初心者がNPBのAクラスBクラスの予測モデルを作ってみます

はじめに
Pythonの初心者です。まだ複雑なことはできませんが、プロ野球のデータを使って簡単な分析をしてみました。
本記事の概要
プロ野球のデータで「教師あり学習(分類)」を試します。
翌年度のAクラスBクラスの予測モデルを作ります。
データは少なめですが2009年〜2020年のセ・リーグのものです。
プロ野球データFREAK(https://baseball-data.com/)から拝借しました。特徴量(チームの成績)は適当に選びました。
特徴量:AVG(打率), HR(本塁打), SB(盗塁), ERA(防御率), NOI(New Offensive Index:打者を評価する指標),DIPS(Defense Independent Pitching Statistics:守備の影響とは独立に投手の成績を評価する指標), SAVG(得点平均), LPAVG(失点平均)
目的変数:NFYClass(翌シーズンのクラス:Aクラス、Bクラス)環境
OS:macOS 11.6.2、言語:Python3、エディター:JupyterLab3.0.14
実行したこと
1.手始めに決定木分類(特徴量4)
1)データの前処理
2)モデルの作成と学習
2.特徴量を増やして分類
1)決定木分類
2)ロジスティック回帰
3)ランダムフォレスト
1.手始めに決定木分類(特徴量4)
データの前処理
まず、データを読み込みます。
シーズン毎の各チームのデータと次シーズンのクラス実績です。
import pandas as pd
from sklearn import tree
from sklearn.model_selection import train_test_split
# npb_c_data_220211_2.csv ファイルを読み込んで、データフレームに変換
df = pd.read_csv("npb_cl_data.csv")
df.head(3)
欠損値はないのですが、一応欠損値の有無を確認します。
# 欠損値の有無を確認
df.isnull().sum()
次年度のクラス(A,B)の出現回数をカウントしてみます。
少なめです。
# 次年度のクラスの出現回数をカウント
df["NFYClass"].value_counts()
特徴量と正解データを取り出します。
# 特徴量xと正解データtに分類する
# 特徴量として利用する列のリスト(BattingAverage、HomeRun、BaseStealing、ERA)
col = ["AVG", "HR", "SB", "ERA"]
x = df[col]
t = df["NFYClass"]モデルの作成と学習
まず、訓練データとテストデータに分割します。
# 訓練データとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(x, t, test_size = 0.3,
random_state = 0)
# x_trainのサイズを確認
x_train.shape
モデルを作成して、学習をさせます。
# モデルの作成と学習
model = tree.DecisionTreeClassifier(max_depth = 3, random_state = 0)
model.fit(x_train, y_train) # 学習
正解率を計算します。
# 正解率を計算
model.score(X= x_test, y = y_test)
まあまあの数字が出ました。
特徴量重要度を見てみましょう。
# 特徴量重要度を確認
model.feature_importances
わかりにくいのでデータフレームに変換します。
#データフレームに変換
pd.DataFrame(model.feature_importances_, index = col)
この組み合わせでは盗塁の重要度が高いです。
打率の重要度は0だそうです。
決定木を描画してみます。
# 描画関数の利用
from sklearn.tree import plot_tree
# Plot_tree関数で決定木を描画
plot_tree(model, feature_names = x_train.columns, filled = True)
2.特徴量を増やして分類
1)決定木分析
特徴量にNOI、DIPS,得点平均、失点平均を追加して決定木分析をしてみます。
# 特徴量xと正解データtに分類する
# 特徴量として利用する列のリスト(打率、本塁打、盗塁、防御率、NOI、DIPS,得点平均、失点平均)
col = ["AVG", "HR", "SB", "ERA", "NOI","DIPS", "SAVG", "LPAVG"]
x = df[col]
t = df["NFYClass"]
# 訓練データとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(x, t, test_size = 0.3, random_state = 0)
# x_trainのサイズを確認
x_train.shape
# モデルの作成と学習
model = tree.DecisionTreeClassifier(max_depth = 3, random_state = 0)
model.fit(x_train, y_train) # 学習
model.score(X = x_test, y = y_test)
max_depth = 1でこうなります。
特徴量4のときより低い数字です。

2)ロジスティック回帰
同じくロジスティック回帰でやってみます。
# 特徴量xと正解データtに分類する
# 特徴量として利用する列のリスト(BattingAverage、HomeRun、BaseStealing、ERA)
col = ["AVG", "HR", "SB", "ERA", "NOI", "DIPS", "SAVG", "LPAVG"]
x = df[col]
t = df["NFYClass"]
# 特徴量を標準化する
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
new = sc.fit_transform(x)
# ロジスティック回帰の実装
# 訓練データとテストデータに分割
x_train, x_val, y_train, y_val = train_test_split(new, t, test_size = 0.3, random_state = 0)
# ロジスティック回帰による学習
from sklearn.linear_model import LogisticRegression
model3 = LogisticRegression(random_state = 0, C = 0.1, multi_class = "auto", solver = "lbfgs")
model3.fit(x_train, y_train)
print(model3.score(x_train, y_train))
model3.score(x_val, y_val)
単純な決定木分類と同じ数値です。
3)ランダムフォレスト
ランダムフォレストではどうでしょう。
# ランダムフォレストのインポート
from sklearn.ensemble import RandomForestClassifier
# 訓練データとテストデータに分割
x_train, x_test, y_train, y_test = train_test_split(x, t, test_size = 0.3,
random_state = 0)
x_train, x_test, y_train, y_test = train_test_split(x, t, test_size = 0.3,
random_state = 0)
model2 = RandomForestClassifier(n_estimators = 200, random_state = 0,
max_depth = 3)
# x_trainのサイズを確認
x_train.shape
# モデルの学習
model2.fit(x_train, y_train)
print(model2.score(x_train, y_train))
print(model2.score(x_test, y_test))
深さを1にするとこうなりました。
単純な決定木分析(特徴量4)と同じ数字になりました。
データの少なさゆえでしょうか。

ちなみに特徴量重要度は失点平均と防御率がやや高いです。
ここでも打率の重要度は低いですね。
importance = model2.feature_importances_ # 特徴量重要度
# 列との対応がわかりやすいようにシリーズ変換
pd.Series(importance, index = x_train.columns)
決定木を描画してみます。

正解率の計算
# 正解率 (train) : 学習に用いたデータをどのくらい正しく予測できるか
model2.score(x_train,y_train)
# 正解率 (test) : 学習に用いなかったデータをどのくらい正しく予測できるか
model2.score(x_test,y_test)
学習に用いなかったデータの予測と、混同行列
# 学習に用いなかったデータを予測する
y_pred = model2.predict(x_test)
y_pred
from sklearn.metrics import confusion_matrix # 混同行列を計算するメソッド
# 予測結果と、正解(本当の答え)がどのくらい合っていたかを表す混同行列
pd.DataFrame(confusion_matrix(y_pred, y_test),
index=['predicted 0', 'predicted 1'], columns=['real 0', 'real 1'])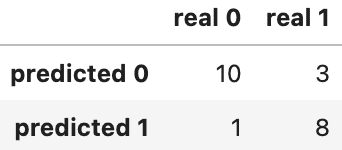
2022年シーズンの予測
2022年シーズンの予測をしてみました。
2021年シーズンの順位で予測していきます。
import numpy as np
# 2021年シーズンのデータで2022シーズンの予測をする
# 新規データ(打率、本塁打、盗塁、防御率、NOI、DIPS,得点平均、失点平均)
# ヤクルト
YS = np.array([[0.254, 142, 70, 3.48, 0.466, 3.74, 4.37, 3.71]])
# 新規データで予測
model2.predict(YS)
# その他のチームの2021シーズンのデータは次の通り
# 阪神
HT = np.array([[0.247, 121, 114, 3.30, 0.437, 3.65, 3.78, 3.55]])
# 読売
YG = np.array([[0.242, 169, 65, 3.63, 0.443, 4.04, 3.86, 3.78]])
# 広島
HC = np.array([[0.264, 123, 68, 3.81, 0.454, 3.97, 3.90, 4.12]])
# 中日
CD = np.array([[0.237, 69, 60, 4.15, 0.454, 3.90, 2.83, 3.34]])
# DeNA
DB = np.array([[0.258, 136, 31, 3.22, 0.401, 3.49, 3.91, 4.36]])結果、決定木分析でもランダムフォレストでも以下の結果となりました。
2021年シーズンのAクラス3球団に中日が絡むようです。
・ヤクルト Aクラス
・阪神 Aクラス
・読売 Aクラス
・広島 Bクラス
・中日 Aクラス
・DeNA Bクラス
まとめ
単純な項目でもAクラスBクラスの予測には使えそうですね。
データ量を増やし、特徴量の組み合わせを調整して正解率を上げていきたいです。
おわりに
まだまだ勉強が足りませんが、地道に努力して行きます。