
Open-WebUIでRAGしてみる

超絶初心者が、ollama+Open-WebUIの環境でRAGをしてみました。
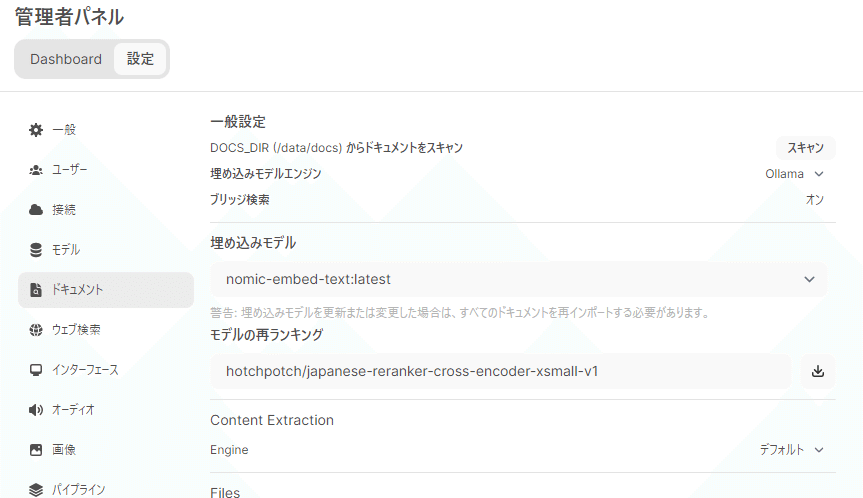
管理者パネルでの設定
管理者パネル>設定>ドキュメント での設定です。
ポイント
ちゃんとした文書データを用意しましょう
「モデル再ランキング」でちゃんとリランカー導入しましょう
「埋め込みモデル」はデフォルトじゃない方がいいかもしれん・・・
ちゃんとした文書データを用意しましょう
検索で使用するファイルを用意しましょう(当たり前)
これには、”前処理してきれいなデータにしましょう!”も含みます。
テキストファイル推奨らしいです。
<context>タグで囲うのを忘れずに!
※以下は、私がやったことを参考までに記載します※
「dokuwiki」でFAQサイトを運用していたので、これを元データとして利用しました。DBを使わない、1ページ=1テキストファイルで保存するタイプのwikiなので、サーバーからそれらを引っこ抜いてきました。
これに、改行のみ行削除や余計なスペース削除、wiki記法部分の削除・置き換えなどを、適当なスクリプトで処理します。(Powershell使いました)
変換具合や余分な部分の除去具合を見ながらスクリプトを修正&実行していきます。
このファイルに関しては、ベクトル化&検索で使われて、生成モデルの結果にもモロに反映されてくるので、そういったことを考えつつ、「いいかんじ」な文書ファイルになるよう処理するようにしました。
ちなみに、”テストで1個、2個ファイル登録してみよ~”くらいだと
一見、RAGちゃんと動いてないっぽい風なんですが、ちゃんと動作してます。1個2個じゃあ、”ベクトル化してる感”が感じられないんですよね。
20とか30ファイル登録すると、処理してるな~感がします。
「モデル再ランキング」でちゃんとリランカー導入しましょう
(たいして資料や文献読んだわけじゃないので妄想が大部分ですが)
生成モデルにデータ投げる前の「検索・文書埋め込み処理」で、文書検索したまんまの情報を利用してると、”文書の関連度合いに関係なく、とにかく検索に引っかかってきたファイルたち”を埋め込んで、生成モデルに投げることになるので、モデルから戻ってくる結果も精度が低くなることが頻発します。
なので、検索・文書埋め込み処理時に、文書検索の結果をリランキングして関連度の高い文書を埋め込んでやるようにします。とはいっても、リランキングのモデルを入れてやるだけです。
[huggingface rerank japanese] とかで検索してやると出てきます。
で、以下のモノを入れてみました。
「ブリッジ検索」を”オン”にしないと入力欄が出てこないので、そこはちゃんと”オン”にしておいてください。
マシンのスペックの都合で一番小さいヤツを導入しました。好きなのを入れれば良いと思います。これだけで超まともな返答が返るようになりました。
これを、Open-WebUIの「モデル再ランキング」のとこに貼り付けてDLします。ダウンロードの途中経過とか表示されないですが、ちょっと待ってると完了します。
「埋め込みモデル」はデフォルトじゃない方がいいかもしれん
ちょっと調べたら、デフォルトの埋め込みモデル「Sentence Transformers」は、パラメータ数が少ないような気がして、他のヤツを導入してみました。別に、デフォルトでも良いような気もしますが、この辺は未検証です。それぞれの環境などに合わせて、という感じでしょうか。
それから、「埋め込みモデル」を変更したら、いったんドキュメントを全部削除して、再アップしないとダメなので注意!
デフォルト(パラメタ数)
sentence-transformers/all-MiniLM-L6-v2(22.7M)
※デフォルトで選択できます。HuggingFaceに上がってるので詳細はそちらで確認できます。
候補その1:nomic-embed-text(137M)
候補その2:mxbai-embed-large(334M)
※設定画面で、埋め込みモデルエンジン「Ollama」にすると利用可。
ollamaにモデルとして登録してあるヤツなので導入も簡単です。そのかわり、「Ollamaパワー」を使うことになります。
「ollama list」で確認できます。
(nomic-embed-textの方がDL数が多いので候補その1としました。)
そのほか設定するところ
■クエリパラメータ > トップK
検索した文書をいくつ利用するか?の値。
多ければ、多分重くなる気がする。
■チャンクパラメータ > チャンクサイズ、チャンクオーバーラップ
「チャンク」というモノに分割して処理をしてます。それの設定。
「チャンクサイズ」で、ファイルをぶった切って処理する、それのぶった切るサイズを指定。
「チャンクオーバーラップ」で、どれだけチャンクをオーバーラップさせるか指定。
どちらも文書などに合わせて調整が必要かと思うが、
大きすぎない方が良いらしい。
ファイルの登録・モデルへの設定
「ワークスペース」から入って設定などします。
ファイル登録
ワークスペース>ドキュメント から行います。
「+」ボタンでも、ドラックアンドドロップでも、お好みでファイルを追加します。複数ファイル登録する場合は、ちょっと時間がかかります。
(ここで文書をベクトル化して保存してる)
もしくは、(話は戻りますが)
dockerのOpen-WebUIのボリュームの、docsディレクトリに入れて、
管理者パネル>設定>ドキュメント のスキャンボタンで
登録(取り込み)します。
(場所はここ⇒/var/lib/docker/volumes/open-webui/_data)
こっちの場合だと、ディレクトリ作って入れることができます。
ディレクトリ=タグ みたいな感じで取り込みが行われるので、タグ付けしなくて良いので楽です。
モデルへの設定
ワークスペース>モデル から設定していきます。
「モデルを作成する」から...…
・「名前」は適当に。[モデル名-RAG] とか。
・「ベースモデル」は、既存のヤツを何か選んで
・「システムプロンプト」も適当に。「日本語で返答してください」とか?
・「Knowledge」は[Select Documents]から、上で登録したファイルを選択
運用などにもよるとは思いますが、
表示されてる、利用可能な既存モデルに直接追加するより、
上でやったように「モデルを作成する」から、既存モデルに文書ファイルを追加する形で新たに作成した方が良いと思います。
「ノーマルバージョン」と「文書ファイル追加したRAGバージョン」を作ってあった方が多分便利。
※おまけ
管理者パネル>設定>ドキュメント の一番上
「DOCS_DIR (/data/docs) からドキュメントをスキャン」について
このページでは、文書ファイルを手動で追加などしましたが、
dockerで立ち上げる際に、あらかじめファイルを配置するように設定を入れておいて、その際にファイル取り込みんでベクトル化する用のボタンだと推測されます。後で手動で入れてスキャンして取り込みもできますが・・・
dockerファイルでDOCS_DIRフォルダに文書ファイルを配置するように指定⇒「スキャン」ボタンで取り込み
ちなみに、特にいじってなければココ
/var/lib/docker/volumes/open-webui/_data