
noteのLLMワークフローを紹介します!!(構築/運用編)

こんにちは、note AI creativeの武藤です。
※こちらの記事はnoteのLLMワークフロー紹介の後編です。
前編として、LLMワークフローの「技術選定編」を書きました。
前編記事はこちら。
noteは毎日数万件の規模でコンテンツが集まるプラットフォームなので「色々な観点でLLMを使って評価できないだろうか?」という要望が多くあります。そうした要望を叶えていくために下記の技術選定をしました。
運用段階のLLMワークフローとしてArgo Workflowsを採用
検証/PoC段階のLLMワークフローとしてDifyを採用
note AI creativeでは上記のLLMワークフローを使って開発と運用をしていますが、関係者のAIに対する期待値を適切にコントロールしながら検証できて、さらに運用フェーズでも安定稼働しています。
今回は後編としてArgo Workflowsを構築してLLMワークフローを運用する話をしていきます。
LLMワークフロー設計
それではまず最初にLLMワークフロー設計を見ていきましょう。
※ 大人の事情であまり具体的なことは書かずに目隠ししている部分は多少ありますが、ご了承ください。

ワークフローの各ステップを簡単に書くと下記のようなフローになります。
1. 対象記事IDの取得
Argo Workflowsはスケジュールを設定してワークフローを実行できます。
スケジュール実行してリクエスト用のSQSから対象記事IDを取得可能。またはArgo Workflowsの管理画面から対象記事IDを渡すこともできる
2. 前処理
対象記事IDを使ってnote RDBの記事テーブルからデータを取得して、記事本文などを前処理する
3. LLM判定(複数回)
Parameterテーブルからtemperature、プロンプトなどのパラメータを取得。パラメータ、記事本文、プロンプト等を使ってLlmServiceに問い合わせて、LLM判定結果を取得
4. 結果の集約
LLM判定結果を集約してDBに保存したり、別途SQSにエンキューしたりする
また、プロンプトや各種LLMのパラメータはソースコードに直書きせず、パラメータ管理画面から設定できるようにします。このようにすることでプロンプト等をノーデプロイで、すぐに本番環境に反映できるようにします。
パラメータ管理画面のほかにも、実行履歴/リトライ管理画面を用意することで運用の負担を軽減しております。
LLMワークフロー実装
次にLLMワークフロー実装の方を見ていきます。
実装は大まかに下記の2種類がありますので、それぞれについて紹介します。
基本的にRubyで開発しているので各ステップ実行はrakeタスクとして実装します。(もちろんPythonとかで代替可能です)
1.Argo Workflowsのyaml
対象記事の取得や前処理といった各ステップの実行順、並列/直列などを記述
2.Argo Workflowsから呼び出すrakeタスク/Serviceの実装
各ステップから呼び出されるrakeタスク/Serviceを実装する
1.Argo Workflowsのyaml
対象記事IDの取得や前処理といった各ステップの実行順などを記述します。
各ステップを直列/並列で実行するように調整でき、もしワークフローの途中で処理が失敗しても失敗通知するといった設定ができます。
例としてArgo Workflowsのyamlを書いておりますが、下記のcommand部分でrakeタスクを実行するように設定します。
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
spec:
entrypoint: main
envFrom:
- configMapRef:
name: app-config
volumes:
- name: workdir
hostPath:
path: ${REPO_PATH}/k8s/development/tmp
type: DirectoryOrCreate
templates:
- name: main
steps:
- - name: step1
template: step1
- - name: step2
template: step2
- name: step1
container:
image: app:latest
imagePullPolicy: IfNotPresent
command: [bundle, exec, rake, "sample_workflow:step1"]
- name: step2
container:
image: app:latest
imagePullPolicy: IfNotPresent
command: [bundle, exec, rake, "sample_workflow:step2"]2.Argo Workflowsから呼び出すrakeタスク/Serviceの実装
次にArgo Workflowsから呼び出すrakeタスクを書きます。
command: [bundle, exec, rake, "sample_workflow:step1"]のように書いているので、その呼び出し方に沿ってrakeの実装を書きます。
# frozen_string_literal: true
namespace :sample_workflow do
desc 'step1'
task step1: :environment do |task|
Example::Step1.new(
workflow_key: 'sample',
step_id: task.name,
).run
end
desc 'step2'
task step2: :environment do |task|
Example::Step2.new(
workflow_key: 'sample',
step_id: task.name,
).run
end
endLlmServiceなどのサービス群の実装もありますが、文章が長くなりそうなので今回は省略させてください。
最終的にArgo Workflowsの管理画面からワークフローを実行してみると下記のような画面になります。RESUBMITボタンなどで再実行もできます。
LLMワークフローが初めて動いた瞬間は特にドーパミンが出ました。
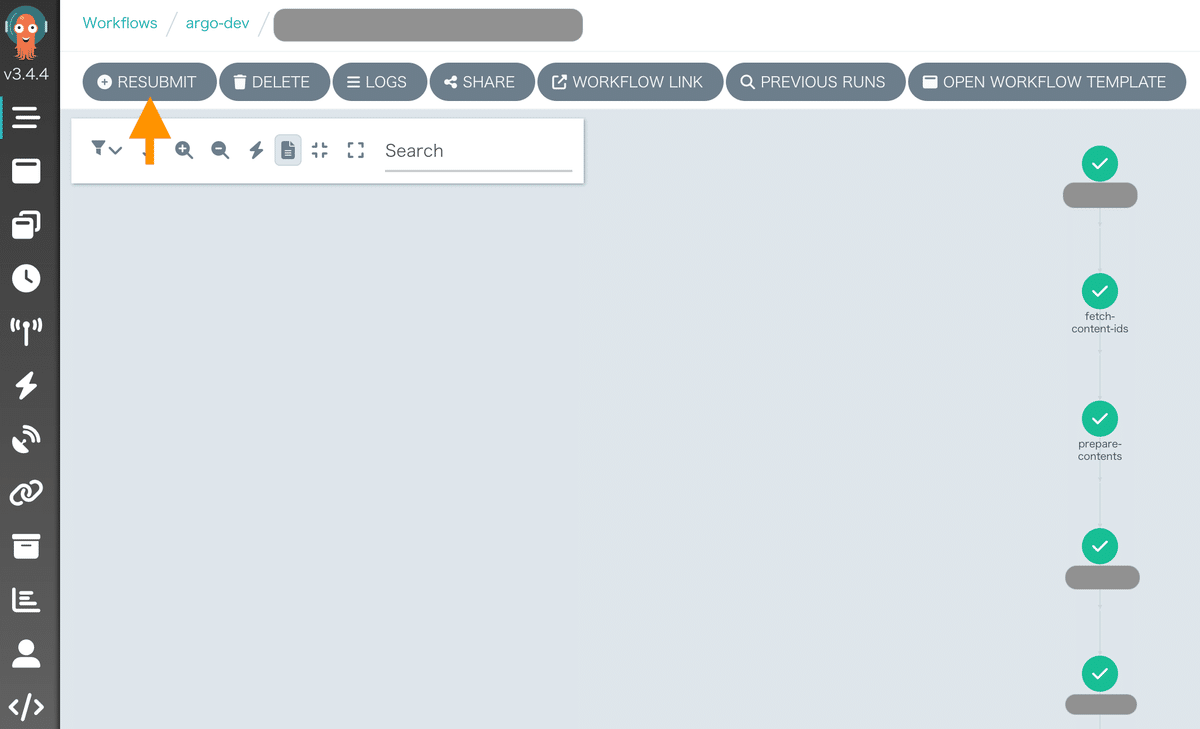
LLMワークフロー管理画面
次にワークフローに関する管理画面をご紹介します。
1. 実行履歴/リトライ管理
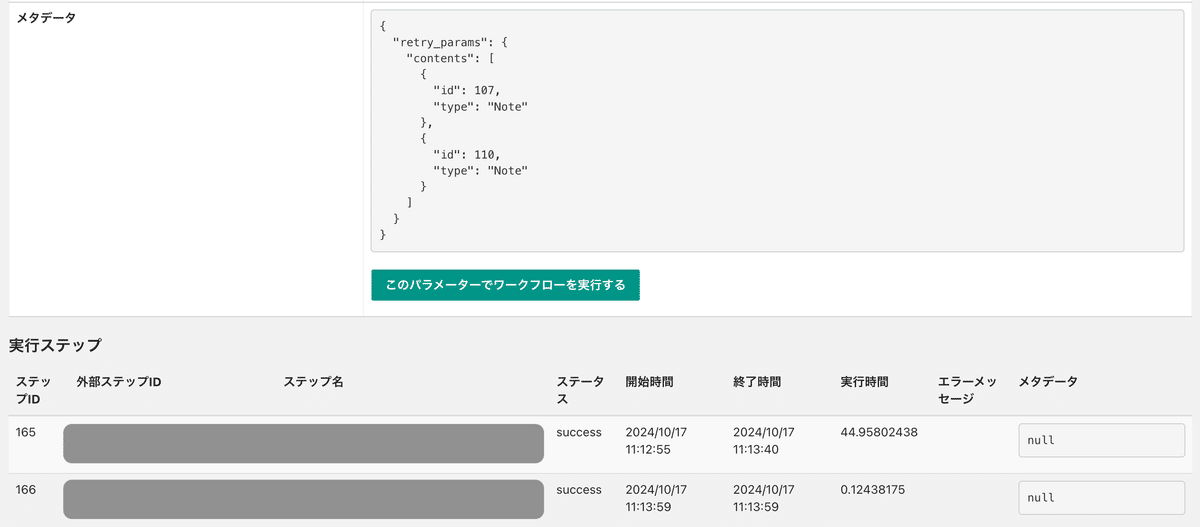
Argo Workflowsの管理画面でもジョブ実行履歴は残るのですが、永続的にDBに残して参照できるようにしたかったので、実行履歴画面を別途作成しております。
またワークフローの実行中にLLMのrate limit等で一部データが欠損してしまうことは時々起きるので、失敗したデータに対してリトライ処理を実行できるように半自動化しています。
2. パラメータ管理
プロンプトなどのパラメータを管理するための画面も用意しています。
本番環境でどのバージョンが適用されているか、いつ変更したのかといったことも管理できるようにしています。
プロンプトを少し変更しただけでアウトプットが大きく変わる可能性があるので、サービス品質を維持するためにも必要となります。

運用していく中で見えてくる課題の数々
上記のようにワークフローの設計と実装をしてきましたが、運用していく中で色々と課題が見つかることがありました。
なので私たちが直面した課題と解決策についても紹介したいと思います。
# 課題一覧
1.ワークフローをローカルデバッグできるようにしたい
2. JSON出力の失敗をもっと少なくしたい
3.LLMのロードバランスをできるようにしたい(rate limit問題)
4.LLMを並列実行できるようにしたい
1.ワークフローをローカルデバッグできるようにしたい
MLOpsなどのワークフロー実行においてもローカル環境でワークフローを実行しにくいという課題は多いと思います。私も昔Step Functionsで開発していて本番環境のエラーをローカルで再現できなかったりして苦心しました。
しかしArgo Workflowsではうまくローカル環境を整えた上で、下記のようなコマンドを実行することでローカル環境上でArgo Workflowsを実行できます。
## port-forwardを利用してArgo Workflows UIを見れるようにする
kubectl --context docker-desktop -n argo-dev port-forward service/argo-server 2746:2746
## ブラウザで下記にアクセスしてArgo Workflows yamlを貼り付けて実行する
https://localhost:2746/workflow-templates?namespace=argo-dev&sidePanel=trueさらにVSCodeのデバッグ設定などを用意して、それぞれのrakeタスクごとにデバッグできるようにしてあげれば、開発がしやすくなります。
# VSCodeのlaunch.json
{
"version": "0.2.0",
"configurations": [
{
"type": "rdbg",
"name": "Debug sample_workflow:step1",
"request": "launch",
"cwd": "${workspaceRoot}",
"script": "bin/rake",
"args": [
"sample_workflow:step1"
],
"askParameters": false,
"useBundler": true
}
]
}ワークフローのローカルデバッグのしやすさは見落としがちな観点なので早めに解決できて安心でした。
2. JSON出力の失敗をもっと少なくしたい
LLMの結果をJSON出力する場合、階層構造が深いJSONだとJSONパースエラーとなるケースが結構ありました。
しかしながらAzureのGPT-4oでStructured Outputに対応しているということに気づいて、ドキュメントの通りに型を設定して運用したところ、JSONパースエラーはほぼなくなりました。
安定してJSON出力させたいという要望は多いと思うので、困っている方はぜひ試してみてください。
3.LLMのロードバランスをできるようにしたい(rate limit問題)
例えば、Azureの1つのリージョンのAzure OpenAI Serviceを使っていて使用トークンや負荷が多くなってくるとrate limit問題が浮上してきます。
これは非常に厄介な問題です。
Microsoftの方に伺ったところ「Azure API Managementを経由して複数のAzure OpenAI Serviceをロードバランスさせることでrate limit問題を緩和できる」と教えてくれました。

https://github.com/Azure-Samples/AI-Gateway/tree/main/labs/advanced-load-balancing
Microsoftの方に共有いただいた上のリンクのbicepを少し修正して、Azure API Managementをデプロイしたところ、3つのリージョンのAzure OpenAI Serviceでロードバランスさせることに成功しました。
さらに下記の実装のBEFORE/AFTERのようにエンドポイントとキーを変更するだけでロードバランス機能を使えるというのが非常に便利でした。
rate limit問題でお悩みの方はぜひご検討いただければと思います。
BEFORE(Azure OpenAI Serviceのエンドポイント)
# frozen_string_literal: true
class AzureClientFactory
def openai(deployment_name)
OpenAI::Client.new(
access_token: ENV['AZURE_OPENAI_API_KEY'],
uri_base: "#{ENV['AZURE_OPENAI_ENDPOINT']}/#{deployment_name}",
api_type: :azure,
api_version: '2024-08-01-preview'
)
end
endAFTER(エンドポイントをAPI Managementに変更)
# frozen_string_literal: true
class AzureClientFactory
def openai(deployment_name)
OpenAI::Client.new(
access_token: ENV['AZURE_APIM_KEY'],
uri_base: "#{ENV['AZURE_APIM_ENDPOINT']}/#{deployment_name}",
api_type: :azure,
api_version: '2024-08-01-preview'
)
end
end4.LLMを並列実行できるようにしたい
実は上記のrate limit問題のため、Argo Workflowsの各LLM判定ステップを直列実行してrate limitにならないようにするという背景がありました。
しかしLLMをロードバランスできるようになったので各LLM判定ステップを並列実行してもrate limitが起きずに実装できそうです。
さらにArgo Workflowsの並列実行はものすごく簡単に実装できます。
下記のようにLLM判定ステップを直列実行するyamlと、並列実行するyamlを見比べて欲しいのですが、ハイフンをつけるか、つけないかの違いです。
BEFORE(直列実行バージョン)
templates:
- name: main
steps:
- - name: llm-check-1
template: llm-check
- - name: llm-check-2
template: llm-check
- - name: llm-check-3
template: llm-checkAFTER(並列実行バージョン)
templates:
- name: main
steps:
- - name: llm-check-1
template: llm-check
- name: llm-check-2
template: llm-check
- name: llm-check-3
template: llm-checkこのようにして並列実行させると下記のような実行画面となります。
Argo Workflowsでワークフローを実行するように技術選定してよかったなと思う瞬間でありました。
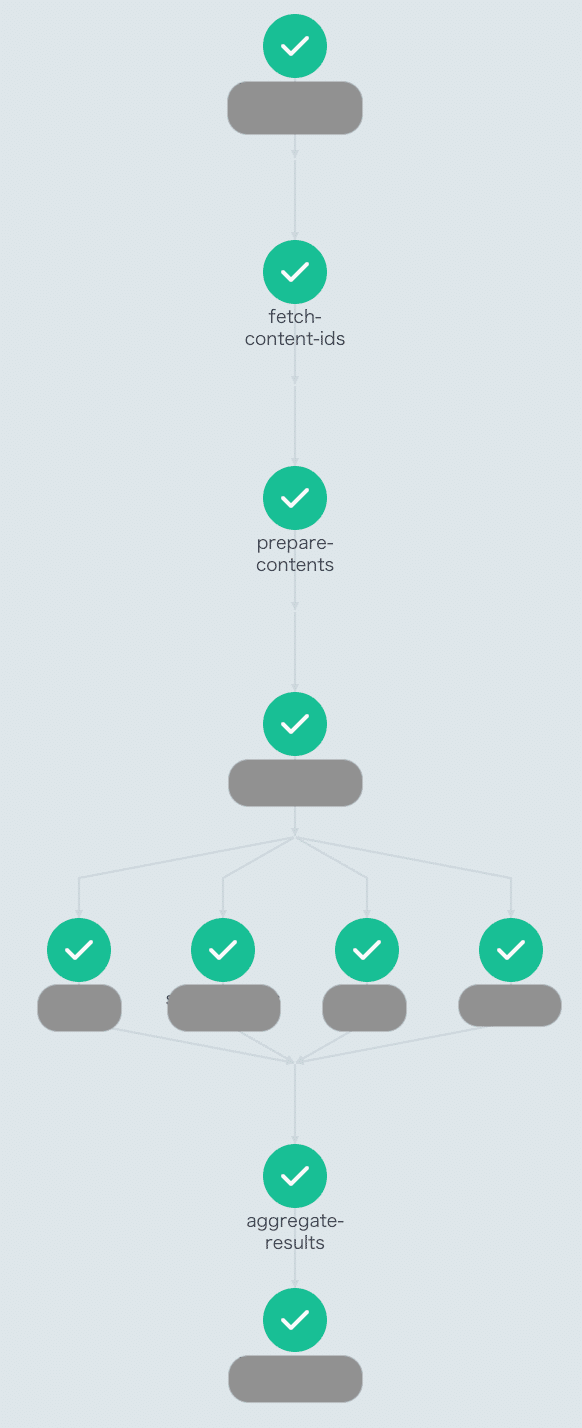
カイゼンの旅は終わらない...
ワークフローの設計から実装/運用までをやってきましたが、非常に大変な道のりでした。しかしカイゼンの旅はまだまだ終わらなさそうです。
今後のカイゼンとしては、例えばLLMのバッチ推論APIを使えるようにするといった方向性がありそうです。バッチ推論APIが加わることで、低コストで色々なアーキテクチャのLLMワークフローを作れそうと思います。
https://platform.openai.com/docs/guides/batch
このようにLLM界隈は新しい技術ばかりでワクワクと戸惑いが多いですが、誠実に課題解決していけば、ユーザーの皆様に最高の価値を提供できるAIプロダクトに近づいていけるのではないかと思います。
今後とも精進していきたいです。
お時間を割いて読んでいただきありがとうございました!
▼noteエンジニアの記事が読みたい方はこちら