそのスケジュールを含むデータを作成します。スケジュールは 文字列の`HH:MM-HH:MM` 形式です。
# サンプルデータの作成
data = {'event_name': ['study', 'brunch', 'dinner', 'yoga', 'movie'],
'event_schedule': ['14:30-18:30', '10:30-12:00', '19:00-20:45', '08:30-10:00', '21:00-00:00']}
# データフレームの作成
df_event = pd.DataFrame(data)
df_event出力結果
次に、event_schedule 列を開始時間 (start_time) と終了時間 (end_time) に分割します。
Pythonのsplit()メソッドは、通常単一の文字列に対して動作しますが、PandasのSeries.str.split()は、str属性によってSeries内の各要素に対して文字列操作が適用できるようになります。そういえば、以前まとめたdtアクセサもPandasのSeriesオブジェクトの属性でした。
# event_schedule列を開始時刻と終了時刻に分割
df_event[['start_time', 'end_time']] = df_event['event_schedule'].str.split('-', expand=True)
df_event出力結果

そして、ここでは終了時間が 00:00 の場合、当日の終わりを示すものとして 23:59 に置換します。
# '00:00'を'23:59'に置換
df_event = df_event.replace({'end_time': {'00:00': '23:59'}})
df_event出力結果

開始時間と終了時間を datetime 型に変換し、合計時間を計算します。
# 時刻データをstr型からdatetime型に変換
df_event['start_time'] = pd.to_datetime(df_event['start_time'], format='%H:%M')
df_event['end_time'] = pd.to_datetime(df_event['end_time'], format='%H:%M')
# イベントの合計時間を計算し小数点第二位まで表示
df_event['total_hours'] = ((df_event['end_time'] - df_event['start_time']).dt.total_seconds() / 3600).round(2)
df_event出力結果

dtアクセサの使い方についてはこちらの記事にまとめています。
最後に、開始時間と終了時間の時刻部分だけを抽出します。
# datetime型の日付データから時刻だけを抽出
df_event['start_time'] = df_event['start_time'].dt.time
df_event['end_time'] = df_event['end_time'].dt.time
df_event出力結果

以上です!これで、別のデータとマージして分析しやすくなりました。
調べていると、今回加工処理を行った列は日付を含んでいないので、to_datetimeではなくto_timedeltaを使うという手もありそうです。
また、今回はイベントを全て同日としたので終了時間が翌日以降の場合を考慮していません。ということで、別の機会に日付データも加えて日付を跨ぐ計算や、to_timedeltaを使った計算についても試してみようと思います!