
大規模視覚言語モデルNABLA-VLおよび日本の「流行食」特化モデルNABLA-VL.foodの開発中間報告

こんにちは、NABLAS R&D事業部です。
先日、NABLASはGENIACの第2期に採択されました。GENIACは、経済産業省および国立研究開発法人新エネルギー・産業技術総合開発機構が協力して実施する日本の生成AIの開発力強化を目的としたプロジェクトで、日本国内の基盤モデル開発力を底上げし、また企業等の創意工夫を促すために立ち上げられました。採択された企業は、計算資源の提供支援、データ・生成AIの利活用に向けた実証の支援、マッチングイベント等の開催や グローバルテック企業との連携支援等を受けることができます。プレスリリースは以下をご覧ください。
NABLASではこの支援を受け、汎用的な大規模視覚言語モデルおよび日本の「流行食」に特化した大規模視覚言語モデルの開発を進めてきました。プロジェクトも折り返しを迎えたところで、今回のnoteではそれらの振り返りを行うとともに今後の展望についても紹介します。
プロジェクトの目標
本プロジェクトの目標は大きく分けて2つあります。1つは社内で大規模モデル開発を継続して行うための土台を整えた上で国産の優れた汎用的な大規模モデルを開発すること。さらに2つ目はある領域を選定し、その領域に特化したモデルを開発すれば独占的に開発されている大規模モデルの性能を局所的に上回れることを示すことです。今回はこの領域として日本の「流行食」を選択しました。理由としては、食は場所や文化的な違いをはじめ、時代的背景に大きく左右されることもあり、特化モデルと汎用モデルの性能の差が出やすい可能性が高く、さらに日本の産業に対しても取り組む意義が最も大きいテーマの一つだと考えたためです。
アーキテクチャと前処理
本プロジェクトで使用するアーキテクチャは、LLaVA-OneVisionを参考にして開発しました。異なる点は、画像エンコーダーにNaViTを使用することで画像をリサイズせずに入力できるようにし、それに伴い複数画像・動画の前処理を変更しました。また、LLMにレジスタと呼ばれる学習可能なトークンを追加しました。
複数画像・動画の前処理に関しては、LLaVA-OneVisionのようにタイルごとに固定数の視覚トークンに変換するとタイルが大きくなる場合がある影響を受け、画像エンコーダー部分でメモリ不足になってしまう問題が見つかりました。この問題を解決するために複数画像・動画が入力された場合にはそれらを格子状に配置して一枚の画像として扱うようにしました。
また、各画像・動画のフレームが何番目に入力されたものであるかを示すために各画像・動画のフレームの左上に連番を割り振るようにしました。このようにして学習されたモデルに試験的に複数画像を入力したところ、各画像に対する指示に適切に応答できたためこの前処理を採用しました。

モデル開発
8Bモデル(NaViT + Qwen2.5-7B-Instruct)の開発から始めました。データセットと学習パイプラインに関してもLLaVA-OneVisionのものを踏襲したものの、こちらもいくつか変更点があります。まず、ステージ1とステージ1.5で使用される画像キャプション・OCR・テキストのみのデータセットに関してそれぞれ日本語版のデータセットを追加で使用しました。ステージ3に関しても同様に利用できるものに関しては、できるだけ日本語版のものを追加で使用したほか、InternVL2.5の技術報告書で記載されたデータセットのテーブルを参考に、いくつか新規のデータセットを追加しました。その際、いくつかデータセットを除外したこと、動画データセットはこの時点で使用していなかったことにより、指示学習時の合計のサンプル数はLLaVA-OneVisionのものとほぼほぼ同じく5M程度にとどまっています。
結果は以下のようになりました。同程度の学習データセット上で学習したLLaVA-OneVisionと比較すると、MMBenchとMMStarを除くベンチマークでスコアが向上しました。特に日本語での質問応答性能が求められるJMMMUでは日本語の学習データセットを追加したため2.3ポイント程度向上しました。
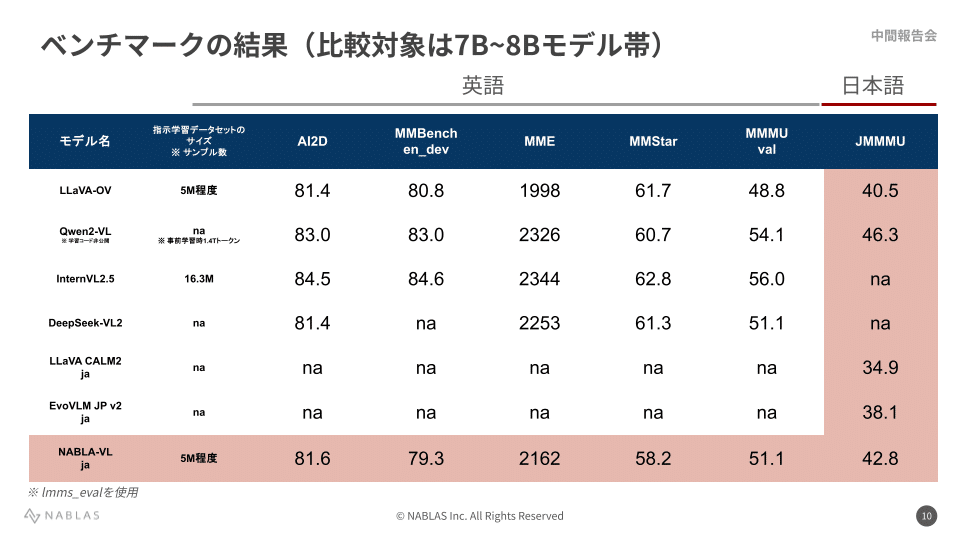
モデルの評価
このテーブルは各ベンチマーク上での評価時に得られたより詳細なスコアです。JMMMUに該当する箇所をみてみると、Chemistry、Finance、Musicといった分野のスコアが低くなっていることがわかりました。
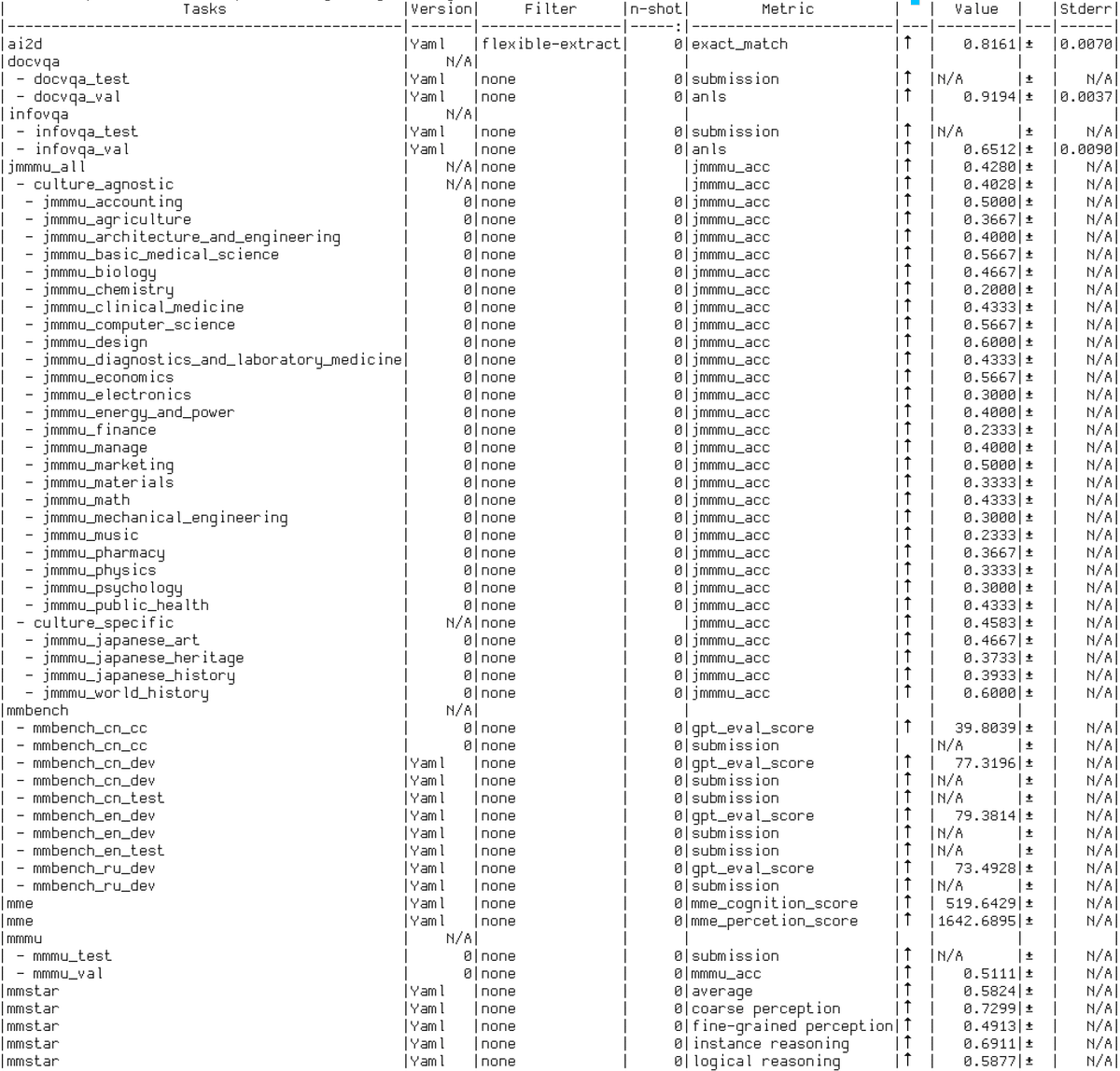
今後、学習データセットを整えてより大きいモデルの開発を行ったあと、MoEモデルの開発に取り組む予定です。結果として得られたモデルやデータセットはより詳細な技術報告書とともに公開する予定となっています!
特定の業界や領域特化の高レベルな課題を解決へと導くために、現在は食品や小売に対してSNSからトレンドを自動取得するAIエージェントを開発していますが、アパレルや広告、不動産、製造業などの分野に拡げていくことができればと考えています。
最後に
今回の大規模視覚言語モデルをはじめ、NABLASのR&D事業部ではディープフェイク検知、音声合成技術、生成AIなどの研究開発に日々取り組んでおります。興味のある方はコーポレートサイトもご覧ください。
また、インターンをはじめ、リサーチャー、エンジニア、ビジネス職など、幅広く募集もしております。オンラインでカジュアルに私たちとお話ししてみませんか?ぜひ、上記コーポレートサイトやWantedly、Linkedinからご連絡くださいませ。解決方法が未知の課題を楽しんで解ける方からのご連絡、お待ちしております!