
《Python/GIS》国土数値情報のシェープファイルから全国の施設の分布や市区町村別個数を調べる方法

国土交通省が提供している国土数値情報のデータを用いて、全国の公共施設の分布を可視化したり、市区町村別の個数を数えたりすることができます。今回は、その手順について説明します。
*国土交通省より、商用での利用は禁止されています。
データの準備
まず、以下の国土数値情報のサイトにアクセスします。
下にスクロールし、調べたい施設をクリックしてください。
ここで、「ポイント」というのは施設を点で表示し、「ポリゴン」とは施設を図形で表示することを指します。

下にスクロールし、ダウンロードするデータの範囲を選択します。
例)「全国」「奈良県」
私は例として、「全国」のデータを使用しました。zipファイルがダウンロードされるので、解凍します。
シェープファイルについて
ここで、ダウンロードしたデータがどうなっているか見てみましょう。
データは「シェープファイル」という形式になっています。
フォルダの中に拡張子の異なる(.shpや.shxや.dbfなど)複数のファイルがあるかと思います。これらすべてが相互に作用し合って1つの地理データを構成しているのです。
この中でも特に重要な.shpの拡張子を持つファイルを見てみましょう。私の場合は以下のようにシェープファイルを整理し、「公共施設個数取得コード.ipynb」というPythonファイルを作成しました。
(ご自身で整理される場合は、パスの部分を各自変更してください。)
>作業用フォルダ
>公共施設個数取得コード.ipynb
>data
>国土数値情報
>全国郵便局P30-13
>P30-13
>P30-13.shp など一式
公共施設個数取得コード.ipynbに、以下のようなコードを書きます。
import geopandas as gpd
import matplotlib.pyplot as plt
# 1. シェープファイルの読み込み
shapefile_path = "data/国土数値情報/全国郵便局P30-13/P30-13/P30-13.shp" # 郵便局のシェープファイル
gdf = gpd.read_file(shapefile_path)
# 2. データの基本情報を確認
print("データの基本情報:")
print(gdf.head()) # 最初の5行を表示
print("\nカラム一覧:")
print(gdf.columns) # カラム(列名)を確認
# 3. 施設の個数を確認
total_facilities = gdf.shape[0]
print(f"\n郵便局の総数: {total_facilities}件")
# 4. 施設分布の地図プロット
gdf.plot(figsize=(10, 10), color="blue", markersize=5, alpha=0.5)
plt.title("distribution of post office in Japan")
plt.xlabel("longtitude")
plt.ylabel("latitude")
plt.show()# 2で、.shpファイルの中身を確認します。
# 3で、全国の郵便局数を確認します。(まだ市町村別にはできません)
# 4で、施設分布を地図にプロットします。
コードを実行すると、以下のように.shpファイルの中身を確認できます。

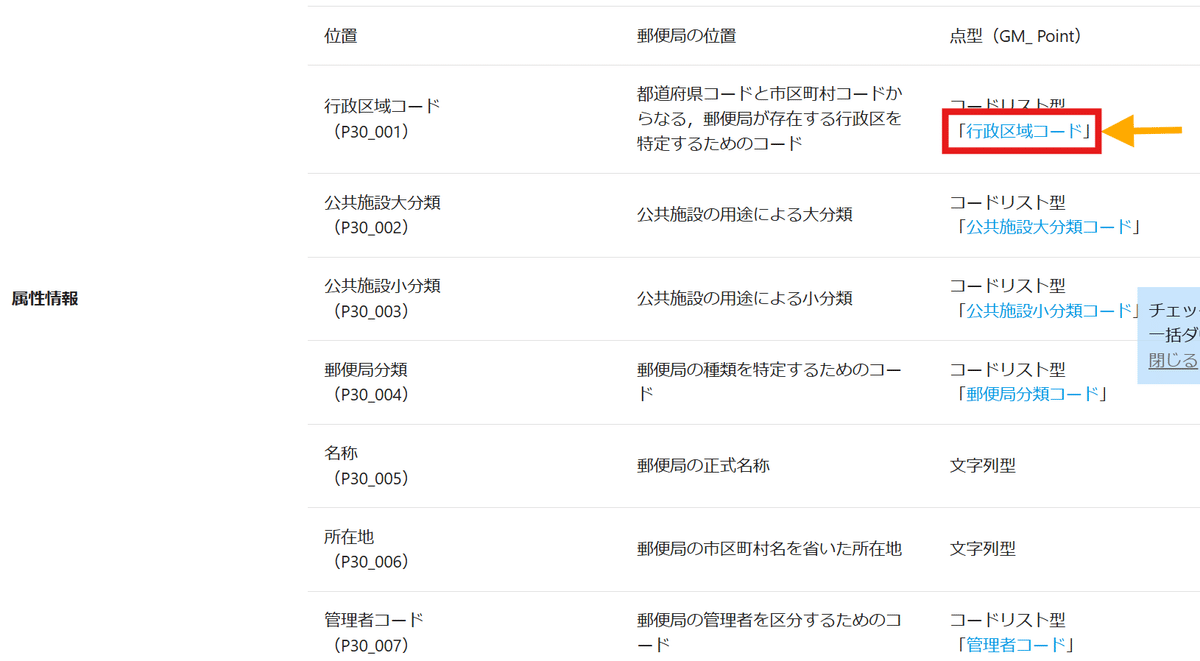
P30_001からP30_007までの列名と緯度経度を意味する列名などがあります。
P30_001からP30_007の意味については、先ほどのダウンロード画面に書いてあります。
また、# 4の実行結果として、日本の郵便局の分布が描画されます。

もう少し細かい分布を見たい場合は、QGISというソフトウェアと、行政区域データのシェープファイルを用いるのがおすすめです。詳しくは別記事で述べようと思います。
市町村別の郵便局数を取得
先ほどの.shpファイルの「P30_001」という列(1列目)は、5桁の市町村コードを意味しています。これをもとに、市町村名と照らし合わせます。
まずは、「P30_001」列でgroupbyすることで、各市町村コードのデータが何行存在するかを計算できます。
*groupbyは、( )内で指定した列に対して同じ値が登場する回数を返します。
#市町村別の施設の個数を確認
city_count = gdf.groupby("P30_001").size().reset_index(name="郵便局数")
city_count.shape
print(city_count)
これではまだどの市町村なのかわからないので、ダウンロード画面の「行政区域コード」をダウンロードします。これは、市町村コードと市町村名が一覧になったExcelファイルです。
ダウンロードした「行政区域コード」の中身は以下のようになっています。
今後pandasで作業を行う際、列名を取得したいので、上2行を削除します。

削除したらファイルを保存し、先ほどの作業用フォルダの中に入れます。
行政区域コードと郵便局シェープファイルを結合
今の行政区域コードと、先ほど扱った郵便局のシェープファイルは、ともに5桁の市町村コードの列を持っています。pandasのmergeを用いて、この列を基準に結合します。
1点注意点として、市町村コードは文字列 (str) 指定をしないと、先頭に0をもつコードは4桁の数字として扱われてしまいます。
不要な列は取り除き、必要な「都道府県名」「市区町村名」「郵便局数」の3列のみを抽出し、最後にExcelファイルに出力して完成です!!
import pandas as pd
# ファイルをDataFrameとして読み込み
#5桁の市町村コードを文字列として扱うため,dtype=strで読み込み(これをしないと先頭が0のコードは4桁と認識されてしまう)
city_code = pd.read_excel("AdminiBoundary_CD.xlsx",dtype={"改正後のコード": str})
city_count["P30_001"] = city_count["P30_001"].astype(str)
# 5桁の市町村コードを基準に結合する場合
merged_df = pd.merge(city_code, city_count, left_on="改正後のコード",right_on ="P30_001", how="left")
#不要な列は除き、「都道府県名」「市区町村名」と「郵便局数」の3列のみを抽出
selected_merged_df = merged_df.iloc[:, [1,2,12]]
#print(merged_df)
print(selected_merged_df)
# 結果をExcelファイルに出力
output_excel = "都道府県市区町村名と郵便局数.xlsx"
selected_merged_df.to_excel(output_excel, index=False, engine="openpyxl")
ちなみに政令指定都市は、各区ごとに郵便局数が与えられているため、市の行は空欄になっています。
今回の記事は以上になります。この記事が少しでもご参考になったと思って頂けたら、いいねやフォローをしていただけるととても力になります。