
画像からテキストを検出するwebアプリを開発してみました

はじめに
自己紹介
むぎなすびと申します。むぎは飼い猫の名前です。職業はメーカーの研究開発職(非IT業務)で、プログラミングの初心者です。DXスキルを身につけるために、アプリ開発にチャレンジしました。
背景
この記事は筆者が通うプログラミングスクール Aidemy Premium のカリキュラムの一環で卒業制作の記録として書いたもので、受講修了条件を満たすために公開しています。
タイトルの通り "画像からテキストを検出するwebアプリ" を制作し、一般ユーザーが使用可能なwebサービスとして公開する事を、修了課題のテーマとしました。
成果物の紹介
制作したテキスト検出アプリを、「TXT DETECTOR」と名付け、
Render にデプロイして webサービスとして公開中です。
TXT DETECTOR
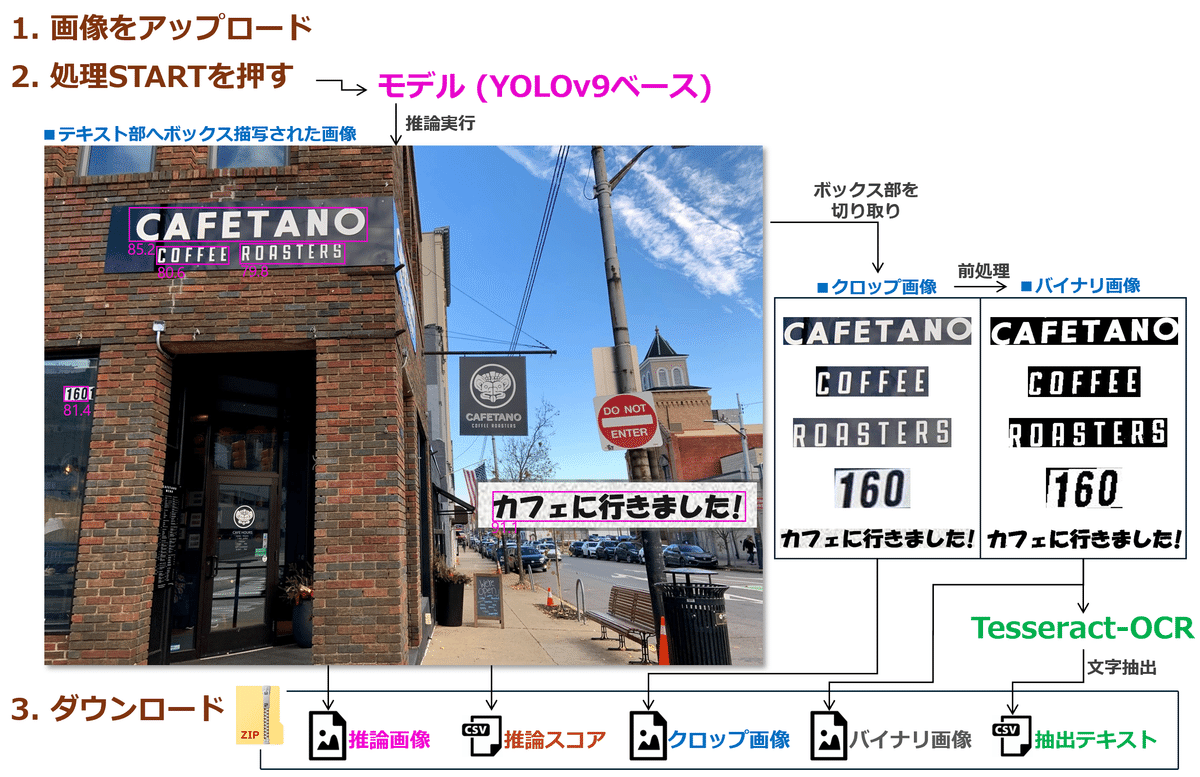
画像をアップロードし処理STARTをクリックするのみで、その他の操作はありません。処理完了後、バウンディングボックス付画像、推論スコア、クロップ画像、 バイナリ(白黒二値化)画像、抽出テキストの結果が作成され、
これらをzip形式でダウンロード可能です。
テーマ選定理由
このテーマを選んだきっかけは、我が家の息子(当時月齢10ヵ月)です。
テーマ選定をする2か月ほど前から息子の離乳食が始まったのですが、妻が毎食の離乳食を写真に撮り、その日何をどれくらい食べたかを写真上にコメントを入れ記録として残していました。食事後に万が一発作やアレルギーが出た場合に、お医者様に食事内容を正しく説明するための備えです。

ただし、撮影後その場でテキストを編集で書き込み、画像として保存するという記録手法を取っていたため、肝心の食事の内容はあくまでも "画像" としてしか保存されておらず、テキストデータとしては管理できていないという課題がありました。
(記録作業がすぐ済むよう、手間の少なさを優先したためです。)
上記のような記録写真は、この時すでに200枚ほどありました。
これまでの記録全てを手動でテキストに起こすのは工数的に非効率であり、また今後の記録手法も変えるつもりはないため、既存の画像からテキスト部分を自動で読み取り、テキストデータにするシステムが必要でした。
そこで、画像からテキストを検出するアプリの作成をテーマとして選定しました。
アプリ開発の方向性の検討
現状把握① - OCRの検出精度の確認
画像中のテキストを文字データに変換するために、 "OCR" 技術を活用する事を検討しました。そこでまずはお試しで、PythonにてOCRエンジンを起動させ、サンプル画像のテキストを抽出してみます。OCRエンジンには Tesseract-OCR を利用します。
# test_ocr.py
# ライブラリインポート
import pyocr
from PIL import Image, ImageEnhance
import os
import glob
from datetime import datetime
# Path設定
TESSERACT_PATH = r'C:\\Program Files\\Tesseract-OCR\\' #インストールしたTesseract-OCRのpath
TESSDATA_PATH = r'C:\\Program Files\\Tesseract-OCR\\tessdata' #tessdataのpath
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# OCRエンジン取得
tools = pyocr.get_available_tools()
tool = tools[0]
print(tool) #確認
# 析画像読み込み関数
def get_img_list(pic_folder_path):
img_list = glob.glob(pic_folder_path)
return img_list
# 画像前処理関数
def pretreat_img(img, threshold):
img_g = img.convert('L') #Grayscale変換
enhancer= ImageEnhance.Contrast(img_g) #コントラストを上げるための設定
img_con = enhancer.enhance(2.0) #コントラストを上げる処理を実行
img_bin = img_con.point(lambda x: 0 if x < threshold else 255, '1') # バイナリ化適用(二値化)
return img_bin
# 画像からOCRで日本語を文字列として抽出する関数
def pic_to_txt(img_bin, lang, tesseract_layout_set):
builder_pyocr = pyocr.builders.TextBuilder(tesseract_layout=tesseract_layout_set)
txt_pyocr = tool.image_to_string(img_bin, lang=lang, builder=builder_pyocr)
txt_pyocr_space_cut = txt_pyocr.replace(' ', '') #半角スペースを消す ※読みやすくするため
return txt_pyocr_space_cut
# フォルダ内の画像リストに対してイテレーションして辞書に格納する関数
def PICs_OCR_to_dic(pic_folder_path, threshold, lang, tesseract_layout_set):
img_dic = {} #元画像を格納する辞書を初期化
img_bin_dic = {} #前処理後画像を格納する辞書を初期化
txt_dic = {} #抽出したテキストを格納する辞書を初期化
extension_dic = {} #元画像の拡張子を格納する辞書を初期化
img_path_list = get_img_list(pic_folder_path)
for img_path in img_path_list:
img = Image.open(img_path)
img_bin = pretreat_img(img, threshold)
txt = pic_to_txt(img_bin, lang, tesseract_layout_set)
img_basename = os.path.basename(img_path)
img_name = os.path.splitext(img_basename)[0]
extension = os.path.splitext(img_basename)[1]
img_dic[img_name] = img
img_bin_dic[img_name] = img_bin
txt_dic[img_name] = txt
extension_dic[img_name] = extension
return img_dic, img_bin_dic, txt_dic, extension_dic
# 関数を実行しフォルダ内のOCR結果を辞書形式で取得
pic_folder_path = '.\sample\*'
threshold = 180 # 閾値の設定(0-255)※結果を見ながら要調整
lang = 'jpn'
tesseract_layout_set = 11 # OCRの設定 ※背景無しで複数行ある場合は通常"6"、デフォルト値は"3"
img_dic, img_bin_dic, txt_dic, extension_dic = PICs_OCR_to_dic(
pic_folder_path,
threshold,
lang,
tesseract_layout_set
)
#結果表示の設定
sample_num = "***" #結果を表示したい画像No.を入力
file_name_ = "ocr_sample_"
key = file_name_+sample_num
print(txt_dic[key]) #OCRテキストを表示 上記OCRテスト用のスクリプトでは、画像ファイルを読み込み、前処理(グレースケール化、コントラスト調整、バイナリ化)し、特定のTesseractモードにて文字抽出をして結果を辞書形式で保存する処理をします。OCRエンジンとして、Tesseract-OCR (Windows版)、tessdata(言語学習データ)は jpn.traineddata、pythonでOCRエンジンを操作する外部ライブラリとして pyocr を選定しました。
以下は、2つのシンプルなサンプル画像に対するOCRの実行結果です。



どちらのサンプル画像も、OCRによるテキスト抽出が正しく出来ています。
では、これを課題である前述の離乳食記録の写真でも実行してみます。
※ 離乳食写真では Tesseract-OCR の動作モードを "11" に設定しました。
画像中に散発的にテキストが存在する場合に適したモードです。

無茶苦茶な結果となってしまいました。
OCRエンジンが実際に読み込んでいる、前処理後の画像を確認してみます。

前処理をすると最終的にバイナリ化(完全な白 or 完全な黒 にピクセルを分類する)されるが、画像を確認するとテキスト部分は背景に飲み込まれてしまっており、これでは当然OCRでは文字変換が難しい。そもそもどの部分がテキストで、どの部分が背景なのか人間にも区別も難しく、OCRエンジン側は画面中のあらゆる部分から文字抽出しようとして、先ほどののような無茶苦茶な結果になってしまったと考察します。
現状把握② - テキスト範囲を切り出し
では、テキストエリアをトリミングツールにて切り抜き、画像の中に1行の文字列がある状態にして、それらをOCR処理すれば正しくテキストが抽出されるのでしょうか? 背景と被りがある4つのテキストエリアの切り抜き画像に対してOCR処理をしてみます。


結果を見ると、全て正しくテキストに起こせています。前処理後の画像を確認すると、文字の輪郭に沿って文字部分のみ黒色に、背景のみが白色にバイナリ化されています。切り抜きをせずに全体を前処理したときは、画面全体の明度に対して単一のスレッショルドを設定して前処理したので、背景側に文字が取り込まれやすかったのですが、小さく切り抜いた事でテキスト画像単体に対して個別に二値化処理を施す事ができ、結果として文字抽出が可能な品質の前処理後画像(OCR用画像)となったと考察します。
現状把握③ - 既存検出モデルの精度
ここまでの現状把握にて、テキストエリアを自動で切り出す事が出来れば、画像中に散在する文字列をテキストデータに変換可能と分かりました。
そこで次に、テキストエリアを既存技術で自動切り抜きが出来るのか検証します。テキスト領域の検出モデルとして、 EAST (Efficient and Accurate Scene Text Detector) というものが公開されています。下記のスクリプトにて、課題の画像(離乳食の記録写真)を処理してみます。
import cv2
import numpy as np
import pandas as pd
from PIL import Image
import glob
import os
def detect_text(images_paths):
# モデルのパス
net = cv2.dnn.readNet('frozen_east_text_detection.pb')
for image_path in images_paths:
# 画像の読み込み
image = cv2.imread(image_path)
orig = image.copy()
(H, W) = image.shape[:2]
# EASTモデルの入力サイズに合わせて画像のサイズを変更
(newW, newH) = (320, 320)
rW = W / float(newW)
rH = H / float(newH)
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]
# ネットワークの入力を定義
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
(scores, geometry) = net.forward(["feature_fusion/Conv_7/Sigmoid", "feature_fusion/concat_3"])
# 後処理をここに記述...
(numRows, numCols) = scores.shape[2:4]
rects = [] # 検出されたテキスト領域の境界ボックスを格納
confidences = [] # 各境界ボックスの信頼度スコアを格納
for y in range(0, numRows):
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
for x in range(0, numCols):
if scoresData[x] < 0.5: # 信頼度スコアの閾値
continue
(offsetX, offsetY) = (x * 4.0, y * 4.0)
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
# 重複するボックスを抑制
boxes = cv2.dnn.NMSBoxes(rects, confidences, 0.5, 0.4)
# 検出されたテキスト領域を画像上に描画
for i in boxes.flatten(): # boxesを1次元配列に変換
(startX, startY, endX, endY) = rects[i]
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2)
max_width = 1000
if orig.shape[1] > max_width:
# 画像の幅を3000ピクセルに制限しつつ、アスペクト比を維持する
scale_ratio = max_width / orig.shape[1]
new_height = int(orig.shape[0] * scale_ratio)
orig = cv2.resize(orig, (max_width, new_height))
# 検出されたテキスト領域を表示
cv2.imshow("Text Detection", orig)
cv2.waitKey(0)
def extract_metadata(images_folder_path):
# ファイル名と撮影日時を格納するためのリストを初期化
file_names = []
datetimes = []
# 指定したフォルダ内の全ファイルを走査
for file in os.listdir(images_folder_path):
# ファイルがJPG画像であるかをチェック
if file.lower().endswith('.jpg'):
try:
# 画像ファイルを開く
with Image.open(os.path.join(images_folder_path, file)) as img:
# EXIF情報を取得
exif_data = img._getexif()
# EXIF情報が存在し、撮影日時が含まれているかをチェック
if exif_data is not None and 36867 in exif_data:
# ファイル名(ベースネーム)と撮影日時をリストに追加
file_names.append(os.path.basename(file))
datetimes.append(exif_data[36867])
except Exception as e:
print(f'Error reading file {file}: {e}')
# リストをPandas DataFrameに変換
df = pd.DataFrame({
'File Name': file_names,
'Datetime': datetimes
})
# DataFrameを表示(必要に応じて保存や他の操作を行う)
print(df)
# 画像パスを指定して関数を呼び出し
images_folder_path = "./images"
images_paths = glob.glob(f"{images_folder_path}/*")
extract_metadata(images_folder_path)
detect_text(images_paths)
結果を見ると、残念ながらほとんど正しく検出出来ていませんでした。やはり、文字の背景が単一色では無いことや、画像中の色々な位置にあることが、検出を難しくしているようです。
■ 現状把握の結論は以下です。
OCRエンジン(Tesseract)自体の精度は十分に高い。
テキストが画像中に複数行ありそれぞれの背景明度のレンジが広い場合、バイナリ化すると文字が潰れ、OCRによるテキスト抽出が失敗する。
テキスト範囲を個別に切り抜き前処理をすると、OCRが成功する。
既存モデルだけではテキスト範囲を自動的に正しく切り取る事は難しく、課題に合った新たなテキスト領域検出モデルの構築が必要。
目標設定
制作するアプリの要件として下記を定義します
■コンセプト
画像中の文字列をテキストデータとして出力できる、
シンプルかつ直感的で誰にでも優しく親切なwebアプリ
■ターゲット
一般のwebサービスとして公開し、URLのみでアクセス可能であること
■機能
1. ユーザーがアップロードした画像ファイルを受け取る事が可能(複数可)
2. 画像の中のテキストのエリアを検出する事が可能
3. 検出したテキストエリアにバウンディングボックス描写が可能
4. 検出したテキストエリアを単一画像としてクロッピングする事が可能
5. クロッピングした画像に対して個別に前処理する事が可能
6. 個別の前処理画像に対してOCRエンジンによるテキスト抽出が可能
7. 途中結果(検出範囲を示した全体画像、クロッピング画像、前処理後画像)
をユーザーに対して出力可能
8. 最終結果(抽出したテキストデータ)を、ユーザーに対して出力可能
■セキュリティ(※重要)
・個人情報の流出がないこと:
ユーザーによってアップロードされた画像や結果は、そのユーザーに
しか表示・ダウンロードが不可能な仕様とすること
→Session や Query の仕組みを活用し、フロントエンドから POST/GET
した場合に、そのユーザー特有のkey(暗号)が一致する場合のみ情報
開示をする仕組みにする
■ユーザビリティ
・ シンプルな操作のみでユーザーが目的を達成可能なこと
・ ユーザーに許された操作の範囲ではユーザー側にエラーを吐かないこと
→ バックエンド : 適切なエラーハンドリングコードを設置する
フロントエンド: ユーザーにエラー操作をさせないUI設計
・ 親切なナビゲーション
・ 使いたくなるようなデザイン
■その他
・ログの記録・保存が出来ること(3年間)
・一時ファイルを定期的に自動削除するスケジュールタスクを組み込むこと
開発環境
私の開発環境は以下です
コーディング/アノテーション作業用
・デバイス: HP SPECTRE X360 laptop
・OS: Windows11 (23H2)
・プロセッサ: Intel Core(TM) i7-1360P 2.2 GHz
・RAM: 32.0 GB
・GPU: Intel(R) Arc(TM) A370M Graphics
・エディタ: VSCode
・インタプリタ: Python v3.11.8
・アノテーションツール: CVAT v15.0.0
→DockerDesktopにてCVATコンテナをデプロイ(後述)
実行用PC(ホスト)
・デバイス: デスクトップ型自作PC
・OS: Windows10 (22H2)
・プロセッサ: AMD Ryzen7 3700X 3.6 GHz
・RAM: 32.0 GB
・GPU: NVIDIA GeForce RTX 3050
・GPUドライバ: 551.86
・CUDA: 12.1.1_531.14_windows
・cuDNN: windows-x86_64-8.9.6.50_cuda12
・インタプリタ: Python v3.11.8
実行用仮想マシン
上記実行用PCをホストとした仮想マシン
・仮想化環境: WSL2
・ディストリビューション: Ubuntu 22.04
・インタプリタ: Python v3.11.8
その他
開発で使用した主なツールやライブラリ
・Github - コーディングのバージョン管理や複数デバイスとの連携に使用
・Docker - CVATコンテナ利用およびアプリのDockerイメージ作成時に使用
・ultralytics - モデルの深層学習のために使用
・PyTorch - CUDAによる高速処理を可能にするためにGPU版を使用
・Tesseract-OCR - 文字抽出のため。アプリではLinux版を使用
・roboflow universe - アノテーション済データセットの利用のため
・TensorBoard - 転移学習のメトリクスの監視・分析のため
コーディングやアノテーションといった作業には、場所を選ばないラップトップ型PCを使用し、深層学習やアプリのテストランなどの重たい処理を繰り返す作業では、実行用として自作デスクトップPC内の仮想環境(WSL2)内のUbuntuにPython環境を構築し利用しました。
なお、コーディング用ラップトップとホストPCは常時RDP(リモートデスクトップ接続)しており、Ubuntu側のPython開発ホームディレクトリはVSCodeの拡張機能 "WSL" によりホスト側にマウントしてあるので、実際に触っているのは常にラップトップPCのみです。ラップトップ1台で外出先の空き時間や職場の休憩時間を活用して気軽に開発を進められる環境を構築しました。
物体検出モデルの構築
YOLOv9 について
テキストエリアを検出させる方法として 物体検出 (object detection) 技術を利用する事としました。ゼロベースから深層学習をしてモデルを構築することも考えましたが、世の中には公開された優秀なモデルがあります。そこで今回は、公開済の物体検出モデルに対して自分で用意した教師データセットを用いた転移学習をして、テキストエリアを物体検出するモデルを構築したいと思います。
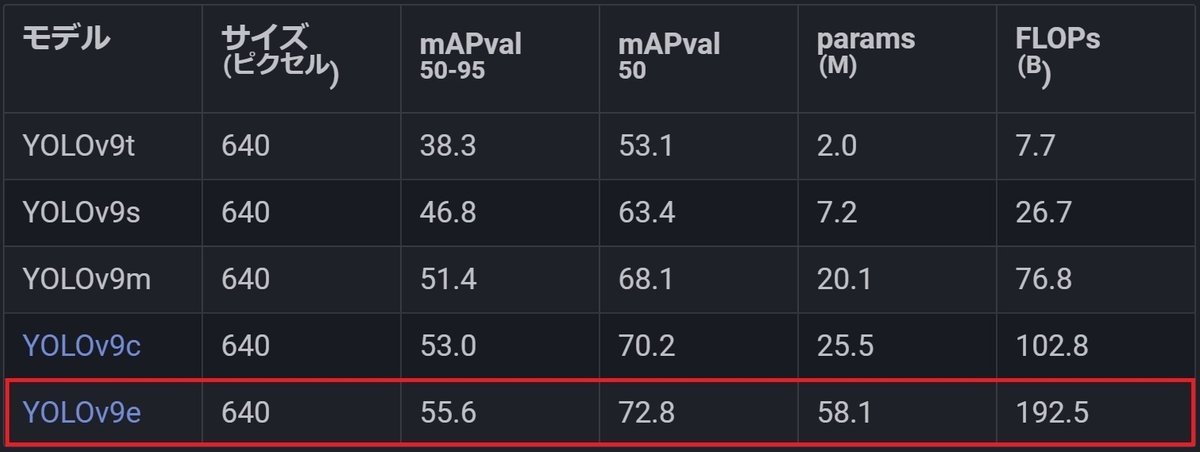
物体検出モデルにも色々ありますが、現時点(2024年3月)での最新の技術に触れたく、2024年2月に ultralytics から公開された YOLOv9 をベースモデルとして選定したいと思います。YOLO(You Only Look Once)はリアルタイム物体検出システムで、画像内の物体を検出し、その位置を特定することができます。v9には目的に沿ったいくつかのモデルがありますが、今回はリアルタイム推論はしないので推論速度は問題となりませんので、検出精度を優先し容量の最も大きい v9e を選択します。
更なる YOLOv9 の詳細については上記リンク先をご参照ください。
まずは、YOLOv9e を試してみます。
from ultralytics import YOLO
# Load a model
model = YOLO("yolov9e.pt") # load a pretrained model
# Use the model try
results = model("https://ultralytics.com/images/bus.jpg",save=True) # predict on an image上記コードにて、モデルとサンプル画像のロードと、推論まで出来ます。
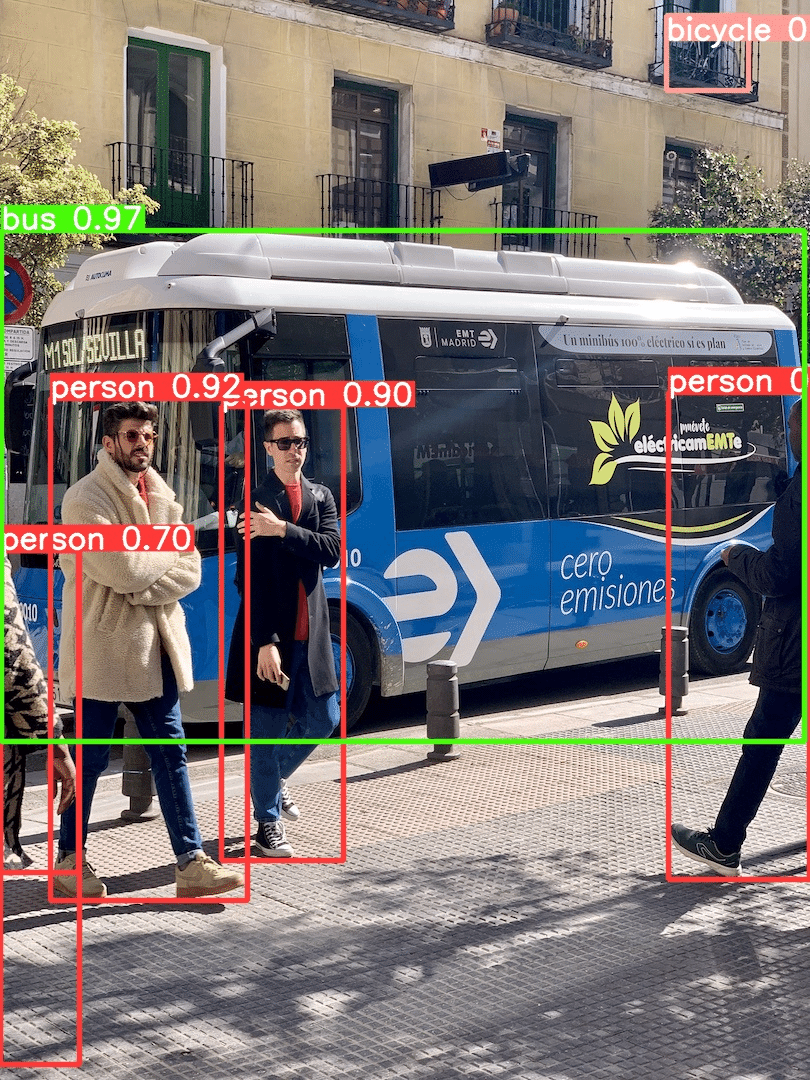
画像中の物体を正しくクラス分類し検出しています。右上のベランダの自転車まで正しく検出しているのは凄いですね。
YOLOの物体検出モデルでは、デフォルトでは "テキスト領域" というクラスは設定されていません。そこで、この優秀なモデルをベースモデルとして、"テキスト領域" というクラスを転移学習させ、本開発の目的である "テキスト領域の検出" に特化したモデルを構築していきます。
今更ですが、YOLOv9e は CNN (畳み込みニューラルネットワーク) 構造を有するディープラーンドモデルです。そのネットワークアーキテクチャはyamlファイルで公開されているので、構造を確認してみます。
# YOLOv9
# parameters
nc: 80 # number of classes
# gelan backbone
backbone:
- [-1, 1, Silence, []]
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 2]] # 3
- [-1, 1, ADown, [256]] # 4-P3/8
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 2]] # 5
- [-1, 1, ADown, [512]] # 6-P4/16
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 7
- [-1, 1, ADown, [1024]] # 8-P5/32
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 9
- [1, 1, CBLinear, [[64]]] # 10
- [3, 1, CBLinear, [[64, 128]]] # 11
- [5, 1, CBLinear, [[64, 128, 256]]] # 12
- [7, 1, CBLinear, [[64, 128, 256, 512]]] # 13
- [9, 1, CBLinear, [[64, 128, 256, 512, 1024]]] # 14
- [0, 1, Conv, [64, 3, 2]] # 15-P1/2
- [[10, 11, 12, 13, 14, -1], 1, CBFuse, [[0, 0, 0, 0, 0]]] # 16
- [-1, 1, Conv, [128, 3, 2]] # 17-P2/4
- [[11, 12, 13, 14, -1], 1, CBFuse, [[1, 1, 1, 1]]] # 18
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 2]] # 19
- [-1, 1, ADown, [256]] # 20-P3/8
- [[12, 13, 14, -1], 1, CBFuse, [[2, 2, 2]]] # 21
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 2]] # 22
- [-1, 1, ADown, [512]] # 23-P4/16
- [[13, 14, -1], 1, CBFuse, [[3, 3]]] # 24
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 25
- [-1, 1, ADown, [1024]] # 26-P5/32
- [[14, -1], 1, CBFuse, [[4]]] # 27
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 28
- [-1, 1, SPPELAN, [512, 256]] # 29
# gelan head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 25], 1, Concat, [1]] # cat backbone P4
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 2]] # 32
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 22], 1, Concat, [1]] # cat backbone P3
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 2]] # 35 (P3/8-small)
- [-1, 1, ADown, [256]]
- [[-1, 32], 1, Concat, [1]] # cat head P4
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 2]] # 38 (P4/16-medium)
- [-1, 1, ADown, [512]]
- [[-1, 29], 1, Concat, [1]] # cat head P5
- [-1, 1, RepNCSPELAN4, [512, 1024, 512, 2]] # 41 (P5/32-large)
# detect
- [[35, 38, 41], 1, Detect, [nc]] # Detect(P3, P4, P5)この設定ファイルでは、モデルの構造、使用する層、およびそのパラメータが定義されています。
nc: モデルが検出できるクラス(物体の種類)の数を指定します。この例では80クラスとされています。
backbone: モデルのバックボーンは、入力された画像から特徴を抽出する役割を担います。このコードでは、Conv(畳み込み層)、ADown(Yolov9独自のダウンサンプリング層)、RepNCSPELAN4(Yolov9独自のカスタム層)、CBLinear、CBFuse(特徴融合を行う層)など、様々な種類の層が使用されています。
head: モデルのヘッドは、バックボーンからの特徴を利用して最終的な物体検出を行います。この部分では、アップサンプリング(nn.Upsample)、特徴の連結(Concat)、再びRepNCSPELAN4層が使われています。最終的には、異なるスケールで検出を行うDetect層が配置されています。
その他: 入力層への参照(例:-1は直前の層を意味する)、この層を繰り返す回数、層の種類、そして層のパラメータ(フィルタの数、カーネルサイズ、ストライド等)が指定されています。
この設定ファイルはモデルのアーキテクチャを定義しており、各層がどのように接続され、画像から特徴を抽出し物体を検出するかを指定しています。
教師データについて
前述の YOLOv9e をベースモデルとして、テキスト領域検出に特化させるための転移学習を実行していきます。転移学習をするためには、教師データが必要となります。本開発における教師データとはテキスト領域を含む画像に対してテキストエリアを教師したデータセット、したがって画像ファイルとアノテーションファイルのペアとなります。
クラス数1クラスとします。2クラス以上の分類問題として、例えばアルファベットと漢字・ひらがな・カタカナを区別させる事も考えましたが、まずは文字領域を正確に検出可能にすることを第1STEPとします。
教師データの枚数は、元画像の枚数としては1000枚、オーグメンテーション(後述)後の枚数として8000枚を目標としました。ゼロベースでCNNによるモデル構築をする場合、物体検出モデルでは恐らく数万~数十万の教師データが必要かと思いますが、今回は YOLOv9e をベースに転移学習するので、それよりはずっと少ない枚数でモデル構築が可能と踏んでいます。つまり、v9eに既に備わっている "物体のエッジを捉える能力" 自体は転用し、そこへテキスト領域の特徴を転移学習させる事で、モデル構築を目指します。
CVATによるアノテーション
画像ファイルへのアノテーションをする手法として、今回は CVAT を使用します。CVAT(Computer VIsion Annotation Tool) は Intelが作成しているOSS(オープンソースソフトウェア)の画像・動画向けのアノテーションツールで、コンピュータービジョンで用いられるタスク(領域検出、画像分類、セマンティックセグメンテーション)で使用することが想定されたツールです。
以下はCVATのデプロイ手順です。Ubuntuのターミナルで実行します。
※ Windowsに WSL2 および Ubuntuがインストール済の想定です。
Dockerのインストール
sudo apt-get update
sudo apt-get install -y docker.io2.Docker Composeのインストール
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose3.CVATのGitHubリポジトリをクローン
git clone https://github.com/openvinotoolkit/cvat.git
cd cvat4.Docker Composeを使ってCVATを起動
sudo docker-compose up -d 上記はUbuntuのホームディレクトリに cvat というフォルダを作成し、そこへ gitcloneする方法を取っています。フォルダへ展開後、Docker Compose を使用して関連する複数のコンテナを同時に起動する事が出来ます。起動が完了すると、ブラウザから http://localhost:8080 にアクセス可能になり、CVATが使用可能になります。
初回はユーザー登録が必要なので、登録し(手順割愛)、まずはプロジェクトを作成します。プロジェクト設定の中にLabel設定があり、今回は1クラス分類をするのでラベルを1つだけ作成し、分かりやすい色としてマゼンタを設定、クラス名を "0" としました。次に、タスクを作成します。タスクを新規作成し、親プロジェクト選択欄には先ほど作成したプロジェクトを選択します。最後に、転移学習に使用したい手持ちの画像をアップロードします。
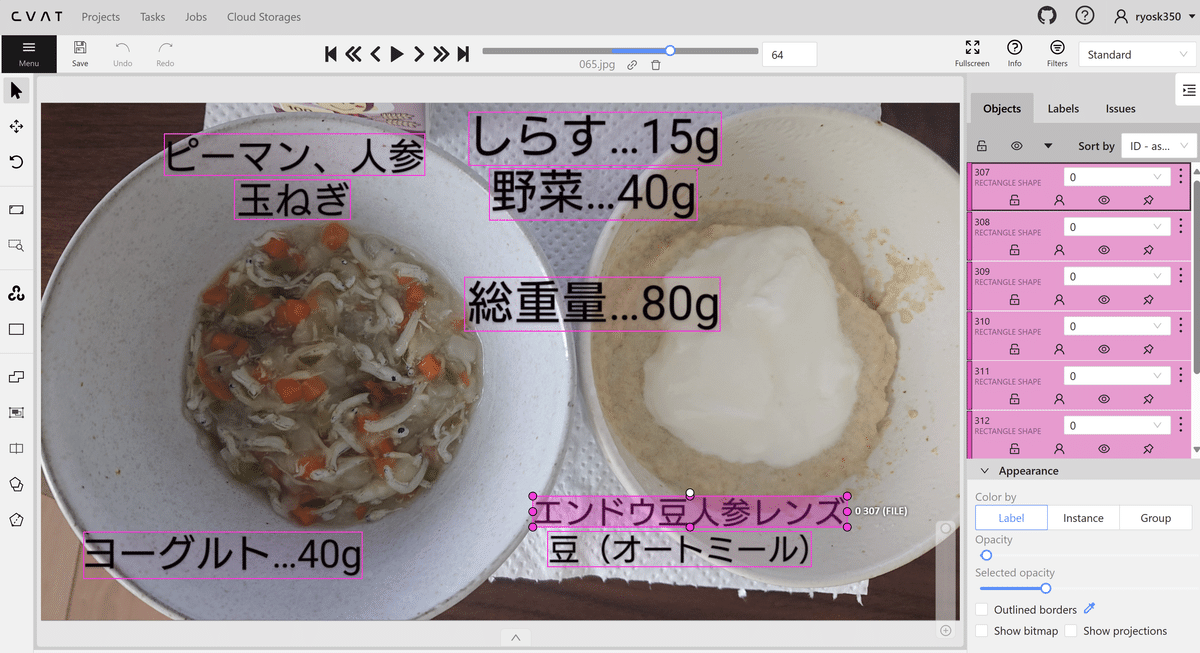
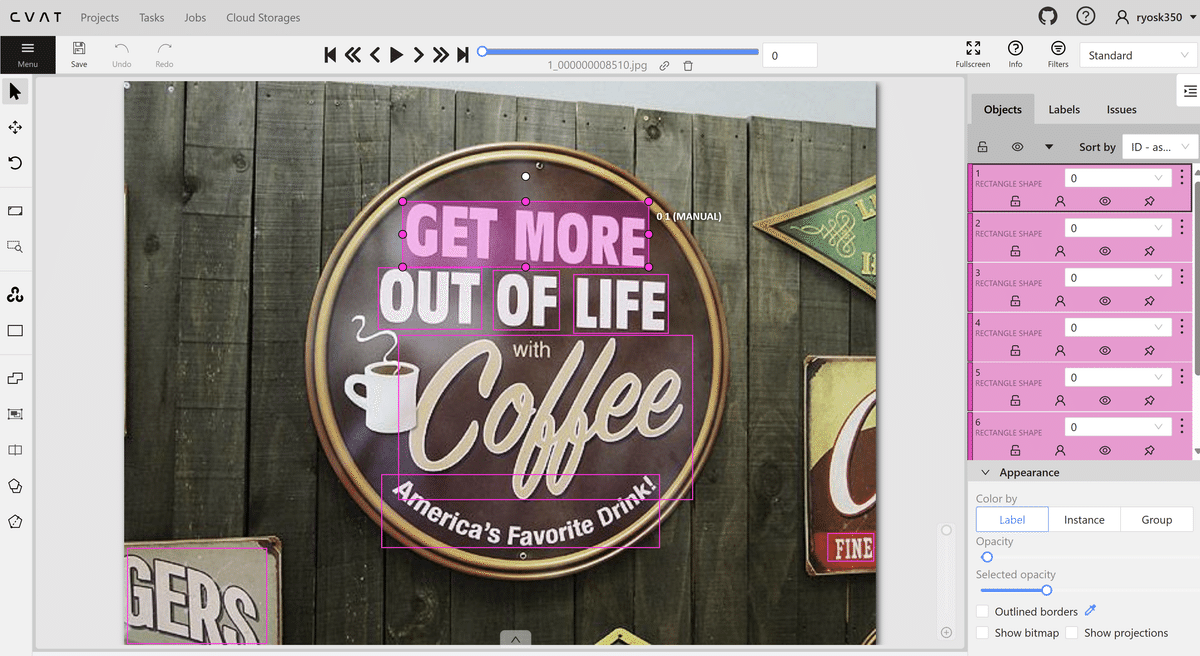
上図はアノテーション作業の風景です。1枚1枚、写真を見ながら、テキストエリアに手動でバウンディングボックスを付けていきます。今回のテーマ選定のきっかけとなった、離乳食の写真に加えて、モデルの汎用性を高めるためにそれ以外の様々なシチュエーションのテキスト入り写真を加え、アノテーション作業をしていきます。アノテーション作業は手動なので地道な作業となりますが、教師データの品質は最終的に仕上がるモデルの品質を左右する重要なファクターです。今回は、手持ち写真から250枚程を教師データとして作成しました。アノテーション作業が完了したら、データセットとしてダウンロードします。
アノテーションデータのフォーマットには様々な形式がありますが、今回は "YOLO形式" を選択します。YOLO形式アノテーションファイルは、画像データと同じ拡張子前のファイル名を持つテキストファイルで、画像中のバウンディングボックスのクラスと位置が記述されています。したがって、画像ファイルと同数とYOLOアノテーションファイルが作成されます。
(例)
画像ファイル : sample1.jpg、 sample2.png、 sample3.bmp
アノテーションファイル: sample1.txt、 sample2.txt、 sample3.txt
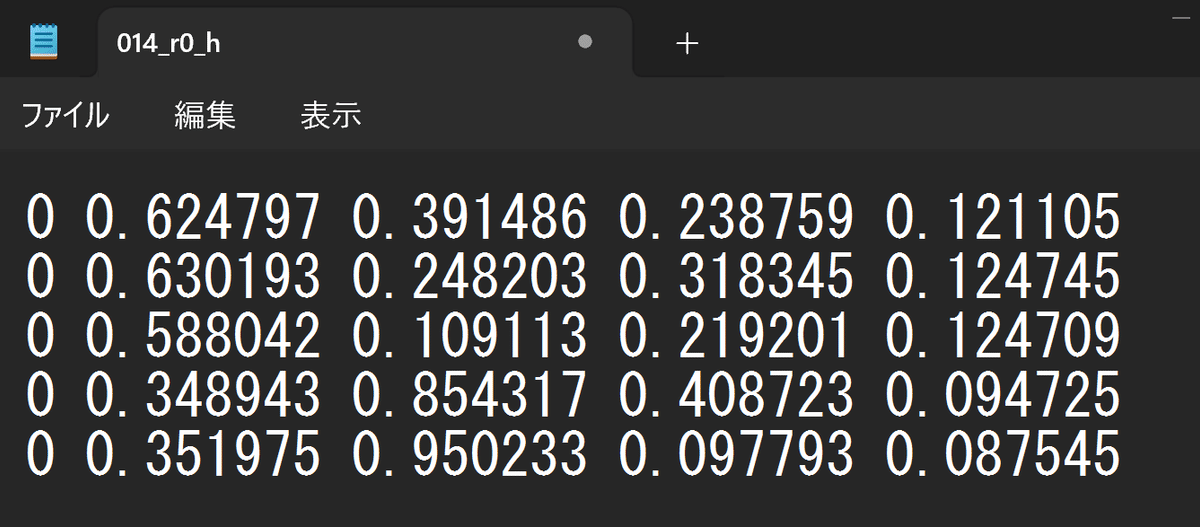
上記はYOLO形式アノテーションファイルの一例です。
1行に1つのバウンディングボックスの情報が下記のように記述されます。
<object-class> <x_center> <y_center> <width> <height>
左から、
・クラスID : 0から始まるインデックスで表され、アノテーション対象の物体リストに従います(例: 0が犬、1が猫)。今回は1クラスなので0のみです。
・バウンディングボックスの中心のx座標とy座標:これらの値は画像の幅と高さに対する相対的な割合で表され、0から1の間の値を取ります。
・バウンディングボックスの幅と高さ:画像の幅と高さに対する割合で表され、0から1の間の値です。
YOLO形式のアノテーションデータは、画像の割合によって座標が決定するため、サイズに依存しません。画像ファイルを前処理などでリサイズした場合でも、アノテーションデータは無加工のまま利用できるなどのメリットがあります。
公開済データセットの利用
モデルの汎用性を高めるために、公開済のアノテーション済データセットを利用する事とします。今回は、roboflow universe より、テキスト領域が含まれる画像ファイルに対して、1クラスアノテーションが完了しているデータセットを検索します。
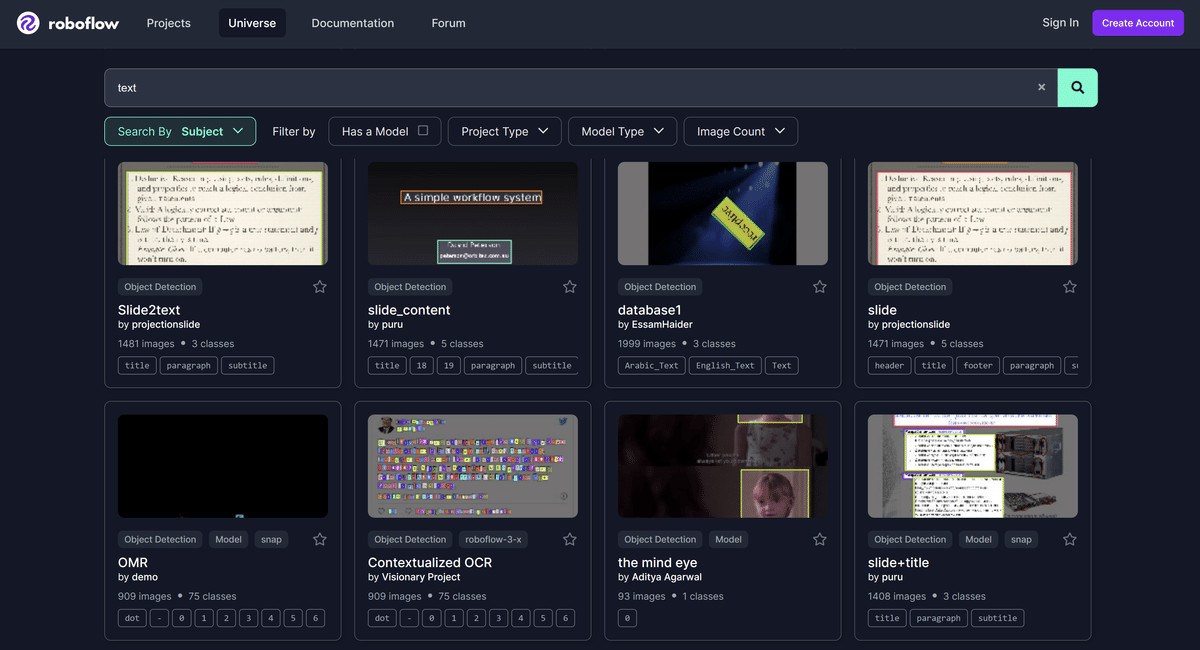
"text" でキーワード検索すると、様々なデータセットがヒットします。この中から、今回の用途に沿ったデータセットを選択します。今回は、文字列を1行まとめて物体として検出したいので、1行ごとにバウンディングボックスで囲まれているデータセットを選択します。1文字ずつ個別に囲まれてたり、複数行がまとめて囲まれているデータセットは、今回の用途にそぐわないため、除外します。
利用するデータセットが決定したら、画像とアノテーションデータをダウンロードします。アノテーションデータは形式を選べるので、YOLO形式を選択します。今回は、いくつかのプロジェクトから、合計750枚ほどのデータセットをダウンロードしました。

オーグメンテーション
ここまでに、自前のデータセット 250枚、roboflow universe からダウンロードしたデータセット 750枚、合計 1000枚の教師データが揃っています。
更にモデルの汎用性を高めるために、教師データのオーグメンテーションを実行します。オーグメンテーションとは、既存の画像データセットを様々な方法で変形させてデータ量を人工的に増やし、データセット内のバリエーションを増やしてトレーニング環境をより現実的にする技術です。変形の手法としては、回転、反転、ズーム、色調変更など、さまざまな処理を施すことが含まれます。これにより、モデルの汎化能力を高め、過学習を防ぐことができます。
from PIL import Image
import os
def resize_image(image_path, output_path, size):
with Image.open(image_path) as img:
img_resized = img.resize(size)
img_resized.save(output_path)
# オリジナル画像のパス
source_folder_images = './images'
# 処理後の出力フォルダのパス
output_folder_resized_images = './resized/images'
# リサイズ設定
size = (320, 320)
# 画像のリサイズの実行
for image_file_name in os.listdir(source_folder_images):
if image_file_name.endswith('.jpg'):
image_path = os.path.join(source_folder_images, image_file_name)
# 画像をリサイズして保存
resized_image_path = os.path.join(output_folder_resized_images, image_file_name)
resize_image(image_path, resized_image_path, size)まずオーグメンテーション処理をする前に、上記スクリプトにて画像サイズを 320×320 pixel に統一してリサイズしています。理由は全画像は転移学習の実行時には指定サイズに統一されている必要があり、リサイズはオーグメンテーションの前に済ませる方が処理工数の観点で効率的だからです。
from PIL import Image
import os
def rotate_image(image_path, degrees, output_path):
with Image.open(image_path) as img:
rotated_img = img.rotate(degrees, expand=True)
rotated_img.save(output_path)
def flip_image(image_path, method, output_path):
with Image.open(image_path) as img:
if method == 'horizontal':
flipped_img = ImageOps.mirror(img)
elif method == 'vertical':
flipped_img = ImageOps.flip(img)
flipped_img.save(output_path)
def adjust_annotation_for_rotation(annotation_path, degrees, output_path):
with open(annotation_path, 'r') as file:
lines = file.readlines()
adjusted_lines = []
for line in lines:
parts = line.strip().split()
class_id, x_center, y_center, width, height = map(float, parts)
if degrees == 0:
# 回転なしの場合は、変更せずにそのまま使用
new_x_center, new_y_center = x_center, y_center
new_width, new_height = width, height
elif degrees == 90:
new_x_center, new_y_center = y_center, 1 - x_center
new_width, new_height = height, width
elif degrees == 180:
new_x_center, new_y_center = 1 - x_center, 1 - y_center
new_width, new_height = width, height
elif degrees == 270:
new_x_center, new_y_center = 1 - y_center, x_center
new_width, new_height = height, width
else:
raise ValueError("Unsupported rotation angle")
adjusted_lines.append(f"{int(class_id)} {new_x_center} {new_y_center} {new_width} {new_height}\n")
with open(output_path, 'w') as file:
file.writelines(adjusted_lines)
def adjust_annotation_for_horizontal_flip(annotation_path, output_path):
with open(annotation_path, 'r') as file:
lines = file.readlines()
adjusted_lines = []
for line in lines:
parts = line.strip().split()
class_id, x_center, y_center, width, height = map(float, parts)
new_x_center = 1 - x_center # 水平反転によるX座標の調整
adjusted_lines.append(f"{int(class_id)} {new_x_center} {y_center} {width} {height}\n")
with open(output_path, 'w') as file:
file.writelines(adjusted_lines)
def adjust_annotation_for_vertical_flip(annotation_path, output_path):
with open(annotation_path, 'r') as file:
lines = file.readlines()
adjusted_lines = []
for line in lines:
parts = line.strip().split()
class_id, x_center, y_center, width, height = map(float, parts)
new_y_center = 1 - y_center # 上下反転によるY座標の調整
adjusted_lines.append(f"{int(class_id)} {x_center} {new_y_center} {width} {height}\n")
with open(output_path, 'w') as file:
file.writelines(adjusted_lines)
# オーグメンテーションする画像とアノテーションファイルのフォルダパス
image_folder = './resized/images'
annotation_folder = './labels'
# 出力フォルダパス
output_folder_images = './augmented/images'
output_folder_annotations = './augmented/labels'
# オーグメンテーションの実行
for file_name in os.listdir(image_folder):
if file_name.endswith('.jpg'):
base_name, _ = os.path.splitext(file_name)
image_path = os.path.join(image_folder, file_name)
annotation_path = os.path.join(annotation_folder, base_name + '.txt')
# 90度単位の回転と左右反転の組み合わせ
for degrees in [0, 90, 180, 270]:
for flip_method in [None, 'horizontal']: # 上下反転を除外
# 回転と反転の条件に応じた出力ファイル名を生成
suffix = f"_r{degrees}" + (f"_{flip_method[0]}" if flip_method else "")
output_image_path = os.path.join(output_folder_images, f"{base_name}{suffix}.jpg")
output_annotation_path = os.path.join(output_folder_annotations, f"{base_name}{suffix}.txt")
# 画像の回転
rotate_image(image_path, degrees, output_image_path)
# アノテーションデータの回転調整
adjust_annotation_for_rotation(annotation_path, degrees, output_annotation_path)
# 必要に応じて画像を反転
if flip_method:
flip_image(output_image_path, flip_method, output_image_path)
# アノテーションデータの反転調整
if flip_method == 'horizontal':
adjust_annotation_for_horizontal_flip(output_annotation_path, output_annotation_path)
# 上下反転すると被りが発生するため、今回は実行しない 上記スクリプトでは、リサイズ後のデータセットをオーグメンテーションし、画像の回転(90°単位)と左右反転を組み合わせ、オリジナル位相に加えて7位相の画像とそれに対応したアノテーションデータを生成しています。
※左右反転の他に上下反転の関数も定義していますが、今回は不使用です。角度回転を組み合わせる場合、反転は上下か左右のどちらか1回すれば、全位相をカバー可能なためです。
他にもオーグメンテーション手法としては、ズームインや、アスペクト比の変更、色調・明度やコントラスト調整などの手法がありますが、今回は学習前の処理としては画像の位相の変換のみに留め、残りのオーグメンテーション処理は後述の転移学習時に、ライブラリの機能を利用していくつか実装する事とします。

反転と回転をしているが、バウンディングボックスは正しい位置を示している
学習のための段取り
いよいよ、本開発の最も中核となる部分です。用意した教師データ約8000枚を、物体検出ベースモデル YOLOv9e へ転移学習していきます。
まずPython実行環境のルートディレクトリに "datasets" フォルダを作成し、その中に下図のようなフォルダ構成でデータを配置します。
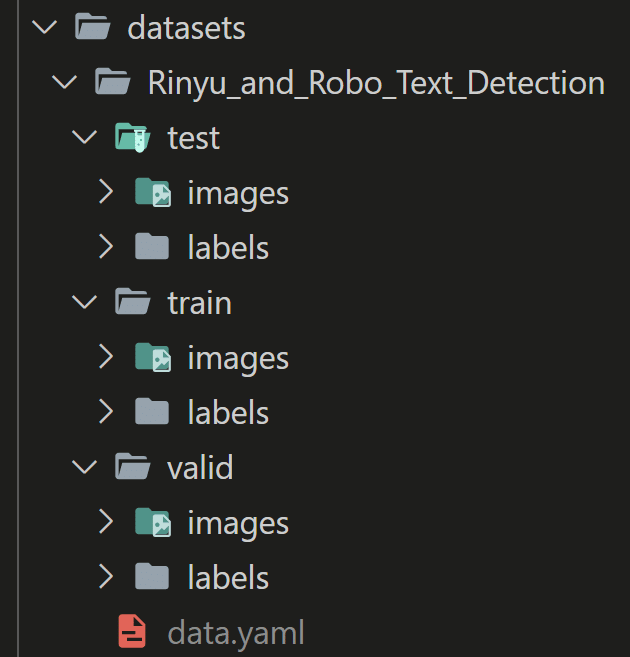
親フォルダ名 "Rinyu_and_Robo_Text_Detection" は、データセット名です。(離乳食の画像とroboflowからダウンロードした画像のデータセット)
その中に、"test", "train", "valid" フォルダ、各フォルダ内に "images", "labels"
フォルダを更に配置します。"train" は学習データ、"valid" は検証データです。学習データや検証データの説明は、ここでは割愛します。"images" には画像ファイルを、"labels" には対応するアノテーションファイルを格納します。8000枚のアノテーションデータセットは、学習 : 検証 = 8 : 2 になるように手動で振り分けました。このとき検証データがなるべくテキストの傾向や特徴が偏ったものにならないように気を付けました。検証データのバリエーションは、モデルの過学習を防ぎ汎用性を高めるために重要です。
"test" データは、モデル作成後に精度を検証するためのデータセットでモデルの訓練そのものには使用されません。よってテストデータは精度検証時に別で用意するため、今回は空にしました。
最後に、data.yaml ファイルについて。データセットを格納したら、yamlファイルにデータセットの構造を記述します。data.yaml は上図のようにデータセットフォルダのルートに配置し、各データフォルダの位置を相対的に指定します。
train : "train/images"
val : "valid/images"
test : "test/images"
nc: 1
names: ['Text']今回の場合、 data.yaml の中身は上記のように記述します。各データの画像ファイルのフォルダの場所を指定すれば、自動的にその階層の別フォルダ(=labels)を検索して対応するアノテーションファイル(=拡張子前のファイル名が一致するもの)を見つけ出します。
学習時はこの data.yaml ファイル一つを指定するだけで、全てのデータセットを正しく認識して学習を進行させる事が出来ます。
学習用スクリプトの記述
ultralytics が公開している 外部ライブラリ "YOLO" 使ってYOLOv9eをベースモデルとた転移学習を開始します。コードは非常にシンプルです。
from ultralytics import YOLO
# モデルを学習するメイン関数を定義
def main():
# ベースとするモデル
model = YOLO("yolov9e.pt")
results = model.train(
# データの読み出しと保存に関する設定
data = './datasets/Rinyu_and_Robo_Text_Detection/data.yaml',
project = "project",
name = "Rinyu_and_Robo_txt_detect_ep100",
exist_ok = False,
# 学習に関する主な設定
optimizer = 'auto',
epochs = 100,
batch = -1,
imgsz = 320,
cache = True,
device = 0,
lr0 = 0.01, # 初期学習率 ※重要
lrf = 0.01, # 初期学習率に対する最終学習率の割合
# オーグメンテーションに関する主な設定
hsv_h = 0.015,
hsv_s = 0.7,
hsv_v = 0.4,
degrees = 0.0,
translate = 0.1,
scale = 0.5,
flipud = 0.0,
fliplr = 0.0, # デフォルトは0.5
mixup = 0.1 # デフォルトは0.0
)
# Windows環境でのmultiprocessingへの対策をしてメイン関数を実行
if __name__ == '__main__':
from multiprocessing import freeze_support
freeze_support()
main()上記コードですが、 YOLO の trainメソッドにいくつかの引数を渡して転移学習を実行するものです。
■引数の説明
◆データの読み出し・保存に関わるもの
data: 前述の data.yaml のパスを指定します。
project: ルートディレクトリに指定名のフォルダを作成します。
name: 上記フォルダに指定名のフォルダを作成し結果を出力します。
◆学習に関するパラメータ
optimizer: auto にすれば最適なオプティマイザーが自動選択されます。
epochs: エポック数の指定。今回は300に指定しました。
batch: -1 にする事で、マシンSPECに合ったバッチサイズが選択されます。
imgsz: 画像の一辺のサイズ。前処理で320×320 pxにしたので指定します。
cache: 学習時のキャッシュをデバイスのRAMからもあてがいます。
device: 0 を指定すると、1番目のGPUを使用します。
lr0: 初期学習率。学習率とはモデルの重みをエポック毎にどれくらい変動
させるかのパラメータで、モデル品質を左右する重要な設定値。
lrf: 初期学習率に対する最終学習率の割合。予定エポック数に応じて、
初期学習率から最終学習率へ線形減衰するように変化させます。
◆教師データのオーグメンテーションに関する設定
hsv_h:色相のバラつきを導入しモデルの一般化を促進します。
hsv_s:彩度を変化させ色の濃淡に関するロバスト性を向上させます。
hsv_v:明度を変化させ多様な照明条件下でのロバスト性を向上させます。
degrees:指定した角度単位で一回転するまで画像を回転させます。
※今回は前処理で既に実行済なので、ゼロを設定します。
translate:画像を水平移動させ、部分的に見える物体の検出性を高めます。
scale:画像をスケーリングし、撮像距離へのロバスト性を高めます。
flipud:画像を上下反転させデータセットの幾何的多様性を高めます。
fliplr: 画像を左右 〃
※今回 flip は前処理で実行済なので、ゼロを設定します。
mixup:2つの画像とそのラベルをブレンドし、合成画像を作成し、
モデルの汎用性を高めます。
他にも引数はたくさんあり、様々なチューニングが可能です。
詳細は trainモードの公式ガイド を参照ください。
実行部ですが、単に "model.train" を呼び出すとwindows環境ではマルチプロセス関連のエラーになるので、if __name__ == '__main__': ブロック内で、freeze_support を import および 実行することで、エラー回避します。
スクリプトを実行すると転移学習が始まります。各パラメータのログは、project フォルダにリアルタイムで保存されていきます。このフォルダを TensorBoard で監視することで、進捗と各メトリクスを確認できます。
学習の実行
私の環境では 約2分 / epoch の速度で学習が進行し、全体では約5.5時間程の所要時間で学習が完了しました。ちなみに CUDAを実装していないコーディング用PCで同じ学習を開始したところ、約19分 / epoch となり、完了までに丸2日かかる速度でした。GPUの力は偉大だと感じました。
まずは、進行中300エポックに渡り、lr (learning rate:学習率) を監視しました。初期値に 0.01 を設定し 最終値はその 1/10 になるように設定したので、狙い通りに学習率が低下しているか確認します。ここに異常が見られる場合、何らかの原因で学習が正常に進行しなかった事を示します。
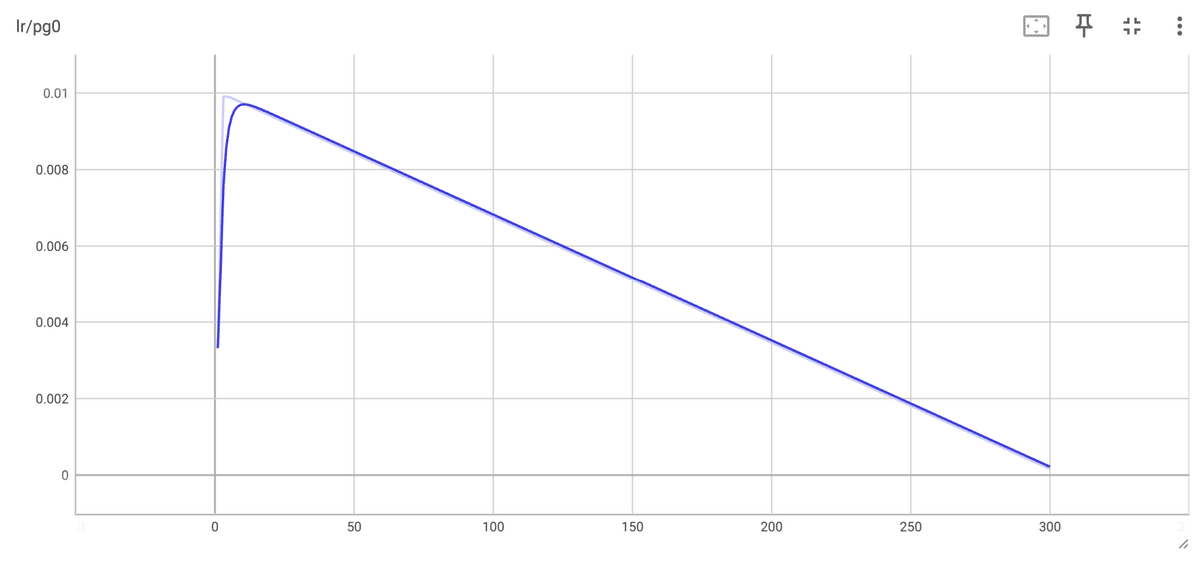
【 横軸 : epochs, 縦軸 : lr 】
lr 推移を見ると、正常な推移をした事が確認できました。最初の3~5エポックで学習率が急激に上昇していますが、これは "ウォームアップ付き線形ディケイ" という YOLO の学習スケジュールに沿っています。ウォームアップ後、設定の 0.01 に到達しそこから線形的にに最終学習率である 0.001 まで降下しています。
もし仮にこの直線が乱れたり、初期値や最終到達値が設定と違う場合、その学習は失敗したと判断すべきで、原因特定をしなければなりません。
次に、loss (損失) を確認します。深層学習における「loss」とは、モデルの予測が実際のデータとどれだけ異なるかを示す指標です。モデルの目的は、このlossを最小限に抑えることによって、実際のデータをより正確に予測することです。lossは訓練中にモデルの性能を評価し、最適化するための基準として機能します。訓練プロセスでは、バックプロパゲーションを通じて、このlossを減少させる方向にモデルのパラメータが更新されます。
lossにはいくつかの種類がありますが、今回は "box_loss" に着目します。バウンディングボックスの 位置・サイズ が実際値と予測値でどれだけ乖離しているかの指標です。具体的な数式は未確認ですが、YOLOの場合、boxの中心位置と高さ/横幅それぞれの、予測値と実際値との差の L1 or L2 損失を、独自の割合でブレンドした値と予想しています。
lossには train(学習) loss と、validation(検証) loss があります。train lossは、訓練に使用したデータを予測した場合のloss、validation loss は検証用の未学習データ(モデルの学習には使用していないデータセット) を予測した場合のlossです。一般に train loss は validation loss よりも小さい(=高精度)ですが、その差があまりに大きい場合、過学習(over_fitting)傾向となり、学習データに異常に適合し、未学習データの予測精度が悪い状態になります。
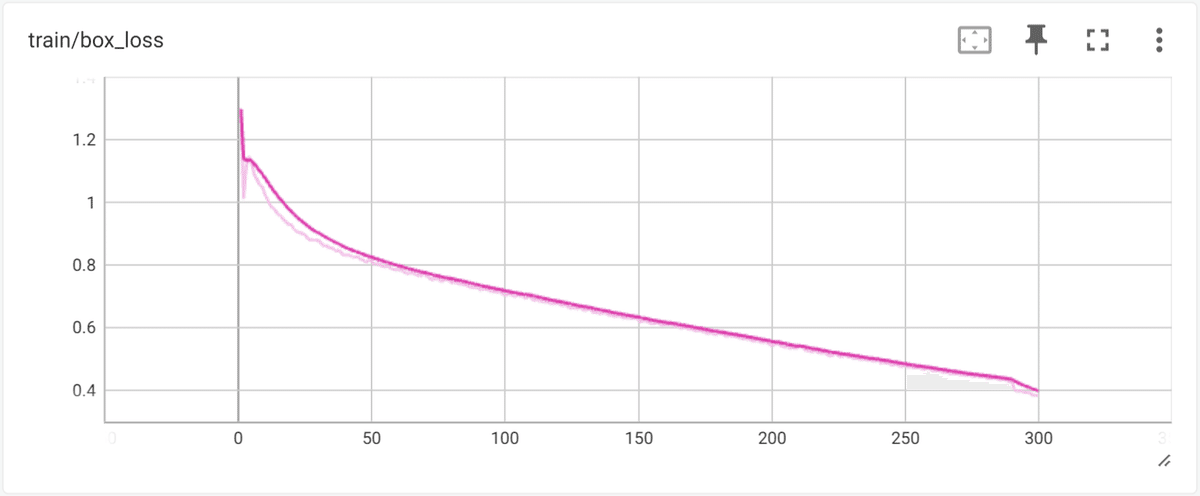
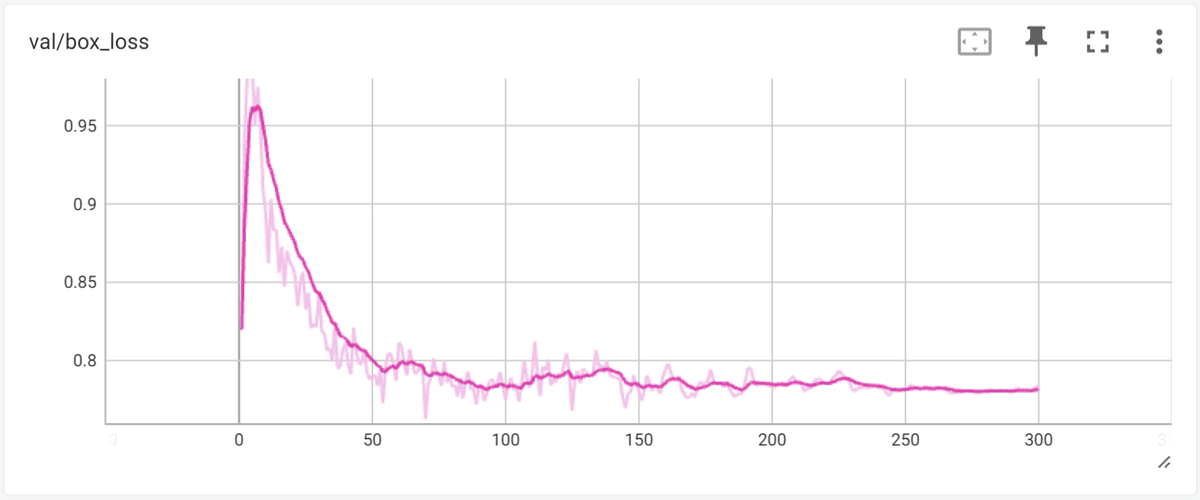
結果を見ると、train loss, validation loss ともに、エポックの進行によって順調に下がっており、正常な状態です。ただし、最終到達点では、train lossが 約0.4p なのに対して、validation loss は 約0.77p と2倍近い loss の開きがあり、過学習を起こしている可能性があります。
そこで次に、モデルのメトリクスの推移を確認します。
メトリクス(metrics)とは、データ分析分野では "モデルの精度指標" の意味合いで捉えてOKです。メトリクスにも色々な種類がありますが、今回は mAP50 という指標に着目し判断しました。
mAP50 とは、mean Average Precision at 50% Intersection Over Union で、物体検出モデルの性能を評価するための一般的な指標です。
mAP (mean Average Precision):物体検出モデルが異なるクラスの物体をどれだけ正確に検出できるかを測定する指標です。mAPは、全てのクラスにわたるAverage Precision (AP) の平均値を取ることによって計算されます。APは、モデルが特定のクラスの物体を検出する際の精度(Precision)と再現率(Recall)の関係を表す曲線の下の面積です。
IoU (Intersection Over Union):検出されたバウンディングボックスと実際のバウンディングボックスの重なり具合を測定する指標です。IoUは、バウンディングボックスの交差部分の面積を二つのボックスの統合面積で割ったもので、0から1の値を取ります。
50% IoU:mAP50では、IoUの閾値を50%と設定しています。つまり、モデルによって検出されたバウンディングボックスが実際のバウンディングボックスと50%以上重なっていれば、その検出を正しいものとみなします。
mAP50は、モデルが物体をどれだけ正確に検出できるか、そしてその検出がどれほど信頼できるかを示す指標として重宝されます。IoUの閾値を50%と設定することで、検出の正確さにおけるある程度の許容範囲を設けつつ、モデルの性能を評価できます。
詳細が知りたい方は こちらの記事 が分かりやすいので、ご参照ください。
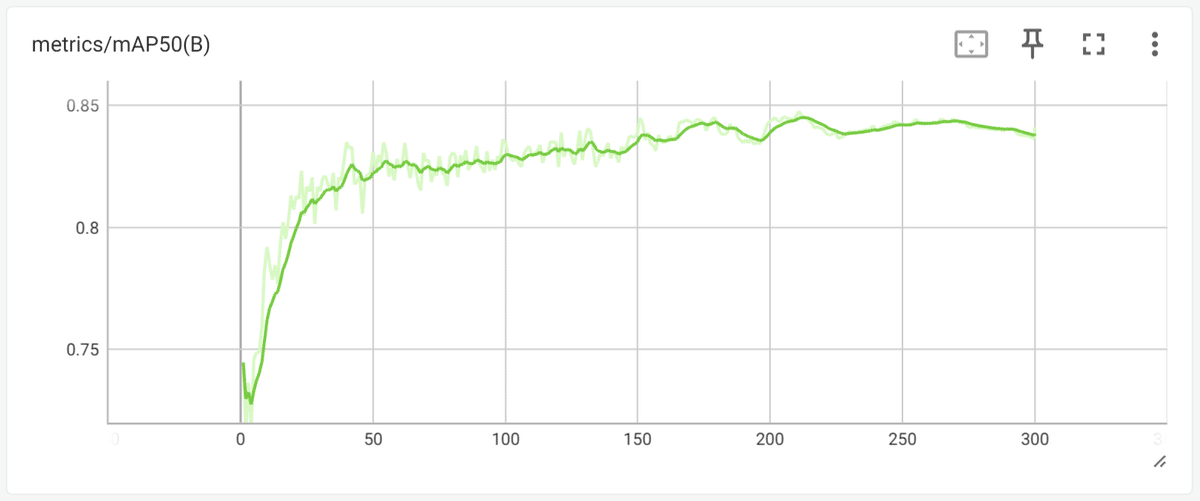
mAP50の推移を見るとエポックが進むにつれて順調に上昇し、200エポック前後で頭打ちになっています。先ほどの validation loss は150エポック程で収束しており、そこから先は train loss との差が開いたため、過学習が懸念されていましたが、mAP50を見ると上がりきった後は下がってきていないので、大きな過学習は起こしていません。ただし前述の通りmAP50は200エポック以降は平行線なので、それ以降の学習は重みにノイズを与えているだけの可能性が高く、今回の転移学習では170~220エポックの範囲に、モデルの重みの最適条件が存在すると言えそうです。
最適になった時点で学習を手動停止しても、モデルファイルを得ることは可能ですが、YOLOでは最後まで学習を完了させると以下の2つのモデルが出力されます。
① model_last.pt ・・・完走後の最終的なモデル
② model_best.pt ・・・訓練中の最もメトリクスが良い時点のモデル
今回は上記検証により、訓練途中でモデルが最適な重みになった可能性が高いので、② model_best.pt をアプリ用のモデルとして採用します。
学習済モデルの精度確認
転移学習済のモデル model_best.pt をロードして、YOLO関数で推論をして、精度を確認します。(コードは前述と同様なので割愛)
まずは train データ(学習済データ)である離乳食画像での推論です。

全てのテキストに対して正しい位置にバウンディングボックスが描写されており、正確にテキスト検出ができていると言えます。バウンディングボックスの左上の数値は推論の信頼値です。最大が1.0で数値が大きいほどモデルにとって自信のある推論結果です。つまり、全てのテキスト領域が自信を持って検出された事になりますが、これは学習で使用したデータセットなので正確に推論ができて当たり前です。
次に、未学習データ (train にも validation にも未使用のデータ) の推論をしてみます。

未学習データでもほぼ正しく推論ができています。一部バウンディングボックスがかぶってしまっている部分(左上の昆布)がありますが、かぶりのバウンディングボックスは信頼値が0.28と低いので、描写の際に信頼値の閾値を設けてフィルタリングをすることで、かぶり検出やその他の誤検出のボックス描写を抑制する事ができそうです。
最後に、一般的な画像に対しての推論をしてみます。

こちらもある程度の精度でテキストエリアの検出ができています。
■ 転移学習モデルの構築の結論は以下です。
・課題の離乳食記録画像について、未学習データへのテキスト領域検出が
可能なモデルを構築する事ができた。
・一般の画像についても、ある程度の精度でテキストエリアの検出が可能な
事が確認でき、一定の汎用性を持ったモデルを構築する事ができた。
バックエンド開発
この章から先は前章までの取組みにより構築したテキスト領域検出モデルを駆使して、実際にユーザーが画像ファイルからテキストデータを抽出する事が可能なwebアプリケーションを作成していきます。
アプリ設計
目標設定で定義した要件を満たすようにアプリ全体の設計をします。
今回はwebアプリライブラリとして、F;askを使用します。メインアプリケーションのファイル名を、app.py として、 Flaskインスタンスを "app" という名前で定義します。テキスト領域検出、OCR処理、および メンテナンス用のタスクの処理内容は、別のモジュールスクリプトに記述し、app.py にimportして呼び出すようにします。
アプリ機能のために、アップロード用フォルダ、処理結果を保存するフォルダ、ログを保存するフォルダ、セッション管理用フォルダ、そしてモデルを格納しておくフォルダを配置します。
その他はフロントエンド関連、webアプリのデプロイ時に使用するものなので、後述します。
下図は、webアプリの全体像を示した設計図です。
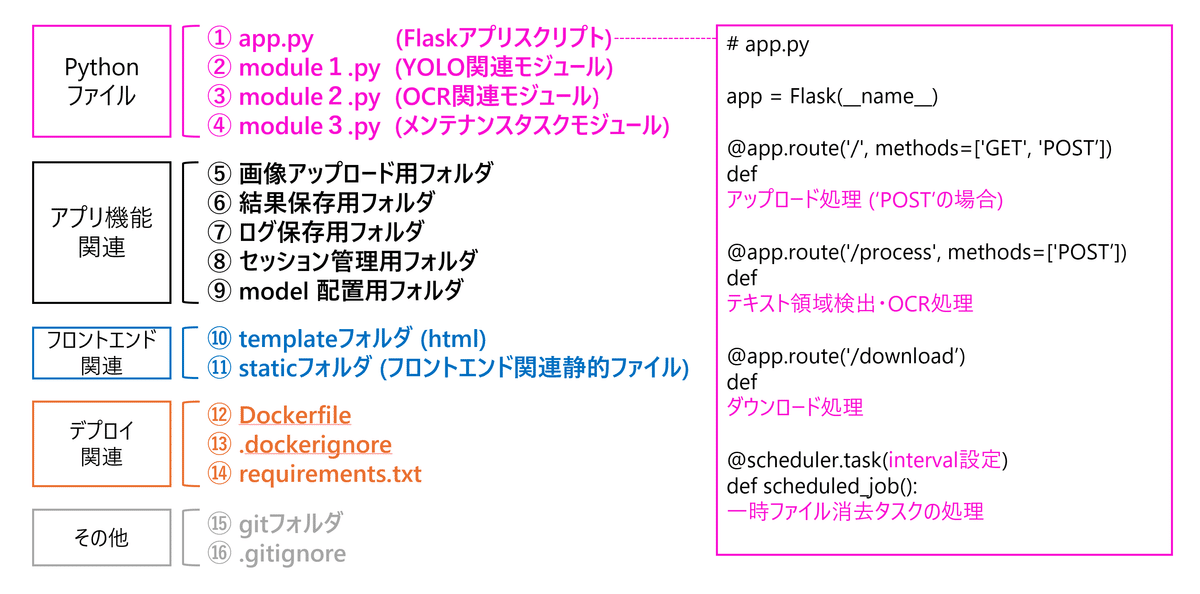
app.py の基本的なつくりとして、今回はとにかくなるべくシンプルになるように設計しました。ホーム画面で "POST" リクエストで、ユーザーからの画像アップロード処理を実行し、/process に "POST" リクエストにて画像処理を実行、/download に "GET" でユーザーに結果をダウンロードして貰う、たったこれだけのシンプルな流れにします。
ユーザー側で必要な操作は3回のみ、
1.手持ち画像のアップロード
2.処理スタートボタンをクリック
3.結果のダウンロード
以上でアプリケーションの体験が完了するような、シンプルイズベストな流れをイメージしました。
コーディング
以下より、各スクリプトを表示します。ここに至るまでに、要件の定義とアプリの全体設計がきちんと出来ていたため、コーディング中にあれこれと方針が変わる事はありませんでした。よって特段、検証や検討をしなかったので、結果のみを示します。
◆ Flaskアプリケーションスクリプト (app.py)
# 外部ライブラリ
import os
import sys
import uuid
import pytz
import shutil
import pandas as pd
import logging
from logging.handlers import TimedRotatingFileHandler
from flask import (
Flask, render_template, send_file, redirect, jsonify,
current_app, request, session
)
from flask_apscheduler import APScheduler
from datetime import datetime, timedelta
from werkzeug.utils import secure_filename
# モジュールスクリプト
from main import (
predict_imgs_labels,
draw_bounding_boxes_and_crop,
save_cropped_images
)
from ocr import (
ocr_engine,
PICs_OCR_to_dic
)
from sessions import check_session_timeouts
# ログ収集に関するクラス定義・ログ設定・標準出力の置き換え
log_directory = "./log"
if not os.path.exists(log_directory): # ログディレクトリを確認し存在しない場合は作成
os.makedirs(log_directory)
# ロガーの設定
logger = logging.getLogger('MyAppLogger')
logger.setLevel(logging.DEBUG) # ロガーのログレベルを DEBUG に設定
# ファイルハンドラーの設定 (TimedRotatingFileHandlerを使用)
log_filename = "./log/app.log"
file_handler = TimedRotatingFileHandler(
log_filename,
when="midnight", # ログファイルの切り替えは深夜に実施する
interval=7, # 7日間隔でログファイルを切り替える
backupCount=150 # 古いログファイルは150個保持しそれ以上は削除する
)
file_handler.setLevel(logging.DEBUG) # ハンドラーのログレベルを DEBUG に設定
file_handler.setFormatter(logging.Formatter('%(asctime)s:%(levelname)s:%(name)s:%(message)s'))
file_handler.suffix = "%Y%m%d" # ファイル名のサフィックスに日付を追加
# ロガーにハンドラーを追加
logger.addHandler(file_handler)
# 標準出力をログにリダイレクトするクラス
class StreamToLogger(object):
def __init__(self, logger, log_level=logging.INFO): # デフォルトのログレベルを INFO に設定
self.logger = logger
self.log_level = log_level
self.linebuf = ''
def write(self, buf):
for line in buf.rstrip().splitlines():
self.logger.log(self.log_level, line.rstrip())
print(line, file=sys.__stdout__) # ターミナルにも出力を表示
def flush(self):
pass
# 標準出力を置き換える
sys.stdout = StreamToLogger(logger, logging.INFO) # 標準出力のリダイレクト時のログレベルを INFO に設定
# アプリ設定部
app = Flask(__name__)
app.secret_key = 'your_secret_key' # セッションを使用するための秘密鍵
scheduler = APScheduler() # APSchedulerのインスタンスを作成
UPLOAD_FOLDER = './uploads' # ユーザーがアップロードした画像を一時保存するフォルダのパス
TEMP_FOLDER = './views' # 一時作業フォルダのパス
ALLOWED_EXTENSIONS = {'jpg','jpeg','png','gif','tif','tiff','bmp'} # アップロードを許容する拡張子
# appのグローバル設定へ反映
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
app.config['TEMP_FOLDER'] = TEMP_FOLDER
app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(hours=1) # セッションの有効期限を1hに設定
# ファイルの拡張子チェック
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
# アップロード部関数
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
# 東京のタイムゾーンを設定
tokyo_timezone = pytz.timezone('Asia/Tokyo')
# ユニークなフォルダ名の生成(日時+UUID4(8桁)の組み合わせ)
current_time = datetime.now(tokyo_timezone).strftime('%Y%m%d%H%M%S') # 東京の日時を整数で取得
unique_folder_name = current_time + '_' + str(uuid.uuid4())[:8]
session['unique_code'] = unique_folder_name # セッションにフォルダ名を保存
upload_path = os.path.join(current_app.config['UPLOAD_FOLDER'], unique_folder_name)
# ユニークなフォルダの作成
os.makedirs(upload_path, exist_ok=True)
# セッション管理用のダミーファイルの作成
session_tag_folder = os.path.join(app.root_path, 'sessions_tag')
os.makedirs(session_tag_folder, exist_ok=True) # フォルダが無ければ作成する
with open(os.path.join(session_tag_folder, f'{unique_folder_name}.txt'), 'w') as f:
f.write('')
# アップロードファイルがない場合の処理
if 'file' not in request.files:
return redirect(request.url)
files = request.files.getlist('file') # 複数ファイルを取得
uploaded_files = [] # アップロードされたファイル名のリスト
for file in files:
if file.filename == '' or not allowed_file(file.filename):
continue
filename = secure_filename(file.filename)
file_path = os.path.join(upload_path, filename)
file.save(file_path)
uploaded_files.append(filename)
print(f"Pics uploaded by user in the session: {unique_folder_name}")
# アップロード完了後、ファイル一覧を表示
return render_template('index.html', files=uploaded_files, folder=unique_folder_name)
return render_template('index.html', files=[], folder=None)
# 処理部関数
@app.route('/process', methods=['POST'])
def process():
if 'unique_code' not in session:
return 'セッションが存在しません', 400
# 出力先の一時フォルダ
output_root_dir = current_app.config['TEMP_FOLDER']
# セッションのユニークなフォルダ名
unique_folder_name = session['unique_code']
# アップロードされた画像フォルダのパス
imgs_dir_path = os.path.join(current_app.config['UPLOAD_FOLDER'], unique_folder_name)
# アップロードされたファイルの存在チェック
if not os.listdir(imgs_dir_path):
# アップロードフォルダが空の場合
return jsonify({'error': 'ファイルが間違っています'}), 400
# 推論実行部: 全画像ファイルに対して処理を実行
trans_learned_weights_path = "./model/yolo_txt_trans.pt" # 推論で使用するモデルのパス
print(f"Making predictions for all images of {unique_folder_name} by Trans_Learned_YOLO_Model")
predict_imgs_labels(trans_learned_weights_path, imgs_dir_path, output_root_dir, unique_folder_name)
print(f"Complete all prediction for pics of {unique_folder_name}")
# 推論部描写・切り取り実行部
# 予測値のディレクトリパス
predicted_dir = os.path.join(current_app.config['TEMP_FOLDER'], unique_folder_name, 'labels')
# 画像出力ディレクトリパス
output_dir = os.path.join(current_app.config['TEMP_FOLDER'], unique_folder_name)
# cropイメージの辞書(key:連番)を画像ファイル名をキーとして格納する辞書の初期化
all_images_crops = {}
# ボックス検出クライテリアの設定
criteria = 0.695
# 全ての画像にバウンディングボックスを描写し保存しcrop画像をファイル名をkeyとした辞書に格納しall_images_cropsに格納
for file_name in os.listdir(imgs_dir_path):
if file_name.lower().endswith(('jpg','jpeg','png','gif','tif','tiff','bmp')):
image_path = os.path.join(imgs_dir_path, file_name)
prediction_path = os.path.join(predicted_dir, os.path.splitext(file_name)[0] + '.txt')
output_path = os.path.join(output_dir, os.path.splitext(file_name)[0] + '_texts_detected.jpg')
print(f"Drawing prediction box in {file_name}")
crops = draw_bounding_boxes_and_crop(image_path, prediction_path, output_path, criteria)
# 辞書名としてのキーの生成
crops_dict_name = f'{os.path.splitext(file_name)[0]}_{os.path.splitext(file_name)[1][1:]}_crops'
# cropsにキーを付けてリストに追加
all_images_crops[crops_dict_name] = crops
# クロッピングした画像を保存
cropped_dir_path = f'{output_dir}/cropped'
save_cropped_images(all_images_crops, cropped_dir_path)
print(f"Complete Draw and Crop for {unique_folder_name}")
# クロップ画像に対するOCR処理実行部:抽出テキストをcsvファイルで保存
# 実行引数の設定
tool = ocr_engine()
threshold = 105 # 閾値の設定(0-255)※結果を見ながら要調整
langs = ['eng', 'jpn'] # 英語と日本語の学習モデルを設定
tesseract_layout_set = 7 # OCRモード設定 画像が1行のテキスト場合は7 デフォルトは3
# 言語ごとに処理
for lang in langs:
# 抽出テキストを格納するデータフレームを初期化
extracted_txt_df = pd.DataFrame()
print(f"Start {lang} OCR process")
for key, images in all_images_crops.items():
print(f"Extracting {lang} texts in {key}")
extracted_txt_list = PICs_OCR_to_dic(
key,
tool,
images,
threshold,
lang,
tesseract_layout_set,
cropped_dir_path
)
# A列にkeyを設定し、B列以降にextracted_txt_listの内容を追加
new_row = [key] + extracted_txt_list
# 新しい行をデータフレームに変換し、列の数に合わせて列名を設定
new_row_df = pd.DataFrame([new_row], columns=['A'] + [f'B{i}' for i in range(1, len(new_row))])
# 新しい行をデータフレームに追加
extracted_txt_df = pd.concat([extracted_txt_df, new_row_df], ignore_index=True)
# 列名の設定(A列は'subfolder'、残りは連番)
columns = ['Image Name'] + [f'text_{i+1}' for i in range(len(extracted_txt_df.columns) - 1)]
extracted_txt_df.columns = columns
# 言語ごとに保存設定を分岐
if lang == 'eng':
file_name = 'Extracted_TEXT_eng.csv'
encoding = 'utf-8'
else: # = 'jpn'
file_name = 'Extracted_TEXT_jpn.csv'
encoding = 'cp932'
# CSVに保存
print(f"Saving {lang} texts for csv")
txt_save_dir = f'{output_dir}/extracted_text' # CSVを保存するディレクトリのパス
os.makedirs(txt_save_dir, exist_ok=True) # ディレクトリが存在しない場合は作成
extracted_txt_df.to_csv(os.path.join(txt_save_dir, file_name), index=False, encoding=encoding)
print(f"Complete OCR process")
# 処理完了後、出力先フォルダを圧縮
shutil.make_archive(os.path.join(current_app.config['TEMP_FOLDER'], unique_folder_name), 'zip', output_dir)
# 圧縮ファイルの名前とフルパスを生成
zip_filename = f"{unique_folder_name}.zip"
zip_full_path = os.path.join(current_app.config['TEMP_FOLDER'], zip_filename)
print(f"Compressed all result files as {zip_full_path}")
# ダウンロードURLを生成しながらファイル名をクエリパラメータ'file'に渡す
download_url = f"/download?file={zip_filename}"
# JSON形式でダウンロードURLをフロントエンドに送信
return jsonify({'downloadUrl': download_url})
# ダウンロード部関数
@app.route('/download')
def download_file():
file_name = request.args.get('file')
if not file_name:
return "No download file name specified", 400
# 実際のファイルパスを構築
zip_file_path = os.path.join(current_app.config['TEMP_FOLDER'], file_name)
# ファイルの存在を確認
if not os.path.exists(zip_file_path):
return "Download file not found", 404
# ファイルを送信
print(f"Downloaded {zip_file_path} by user")
return send_file(zip_file_path, as_attachment=True)
# スケジュールされたジョブの設定
@scheduler.task('interval', id='check_sessions', seconds=300, misfire_grace_time=900)
def scheduled_job():
message = check_session_timeouts()
print(message)
# Flaskアプリ起動部(開発環境用)
if __name__ == "__main__":
scheduler.init_app(app) # schedulerにappを設定
scheduler.start() # schedulerを開始
app.run(debug=False, host='0.0.0.0') app.py では下記の処理をしています。
・画像のアップロード → uploads 内にユニーク名のフォルダを作成し保存
・処理スタート → YOLOによる推論、スコアの取得
→ views フォルダにユニーク名のフォルダを作成し保存
→ バウンディングボックスを描写・保存
→ ボックス部をクロッピングし、辞書格納&フォルダに保存
→ クロップ画像辞書をOCR処理、抽出テキストをdfに格納
→ テキストdfをファイル名ごとに整理してcsv出力
→ ユニーク名のフォルダごと zip化
・ダウンロード → ユーザーによって zip ファイルをダウンロード
※この時クエリ情報と一致した場合のみダウンロード許可
・その他
スケジュールタスク起動(300秒に一回) → 作成後 45分経過のファイル削除
ログの保存 ロガーを設定、print()コメント部も含め全て記録する
ログファイルは、肥大化を防ぐために一定周期で再作成する
◆モジュールスクリプト#1 (main.py)
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
import os
import platform
# 以下 関数定義部のみ
# 予測値からバウンディングボックスの描写をする関数
def draw_bounding_boxes_and_crop(image_path, annotation_path, output_path, criteria):
with Image.open(image_path) as img:
img = img.convert('RGB') # RGBAからRGBへ変換(アルファチャンネルがある場合の対応)
draw = ImageDraw.Draw(img)
# 画像のサイズに基づいて線の太さとフォントサイズを動的に決定
line_thickness = min(max(round(img.width * 0.004), 2), 4) # 線の太さを範囲内で画像横幅から算出
font_size = min(max(round(img.width * 0.032), 14), 40) # フォントサイズを範囲内で画像横幅から算出
# 実行環境に応じたフォント設定
if platform.system() == "Windows":
font_name = "arial.ttf"
elif platform.system() == "Linux":
font_name = "/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf"
else:
font_name = None # 他のOSの場合
try:
if font_name:
font = ImageFont.truetype(font_name, font_size)
else:
raise IOError # フォント名が設定されていない場合、デフォルトフォントを使用
except IOError:
font = ImageFont.load_default()
crops = {}
if os.path.exists(annotation_path):
with open(annotation_path, 'r') as file:
for idx, line in enumerate(file, 1):
# YOLOフォーマットデータを解析
parts = line.strip().split()
_, x_center, y_center, width, height, conf = map(float, parts)
# conf が criteria を上回る場合のみ処理を続行
if conf > criteria:
# YOLO形式の相対座標を画像のピクセル座標に変換
x_center_pix = x_center * img.width
y_center_pix = y_center * img.height
width_pix = width * img.width
height_pix = height * img.height
# バウンディング部の左上と右下の座標を計算
left = int(x_center_pix - width_pix / 2)
top = int(y_center_pix - height_pix / 2)
right = int(x_center_pix + width_pix / 2)
bottom = int(y_center_pix + height_pix / 2)
# バウンディング部をクロップしcropsへ格納
crop = img.crop((left, top, right, bottom))
crops[f'{str(idx).zfill(3)}'] = crop
# バウンディングボックスを描画
draw.rectangle([left, top, right, bottom], outline="Magenta", width=line_thickness)
# 信頼度をテキストとして描画(バウンディングボックスの上部に表示)
conf_cent = conf*100
conf_text = f"{conf_cent:.1f}" # 信頼度を100倍したものを小数点以下1桁で表示
draw.text((left, top+height_pix), conf_text, fill="Magenta", font=font)
img.save(output_path) # 描写済の画像を保存
return crops
# 辞書内のクロッピング画像を辞書名のフォルダを作成して保存する関数
def save_cropped_images(dict_of_dicts, save_directory):
# 辞書内の全辞書に対してイテレート
for name, images in dict_of_dicts.items():
# 保存用フォルダのパスを生成
folder_path = os.path.join(save_directory, name)
print(f"Saving cropped images of {name}")
# フォルダが存在しない場合は作成
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 辞書内の全画像に対してイテレート
for key, image in images.items():
# 画像ファイル名を生成
image_filename = f"{key}.jpg"
# 画像保存パスを生成
image_path = os.path.join(folder_path, image_filename)
# 画像を保存
image.save(image_path)
# 推論実行し取得値をTEMP内の{unique_code}フォルダに保存する関数
def predict_imgs_labels(
trans_learned_weights_path,
imgs_dir_path,
project_root_folder,
unique_code
):
# モデルのインスタンス
model = YOLO(trans_learned_weights_path)
model(
imgs_dir_path, # images path
save = False, # not save images
save_txt = True, # save results to *.txt
save_conf = True, # save confidences in --save-txt labels
save_crop = False, # not save cropped prediction boxes
project = project_root_folder, # saving results root dir path
name = unique_code, # make subdir in project dir
exist_ok = True, # overwrite if old files exist
line_width = 2, # bounding box thickness (pixels)
show_labels = False # hide labels on images
)main.py では、主にテキストエリアの推論や推論結果の描写や保存に関する関数を定義しています。
◆ モジュールスクリプト#2 (ocr.py)
import pyocr
from PIL import ImageEnhance
import os
# 以下 関数定義部のみ
# OCRツールのリストを取得する関数
def set_tesseract():
tools = pyocr.get_available_tools()
if len(tools) == 0:
# 使用可能な OCR ツールがない場合、ローカル内の Tesseract-OCR のパスを環境変数に追加
TESSERACT_PATH = r'C:\\Program Files\\Tesseract-OCR\\' # Tesseract-OCR フォルダ
TESSDATA_PATH = r'C:\\Program Files\\Tesseract-OCR\\tessdata' # 訓練データのフォルダ
os.environ["PATH"] += os.pathsep + TESSERACT_PATH
os.environ["TESSDATA_PREFIX"] = TESSDATA_PATH
# 環境変数を更新した後、もう一度使用可能なツールを確認
tools = pyocr.get_available_tools()
return tools
# OCRエンジンを取得する関数
def ocr_engine():
tools = set_tesseract() # OCR ツールのリストを取得
if len(tools) > 0: # tools リストが空でないことを確認
tool = tools[0] # 最初のツールを使用
print(f"Start the OCR tool: {tool}") # 使用するOCRの表示
return tool
else:
# 使用可能な OCR ツールが見つからない場合はエラーメッセージとともに中断
raise RuntimeError("No available OCR tools found")
# 画像を前処理する関数
def pretreat_img(img, threshold):
img_g = img.convert('L') #Grayscale変換
enhancer= ImageEnhance.Contrast(img_g) #コントラストを上げるための設定
img_con = enhancer.enhance(2.0) #コントラストを上げる処理を実行
img_bin = img_con.point(lambda x: 0 if x < threshold else 255, '1') # バイナリ化適用(二値化)
return img_bin
# 画像からOCRで日本語を読み取り文字列として抽出する関数
def pic_to_txt(tool, img_bin, lang, tesseract_layout_set):
builder_pyocr = pyocr.builders.TextBuilder(tesseract_layout=tesseract_layout_set)
txt_pyocr = tool.image_to_string(img_bin, lang=lang, builder=builder_pyocr)
txt_pyocr_space_cut = txt_pyocr.replace(' ', '') #半角スペースを消す ※読みやすくするため
return txt_pyocr_space_cut
# フォルダ内の画像をOCR処理して結果をリストに格納し、前処理画像は元フォルダに保存する関数
def PICs_OCR_to_dic(
folder_name,
tool,
pic_dict,
threshold,
lang,
tesseract_layout_set,
save_dir):
extracted_txt_list = [] #抽出したテキストを格納するリストを初期化
for key, img in pic_dict.items():
img_bin = pretreat_img(img, threshold)
txt = pic_to_txt(tool, img_bin, lang, tesseract_layout_set)
# テキストをリストに追加
extracted_txt_list.append(txt)
# 前処理後の画像を元のフォルダに保存
save_path = f"{save_dir}/{folder_name}/{key}_bin.jpg"
img_bin.save(save_path)
return extracted_txt_listocr.py では、main.py の関数にて取得したクロップ画像にOCR処理を施して、テキストデータを抽出し保存する関数を定義しています。
◆ モジュールスクリプト#3 (sessions.py)
import os
import shutil
from datetime import datetime, timedelta
# 以下 関数定義部のみ
# セッションのタイムアウトをチェックしフォルダを削除する関数
def check_session_timeouts():
session_tag_folder = os.path.join('./sessions_tag')
now = datetime.now()
message = "Checked for expired sessions"
for filename in os.listdir(session_tag_folder):
file_path = os.path.join(session_tag_folder, filename)
file_time = datetime.fromtimestamp(os.path.getmtime(file_path))
# ファイルの作成日時から45分が経過しているかチェック
if now - file_time > timedelta(minutes=45):
# ダミーファイルの削除
if os.path.exists(file_path):
try:
os.remove(file_path)
print(f'Dummy file {filename} is deleted')
except Exception as e:
print(f'Failed to delete the dummy file {filename}: {e}')
# 削除対象のフォルダ・ファイルのパスを定義
uploads_folder = os.path.join("./uploads", filename.split('.')[0])
work_folder = os.path.join("./views", filename.split('.')[0])
work_zip_file = f"{work_folder}.zip"
# uploads_folder の存在チェックと削除
if os.path.exists(uploads_folder):
try:
shutil.rmtree(uploads_folder)
print(f"Uploaded folder {uploads_folder} and its contents are deleted")
except Exception as e:
print(f'Failed to delete the folder {uploads_folder}: {e}')
else:
# フォルダが存在しない場合
print(f"{uploads_folder} does not exist")
# work_folder の存在チェックと削除
if os.path.exists(work_folder):
try:
shutil.rmtree(work_folder)
print(f"Work folder {work_folder} and its contents are deleted")
except Exception as e:
print(f'Failed to delete the folder {work_folder}: {e}')
else:
# フォルダが存在しない場合
print(f"{work_folder} does not exist")
# work_zip_file の存在チェックと削除
if os.path.isfile(work_zip_file):
try:
# ファイルを削除
os.remove(work_zip_file)
print(f"{work_zip_file} is deleted")
except Exception as e:
# 削除操作に失敗した場合
print(f'Failed to delete the file {work_zip_file}: {e}')
else:
# ファイルが存在しない場合
print(f"{work_zip_file} does not exist")
return messagesessions.pyは、app.py から一定間隔でスケジュール起動された場合に実行されるスクリプトです。アプリケーションの一時ファイルが肥大化する事を防ぐために、セッションの開始(=ユニーク名のフォルダが作成される)から45分間が過ぎた一時ファイルを全て削除します。
フロントエンド開発
最初に、本webアプリケーションの開発において、フロントエンド部分はあまり開発に力を注いでいません。これは、作者がバックエンド開発、およびデータサイエンス方向に能力を伸ばしたいという意向があり、webアプリの計画段階から、事前検証・モデル構築・バックエンド開発に大部分の時間を使うように計画していたためです。
テンプレート
今回、フロントエンドのカスタムベースとして Cafi Net 様の無料テンプレートを利用させて頂きました。(規約を守り使用しています)
アプリのコンセプトとして掲げた ”シンプル” の部分にコミットするために、本アプリのフロントエンドは、SPA (Single Page Application) 構造を採用します。SPAは1つのWebページのみで構成されるアプリケーションフロントエンドで、全てのコンテンツやデータの読み込みが最初のページロード時に行われ、ユーザーの操作に応じて動的にコンテンツが更新されます。これにより、従来のマルチページアプリケーションと比べて、ページ遷移時のロード時間が短縮され、スムーズなユーザー体験が提供されます。JavaScriptを中心に、AjaxやHTML5のAPIsなどを利用して実装されます。
コーティング
以下より、フロントエンドのコードを示します。
◆ index.html
<!doctype html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>TXT DETECTOR</title>
<meta name="description" content="画像から文字を検出するアプリ">
<link rel="stylesheet" type="text/css" href="./static/mit/normalize.css">
<link rel="stylesheet" type="text/css" href="./static/style.css">
<script src="./static/mit/jquery-1.9.1.min.js"></script>
<script src="./static/script.js"></script>
<link rel="icon" href="/static/favicon/fav.ico" type="image/x-icon">
</head>
<body>
<div id="overlay">
<div class="loader"></div>
</div>
<!-- header -->
<header id="0">
<div class="max_width">
<p id="menu_button"><img src="./static/images/menu-button.png" alt="メニューボタン" /></p>
<p id="site_title"><a href="#" id="reloadPage"><img src="./static/images/sitetitle001.png" alt="サイトタイトル"></a></p>
<nav id="nav">
<ul>
<li><a href="#0">トップ</a></li>
<li><a href="#1">はじめに</a></li>
<li><a href="#2">使用方法</a></li>
<li><a href="#3">アップロード</a></li>
<li><a href="#4">処理開始</a></li>
<li><a href="#5">ダウンロード</a></li>
</ul>
</nav>
</div><!-- max_width -->
</header>
<!-- ブロック1 ここから -->
<div class="content_wrap1" id="1">
<div class="max_width">
<article class="content">
<h1>はじめに</h1>
<p> このアプリでは画像のテキストエリアの検出とOCRによる文字変換が出来ます。</p>
<p> テキスト検出には <a href="https://docs.ultralytics.com/ja/models/yolov9/" target="_blank" rel="nofollow">
<span class="color4">ultralytics社の YOLOv9</span></a> をベースに転移学習をしたモデル、文字変換には
<a href="https://github.com/UB-Mannheim/tesseract/wiki" target="_blank" rel="nofollow">
<span class="color4">Tesseract-OCR</span></a> を利用しています。
</article>
</div><!-- max_width -->
</div><!-- content_wrap1 -->
<!-- ブロック1 ここまで -->
<!-- ブロック2 ここから -->
<div class="content_wrap2" id="2">
<div class="max_width">
<article class="content">
<h1>使用方法</h1>
<p><img src="./static/images/how_to.png" alt="説明用のキャプチャ"/></p>
<p>画像をアップロードし、処理STARTをクリックしてください。その他の操作はありません。</p>
<p>処理完了後、バウンディングボックス付画像、推論スコア、クロップ画像、
バイナリ(白黒二値化)画像、抽出したテキストの結果、</p>
<p>これらをzip形式でダウンロード可能です。</p>
<p>バウンディングボックスの左下の数値は信頼度で最大が100です。70以上の予測のみ結果へ反映しています。</p>
<p>推論スコアは画像ごとに1つ生成され、最初の4つはボックスの座標、5つ目は信頼度です。</p>
<p>どのファイル種でもボックス付画像は拡張子が .jpg になりますが、画像サイズは変更しません。</p>
</article>
</div><!-- max_width -->
</div><!-- content_wrap2 -->
<!-- ブロック2 ここまで -->
<!-- ブロック3 ここから -->
<div class="content_wrap1" id="3">
<div class="max_width">
<article class="content">
<h1>アップロード</h1>
<p> アップロード可能なファイルの拡張子は <span class="color2">jpg, jpeg, png, gif, tif, tiff, bmp</span> です。</p>
<p> 複数ファイルの選択が可能です。</p>
<p> </p>
<!-- アップロードフォームの配置 -->
<form class="center-container" id="uploadForm" method="post" enctype="multipart/form-data" action="/">
<input type="file" name="file" multiple accept=".jpg,.jpeg,.png,.gif,.tif,.tiff,.bmp">
<button type="submit">アップロード</button>
</form>
<p> </p>
<p class="supplement center-container">※フォルダを選択することはできません、直接ファイルを複数選択してください。</p>
</article>
</div><!-- max_width -->
</div><!-- content_wrap1 -->
<!-- ブロック3 ここまで -->
<!-- ブロック4 ここから -->
<div class="content_wrap2" id="4">
<div class="max_width">
<article class="content">
<h1>処理開始</h1>
<p> ファイルのアップロードが完了するとボタンが表示されます。</p>
<p class="supplement"> ※高画質またはファイル数が多い場合は時間がかかる事があります。</p>
<!-- 処理開始ボタン(初期は非表示) -->
<div class="center-container">
<button id="processButton" style="display:none;">START</button>
</div>
</article>
</div><!-- max_width -->
</div><!-- content_wrap2 -->
<!-- ブロック4 ここまで -->
<!-- ブロック5 ここから -->
<div class="content_wrap1" id="5">
<div class="max_width">
<article class="content">
<h1>ダウンロード</h1>
<p> 全ての処理が完了するとリンクが表示されます。</p>
<!-- ダウンロードリンク(初期は非表示) -->
<div class="center-container">
<a id="downloadLink" href="#" style="display:none;">DOWNLOAD</a>
</div>
</article>
</div><!-- max_width -->
</div><!-- content_wrap1 -->
<!-- ブロック5 ここまで -->
<!-- ブロック6 ここから -->
<div class="content_wrap2" id="6">
<div class="max_width">
<article class="content">
<h1>制作にあたって</h1>
<p>■このWebアプリは下記のご協力を頂き制作されました。</p>
<p>●プログラミングスクール <a href="https://aidemy.net/" target="_blank" rel="nofollow">
<span class="color4">Aidemy</span></a> 様のサポートを頂きました。</p>
<p>●フロントエンドは <a href="https://japanism.info/index.html" target="_blank" rel="nofollow">
<span class="color4">Cafi Net</span></a> 様の無料テンプレートを参考にしました。</p>
<p>●転移学習のデータセットの一部を <a href="https://universe.roboflow.com/" target="_blank" rel="nofollow">
<span class="color4">Roboflow Universe</span></a> から利用しました。</p>
<p>●物体検出モデル: <a href="https://www.ultralytics.com/" target="_blank" rel="nofollow">
<span class="color4">ultralytics</span></a> YOLOv9 を転移学習</p>
<p>●OCRモデル: <a href="https://github.com/UB-Mannheim/tesseract/wiki" target="_blank" rel="nofollow">
<span class="color4">Tesseract</span></a> (Linux版)</p>
</article>
</div>
</div>
<!-- ブロック6 ここまで -->
<!-- Footer -->
<div class="footer_wrap">
<div class="max_width">
<footer>
<p>Copyright©2024 TXT DETECTOR</p>
<!-- 下の行を変更したり削除すると、無料テンプレートの利用規約違反になる。 -->
<p><a href="http://japanism.info/free-template.html" target="_blank" rel="nofollow">Free Template</a></p>
<!-- 上の行を変更したり削除すると、無料テンプレートの利用規約違反になる。 -->
</footer>
</div><!-- max_width -->
</div><!-- footer_wrap -->
<script src="./static/process.js"></script>
</body>
</html> index.html では、アプリのSPA メインページの骨格を記述しています。
6つのブロック+ヘッダー+フッター という基本的な構造をしており、
・アップロードブロックではUpload Form の実装をしています。
・処理スタートブロック と ダウンロードブロックには、専用のプッシュ
ボタンを配置し、 それぞれに id を設定することで後述の JavaScript で
動的な制御が掛けられるようにしています。
◆ process.js
// process.js
// タイトルリンクでページリフレッシュ
document.getElementById('reloadPage').addEventListener('click', function(e) {
e.preventDefault(); // デフォルトのアンカー動作を阻止
window.location.reload(true); // キャッシュを無視してページをリロード
});
// オーバーレイとローディングインジケーターの表示/非表示を制御
function showOverlay() {
document.getElementById('overlay').style.display = 'block';
}
function hideOverlay() {
document.getElementById('overlay').style.display = 'none';
}
// アップロード処理とそれに対するオーバーレイ呼び出し設定
document.getElementById('uploadForm').addEventListener('submit', function(e) {
e.preventDefault(); // デフォルトのフォーム送信を防止
var uploadButton = this.querySelector('button[type="submit"]');
// ファイルが選択されているかチェック
var fileInput = this.querySelector('input[type="file"]');
if (fileInput.files.length === 0) {
alert('ファイルが選択されていません。');
uploadButton.disabled = false; // ボタンを再活性化
uploadButton.classList.remove('button-disabled'); // ボタンのスタイルを元に戻す
return; // この関数から抜ける
}
showOverlay(); // オーバーレイを表示して処理中を示す
// ボタンを非活性化するコード
uploadButton.disabled = true; // ボタンを非活性化
uploadButton.classList.add('button-disabled'); // スタイルを適用してグレーアウト
var formData = new FormData(this); // フォームのデータを取得
// 非同期通信でフォームデータを送信
$.ajax({
url: '/', // 送信先URL
type: 'POST', // 送信方法
data: formData, // 送信データ
success: function(data) {
// アップロード完了後の処理
hideOverlay(); // オーバーレイを非表示に
$('#processButton').show(); // 処理開始ボタンを表示
},
cache: false,
contentType: false,
processData: false
});
});
// プロセス開始処理とそれに関わるオーバーレイやエラーハンドリング処理
document.getElementById('processButton').addEventListener('click', function() {
// ボタンを非活性化するコードをここに挿入
this.disabled = true; // ボタンを非活性化
this.classList.add('button-disabled'); // スタイルを適用してグレーアウト
showOverlay(); // オーバーレイを表示して処理が進行中であることを示す
// 非同期通信でサーバーに対するリクエストを送信
$.ajax({
url: '/process', // 処理を開始するサーバーのエンドポイント
type: 'POST',
success: function(data) {
// 処理が成功した際のコード
if (data.error) {
alert(data.error); // サーバーから返されたエラーメッセージを表示
window.location.reload(); // ページをリフレッシュ
} else {
$('#downloadLink').attr('href', data.downloadUrl).show(); // ダウンロードリンクを表示
hideOverlay(); // オーバーレイを非表示にして処理が終了したことを示す
}
},
error: function(xhr, status, error) {
// エラー処理
alert('アップロードされたファイルの種類が間違っています');
window.location.reload(); // ページをリフレッシュ
}
});
}); process.js は、JavaScriptファイルです。主にバックエンドのprocessに関連する部分の動作を制御するためのもので、index.html で配置しているボタンに対して、条件ごとに動的なアクションを呼び出す記述をしています。
・アップロード中は動的・視覚的なオーバーレイで画面を覆い、ユーザー
に他の操作をさせないようにする。(エラー防止)
・アップロード完了後はアップロードボタンを非活性化し、ユーザーに二重
アップロードをさせないようにする。
・アップロードが完了するまで、処理スタートボタンは非表示にする。
・処理スタート後、完了までの時間は動的・視覚的なオーバーレイで、ユー
ザーに対して処理進行中である事を明示し、退室を留まらせる。
・処理完了後は処理スタートボタンを非活性化し、二重処理を防止する。
・ダウンロードボタンは、処理完了まで非表示にする。
◆ script.js
// script.js
$(function(){
var min_width = 600;
// mobile nav
$('#menu_button').click(function(){
if($('#nav').css('margin-left')=='-200px') {
$('#nav').animate({'margin-left':'0px'},'fast','linear');
} else {
$('#nav').animate({'margin-left':'-200px'},'fast','linear');
}
});
$('#nav ul li a').click(function(){
if($(document).width() < min_width && $('#nav').css('margin-left')=='0px') {
$('#nav').animate({'margin-left':'-200px'},'fast','linear');
}
});
// scroll
$('a[href^=#]').click(function(){
var id = $($(this).attr('href')).offset().top;
$('body,html').animate({scrollTop:id},500,'swing');
return false;
});
// pc nav
if($(document).width() >= min_width) {
$(window).scroll(function(){
if($(this).scrollTop() > 80) {
$('#nav').stop(true).animate({'top':'0'},'fast','swing');
} else {
$('#nav').stop(true).animate({'top':'230'},'fast','swing');
}
});
}
}); script.js もJavaScriptファイルですが、これは無料テンプレートの初期状態からほとんど編集していません。主に、SPA の動的なナビゲーションバーに関する挙動を定義しています。
・画面幅 600 px を閾値として、挙動を分ける。(PC or スマホ 想定)
・PCではナビゲーションバーを、スマホではメニューボタンを表示する。
・ナビ or メニュー のボタンを押すと、そのブロックまでスクロールする。
◆ style.css
@charset "utf-8";
/* 文書全体 */
* {
margin: 0px;
}
/* 全てのスクリーンサイズで適用する設定 */
/* body */
body {
font-family: "ヒラギノ角ゴ Pro W3", "Hiragino Kaku Gothic Pro", "メイリオ", Meiryo, Osaka, "MS Pゴシック", "MS PGothic", sans-serif;
}
.max_width {
max-width: 1000px;
margin-right: auto;
margin-left: auto;
}
/* header */
header {
padding-top: 30px;
background-image:url(images/bg051.png);
height:90px;
text-align:center;
background-size: cover; /* 画像を引き延ばして背景全体にフィットさせる */
background-position: center; /* 画像が中央に来るように配置 */
background-repeat: no-repeat; /* 画像を繰り返さない */
}
#site_title {
margin-top: 5px; /* タイトルの上にマージンを追加 */
}
#site_title a {
padding-top: 80px;
font-family: Georgia, "Times New Roman", Times, serif;
color: #FFFFFF;
font-size: 40px;
font-weight: bold;
text-decoration: none; /* 下線を消去 */
}
#site_title img {
max-width: 360px; /* 画像の最大幅を200pxに設定 */
height: auto; /* 高さを自動調整してアスペクト比を維持 */
}
#menu_button {
position:fixed;
right:0px;
}
/* nav */
#nav {
position:fixed;
top:0px;
margin-left:-200px;
width:150px;
}
#nav ul {
padding: 0px;
background-image: url(images/bg5.png);
}
#nav ul li {
list-style-type: none;
}
#nav ul li a:link {
padding-top: 15px;
padding-right: 10px;
padding-left: 11px;
padding-bottom: 15px;
border-bottom: 1px solid #424242;
display:block;
text-align:left;
color: #FFFFFF;
text-decoration: none;
-webkit-transition: color 0.5s ease-in-out 0s;
-moz-transition: color 0.5s ease-in-out 0s;
-ms-transition: color 0.5s ease-in-out 0s;
-o-transition: color 0.5s ease-in-out 0s;
transition: color 0.5s ease-in-out 0s;
}
#nav ul li a:visited {
color: #FFFFFF;
text-decoration: none;
}
#nav ul li a:hover {
color: #B9B9B9;
text-decoration: none;
}
/* article */
.content_wrap1 {
background-image:url(images/bg2.png);
padding-top:40px;
padding-bottom:40px;
}
.content_wrap2 {
background-image:url(images/bg3.png);
padding-top:40px;
padding-bottom:40px;
}
.content {
display: inline-block;
width: 100%;
clear: both;
}
.content a:link {
color: #515151;
-webkit-transition: color 0.5s ease-in-out 0s;
-moz-transition: color 0.5s ease-in-out 0s;
-ms-transition: color 0.5s ease-in-out 0s;
-o-transition: color 0.5s ease-in-out 0s;
transition: color 0.5s ease-in-out 0s;
}
.content a:visited {
color: #464646;
}
.content a:hover {
color: #B5B5B5;
}
.content h1 {
margin-left: 5px;
clear: both;
color:#464646;
font-size:170%;
}
.content p {
margin-top: 10px;
margin-right: 5px;
margin-bottom: 10px;
margin-left: 5px;
}
.img_frame {
-webkit-box-sizing:border-box;
box-sizing:border-box;
border: 1px solid #C9C9C9;
background-color:#F7F7F7;
padding: 4px;
max-width: 100%;
height: auto;
vertical-align:bottom;
}
img {
border-style: none;
max-width: 100%;
height: auto;
vertical-align: bottom;
}
.color1 {
color:#FF0000; /* 赤色 */
}
.color2 {
color:#FF6600; /* 橙色 */
}
.color3 {
color:#9900CC; /* 紫色 */
}
.color4 {
color:#0000ee; /* 青色(リンク用) */
}
.supplement {
font-size:90%;
color:#6C6C6C; /* 補足 */
}
/* footer */
.footer_wrap {
background-image:url(images/bg4.png);
padding-top:60px;
padding-bottom:60px;
}
footer {
color: #FFFFFF;
text-align:center;
}
footer p {
margin-top: 10px;
margin-right: 5px;
margin-bottom: 10px;
margin-left: 5px;
}
footer a:link {
color: #FFFFFF;
text-decoration: none;
-webkit-transition: color 0.5s ease-in-out 0s;
-moz-transition: color 0.5s ease-in-out 0s;
-ms-transition: color 0.5s ease-in-out 0s;
-o-transition: color 0.5s ease-in-out 0s;
transition: color 0.5s ease-in-out 0s;
}
footer a:visited {
color: #FFFFFF;
text-decoration: none;
}
footer a:hover {
color: #B9B9B9;
text-decoration: none;
}
/* 動的なアイテムに関するスタイル */
.center-container {
display: flex;
justify-content: center; /* 水平方向の中央揃え */
align-items: center; /* 垂直方向の中央揃え */
min-height: 1vh; /* ビューポートの高さに合わせる */
text-align: center; /* テキストも中央揃え */
}
#processButton {
color: #444444; /* ボタンの文字色 */
font-size: 16px; /* 文字のサイズ */
font-weight: bold; /* 文字の太さ */
text-decoration: none; /* 下線を消す */
padding: 2px 68px; /* 内側の余白 */
background-color: #f8f9fa; /* 背景色 */
border: 2px solid #444444 ; /* 境界線のスタイル */
border-radius: 3px; /* 境界線の角を丸くする */
cursor: pointer; /* カーソルをポインターに */
transition: background-color 0.3s, color 0.3s; /* ホバー時の効果のための遷移 */
}
#processButton:not(:disabled):hover {
color: #fff; /* ホバー時の文字色 */
background-color: #444444; /* ホバー時の背景色 */
text-decoration: none; /* ホバー時も下線を消す */
}
#downloadLink {
color: #007bff; /* リンクの文字色 */
font-size: 16px; /* 文字のサイズ */
font-weight: bold; /* 文字の太さ */
text-decoration: none; /* 下線を消す */
padding: 3px 48px; /* 内側の余白 */
background-color: #f8f9fa; /* 背景色 */
border: 2px solid #007bff; /* 境界線のスタイル */
border-radius: 3px; /* 境界線の角を丸くする */
transition: background-color 0.3s, color 0.3s; /* ホバー時の効果のための遷移 */
}
#downloadLink:hover {
color: #fff; /* ホバー時の文字色 */
background-color: #007bff; /* ホバー時の背景色 */
text-decoration: none; /* ホバー時も下線を消す */
}
#overlay {
display: none; /* 初期状態では非表示 */
position: fixed;
top: 0;
left: 0;
right: 0;
bottom: 0;
background: rgba(0, 0, 0, 0.5); /* 半透明の黒 */
z-index: 9999; /* 他の要素より前面に */
}
.loader {
border: 16px solid #f3f3f3; /* Light grey */
border-top: 16px solid #3498db; /* Blue */
border-radius: 50%;
width: 120px;
height: 120px;
animation: spin 2s linear infinite;
position: absolute;
top: 50%;
left: 50%;
margin: -60px 0 0 -60px; /* サイズの半分のマイナスマージンで中心に配置 */
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
.button-disabled {
opacity: 0.5; /* グレーアウト効果 */
cursor: not-allowed; /* カーソルを禁止マークに */
}
/* スクリーンサイズ 幅 600px 以上で適用する設定・上から継承したスタイルを上書き */
@media only screen and (min-width: 600px) {
/* header */
header {
height:285px;
background-size: 1000px;
}
#site_title a {
padding-top:35px;
}
#site_title img {
padding-top:35px;
max-width: 800px; /* 画像の最大幅を200pxに設定 */
height: auto; /* 高さを自動調整してアスペクト比を維持 */
}
#menu_button {
display:none;
}
/* nav */
#nav {
position:fixed;
top:230px;
left:0px;
margin-left:0px;
width:100%;
background-image:url(images/bg6.png);
padding-top:15px;
padding-bottom:15px;
height:25px;
}
#nav ul {
background-image:none;
font-family:"Times New Roman"
}
#nav ul li {
display:inline-block;
margin-right: 35px;
}
#nav ul li a:link {
text-align:center;
padding-top: 0px;
padding-right: 0px;
padding-left: 0px;
padding-bottom: 0px;
border-bottom: 0px solid #424242;
}
/* article */
.content_wrap1 {
padding-top:50px;
padding-bottom:50px;
}
.content_wrap2 {
padding-top:50px;
padding-bottom:50px;
}
/* footer */
.footer_wrap {
padding-top:70px;
padding-bottom:70px;
}
/* 追加設定 */
.center-container {
min-height: 3vh; /* ビューポートの高さに合わせる */
}
} style.css は、スタイルシートです。主に SPAメインページ の外観に関する設定をしています。
・ヘッダーや各ブロックの高さ・幅・マージン、コンテンツ位置等を指定。
・文字色やフォントなどのクラスを定義。
・ホバー時など、特定の条件下のスタイルを定義。
・背景に使用する画像ファイルのパスや、描写方法を指定。
・画面幅 600 px を閾値として、超える場合の上書き設定を定義。
◆ その他
index.html はフロントエンドのメインファイルです。これは、Flaskのデフォルトルールにより、ルートディレクトリに "template" という名前のフォルダを作成し、そこへ格納する事になっています。
また、ここまでに紹介したその他のフロントエンドファイルはいずれも、 アプリにおける "静的ファイル" です。したがって、ルートディレクトリに "static" というフォルダを作成し、その中に格納します。"static" フォルダ内のどこに配置するかは自由ですが、index.html の中の <script src= タグにて正しい相対パスを指定する必要があります。
また、"静的ファイル" はまだ他にもあり、
・images ・・・ アプリの画面で表示する画像ファイル。通常は png 形式。
・jquery.min.js ・・・ jQueryの圧縮ファイル。JavaScriptの記述を簡略化し、
クロスブラウザの互換問題を解決するために設計され
た JavaScript ライブラリです。
・Favicon ・・・ webサイトを象徴する小さなアイコンでブラウザのタブ、
ブックマーク、履歴などに表示され、ウェブサイトの識別
性を高め、ユーザー体験を向上させる効果があります。
本記事では紹介していませんが、本アプリ開発でも上記は採用しており、 "static" フォルダ内に配置しています。
テスト
FlaskのDEBUGモード
当然ですが、バックエンドとフロントエンドが完成後は、開発環境で何度もテストランを実行しながら、バグ取りをしました。
Flaskの実行部の引数を、 debug=True にしておくと、DEBUGモードが有効となり、開発環境用サーバーで実行中にスクリプトの修正をして保存をすると、即座にアプリ全体にその変更が反映されるので、スピーディーにテスト&修正のサイクルを回す事が出来ます。修正をしたらその都度 git コミットしておけば、アプリのバージョン管理が出来ます。
下記はテストと修正の記録 (githistoryのスクリーンショット) の一部です。

デプロイメント
デプロイ先と手法
まず前提として、今回のwebアプリのデプロイ先として、 Render を選択しました。Render はアプリケーションやウェブサイトをビルドし実行するための統合クラウドサービスで、特にスタートアップや小規模なプロジェクトに適しています。
Render を選択したのは他にも理由があり、それは Docker との連携が容易だからです。今回、デプロイの方法として、Github を使った一般的な方法ではなく、Dockerhub から Renderサーバーへ Dockerイメージを間接的にアップロードし、Dockerコンテナとしてwebアプリをデプロイします。
Github ではなく、Dockerコンテナ を使用する理由は以下2点です。
① Linux 環境での依存関係をそのままデプロイしたかった。
→ ultralytics や pyocr などの複数のPython外部ライブラリ、および Linux
側にインストールする Tesseract-OCR の依存関係を、固定したい。
② 作者が、Docker 関連の知識を習得する必要がある。
→ 今後 Docker を経由した開発に着手したいので、経験を積みたかった。
Docker 関連の説明を本気でするとかなり複雑になるので、非常に割愛した説明となる事をお許しください。
アプリケーションを、Dockerhub経由でRender にデプロイするためには、下記の流れに沿う必要があります。(Dockerはインストール済の想定)
アプリケーションのルートディレクトリにDockerfileを作成する。
Linux 又は WSL のターミナルでアプリのルートディレクトリに移動。
アプリケーションの依存関係を Dockerイメージとしてビルドする。
ビルドしたイメージを、Dockerhub にて公開する。(非公開も可)
Render で DockerイメージのURLを指定して必要な設定をする。
無事コンテナが起動すれば、webサービスのデプロイが完了。
Docker image のビルド
まず、前述手順の1~3部分、"Docker image のビルド" を実行します。
イメージのビルドを実行するためには、アプリのルートディレクトリに、
適切に記述された下記のファイルが必要です。
・Dockerfile ・・・ イメージのビルド内容を記述した設計図。
・.dockerignore ・・・ ビルド時に無視するファイル等を指定したもの。
・requirements.txt・・・ Pythonの依存パッケージをリスト化したもの。
◆ Dockerfile
# ベースイメージとしてPython 3.11.8を使用
FROM python:3.11.8
# 必要なパッケージのインストール
RUN apt-get update && \
apt-get install -y \
tesseract-ocr \
tesseract-ocr-eng \
tesseract-ocr-jpn \
libgl1-mesa-glx && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# アプリケーションディレクトリの設定
WORKDIR /app
# 外部依存関係のインストール
COPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txt
# アプリケーションファイルのコピー
COPY . .
# ポート5000の公開
EXPOSE 5000
# 開発環境での実行
CMD ["flask", "run", "--host=0.0.0.0"] Dockerfile は Docker image をビルドする上で中核となる最も重要な部分であり、出来上がるイメージの設計図の部分に該当します。Docker は 、Linux ベースでの依存関係を構築します。Dockerfile に記述されている指示に従って、上から順に依存パッケージをインターネット経由でインストールしていきます。
・最初に Pythonをインストールします。開発環境と同じ v3.11.8 を選択。
・apt-get コマンドにて、必要なパッケージをインストールします。
→ Tesseract-OCR (Linux版) など
・rm -rf コマンドで、パッケージの一時ファイルを削除します。
・アプリのルートディレクトリ (/app) を設定します。
・外部依存関係(=Pythonのライブラリ)をインストールします。
→ 直接記述も可能ですが、今回は requirements.txt から読み込みました。
・COPY . . コマンドで、ローカルのアプリのルートディレクトリのファイル
やフォルダを、/app にコピーします。
→ この時 .dockerignore に記載したファイル・フォルダは除外されます。
・ EXPOSE コマンドで、特定のポートを明示的に公開します。
・最後に、 CMD [ ] コマンドで、このイメージがコンテナとして起動された
際に実行するコマンドを指定します。
→ ["flask", "run"] コマンドは、開発環境として実行するコマンドです。
つまり、このイメージをPCにてコンテナ起動すると、開発環境サーバー
にて起動します。そこで、本番環境では Renderの機能を使って、
本番環境用の実行コマンドに上書きする必要があります。(後述)
◆ .dockerignore
__pycache__/
.git/
.gitignore .dockerignore ファイルは、COPY . . コマンド時に、ルートディレクトリから /app にコピーしたくないものを明示的に記述することで、コピー対象から除外する事が出来ます。
・ 開発時のテストランなどで溜まった pyキャッシュ は、本番環境では不要
なので除外します。
・git 関連のフォルダやファイルは、本番環境では不要なので除外します。
◆ requirements.txt
Flask==3.0.2
Flask-APScheduler==1.13.1
pandas==2.2.1
pillow==10.2.0
pyocr==0.8.5
ultralytics==8.1.34
Werkzeug==3.0.1
pytz
gunicorn requirements.txt は、ビルド時のPython 外部ライブラリ の依存関係を明記しておくもので、"パッケージ名" == "バージョン" の書式で記述します。バージョン指定をしない場合、最新バージョンがインストールされます。
基本的には、アプリ内で import している外部ライブラリを記述します。ただし、"os" や "glob" などの Python標準ライブラリは Python本体に付属しているため、表記する必要はありません。原則、開発環境と同じバージョンを指定する事が重要です。そうしない場合、開発時には見られなかった依存関係に関するエラーが、本番環境で発生するリスクが高まります。
重要!!
PythonのWebアプリを、webサービスとしてデプロイする場合、本番環境では、WSGIサーバー に接続するパッケージが必要になります。
WSGIサーバーは、PythonのWebアプリケーションとWebサーバー間のインターフェースを提供する標準規格です。アプリケーションとサーバー間でのリクエストとレスポンスのやり取りを規定し、異なるWebサーバー上でも同じPythonアプリケーションが動作するようにします。これにより、開発者はWebサーバーの選択に柔軟性を持ち、アプリケーションのポータビリティと互換性が向上します。
WSGI サービスにもいくつかの選択肢がありますが、今回は "Gunicorn" を選択しました。WSGIについての詳細は、こちらの記事が参考になりました。
WSGIサービスパッケージを利用するために、requirements.txt には、 "gunicorn" を忘れず記述します。
◆ ビルド実行
DockerがインストールされているOSのターミナルにて下記コマンドを実行すると、ビルドが開始されます。
cd "アプリのルートディレクトリパス" # アプリのルートへ移動する
docker build --no-cache -t txt_detector:v1.3 .docker build コマンドに、イメージの名前とタグを指定するだけです。
今回の場合、
・txt_detector ・・・ この部分がイメージ名になります。
・v1.3 ・・・ タグ。指定しないと、latest になる。
Dockerfile ほか、全てのファイルが正しく記述されている場合、イメージが正常にビルドされるはずです。今回、 ultralytics が pytorch や cudnnなどの容量が大きい依存パッケージ含んでいたため、時間がかかりました。
Dockerhub へプッシュ
docker tag txt_detector:v1.3 ryosk350/txt_detector:v1.3
docker push ryosk350/txt_detector:v1.3 Dockerhub のアカウントを作成し、ログインしておきます。
docker tag コマンドにて、先ほど作成したイメージにタグ付けをして、
docker push コマンドにて、リモートリポジトリにプッシュします。
※ ryosk350 は私の Docker username です。
基本、Dockerhub のリモートリポジトリは、
”ユーザー名”/"イメージ名":"タグ" という書式になります。
Render へデプロイ
Render にアクセスし会員登録後、右上の New+ ボタンをクリックし、 Web Service を選択し、"Deploy an existing image from a registry" を選択します。次に Image URL の欄に、前述の Dockerhub のリポジトリの URL を
記入し、Next をクリックします。
すると、デプロイ設定の画面になるので、アプリの名前やサーバーの場所などを適宜設定します。
重要!!
前述しましたが、今回のDockerイメージの最終行の CMD [ ] は、開発環境サーバーの実行となってます。したがって、本番環境ではこの部分を上書きする必要があります。Render にはコンテナ起動時のコマンドを上書きする設定項目があります。"Add an optional command to override the Docker CMD" などの説明がある設定欄です。そこへ、下記のコマンドを記載します。
gunicorn -w 4 -b :5000 app:app重要なのは 、先頭の "gunicorn" です。WSGIサーバーで "app" を起動する事を指定しています。
その他
-w 4 ・・・ ワーカー数の制限で、任意です。
-b :5000 ・・・ ポート5000でリクエストを待ち受けます。
EXPOSE 5000 なので、5000を指定します。
app:app ・・・ この部分はアプリケーションの位置を指定します。最初の
app は Gunicornが読み込むPythonファイルの名前で、2つ目
の app はそのファイル内でWSGIアプリケーション
オブジェクトを指す変数の名前です。
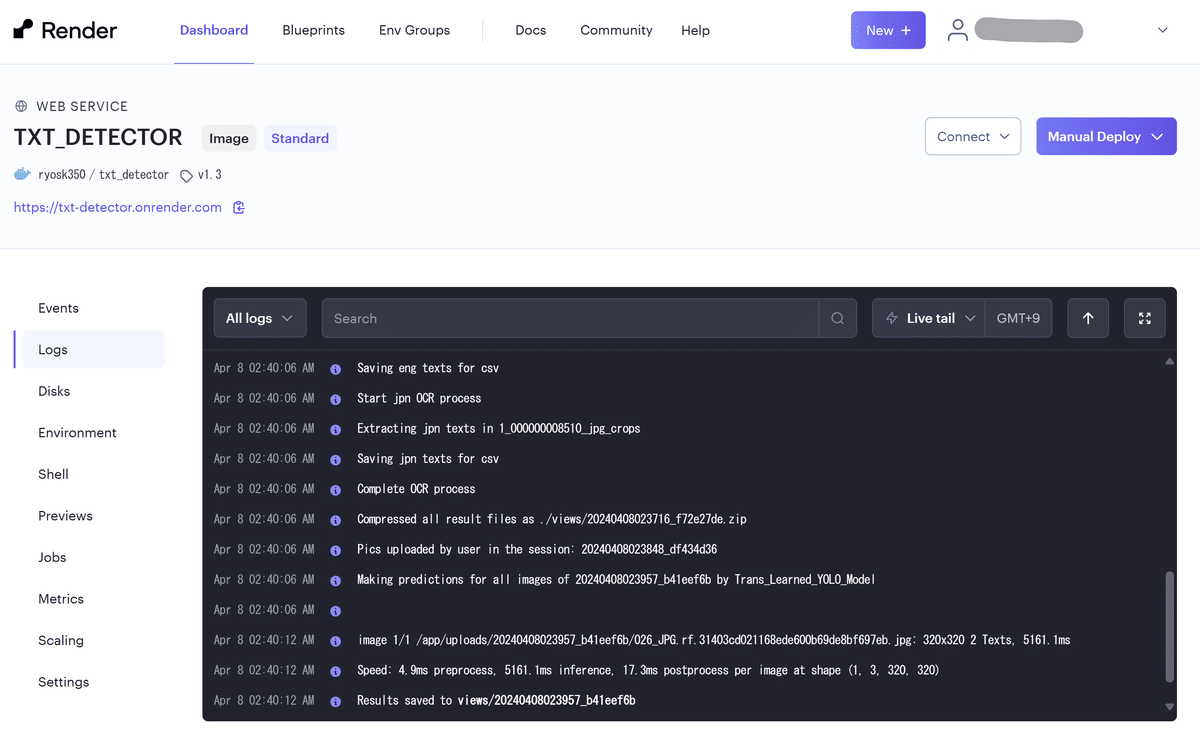
ここまでを全て正常に進行すれば、"Your Web Service LIVE!!" が表示され、無事にデプロイが完了するはずです。Render のマイページのダッシュボードから、ログを監視できるようになっています。
まとめ
所感
PythonベースのWebアプリ制作の流れを掴む事ができた。
プログラミングとデータサイエンスの基礎的な能力が身に付いた。
Git や Docker などの開発ツールの使用に慣れることができた。
反省点
Dockerイメージの容量が 7GB と非常に大きくなった。これは推論用の外部ライブラリとして ultralytics を丸々 import している事が原因であり、解決のためには、yolov9 の githubリポジトリ から推論部分を抜き出し、必要部分のみの実装とする必要がある。ただしそれには関連する依存関係を全て読み解く必要があり、難易度は高い。
本番環境での処理が重い。特に、OCRの日本語文字抽出処理で重たくなり、場合によってはメモリ不足でサーバーがダウンする。開発環境ではリソースを独占できるため、この問題には本番環境へデプロイするまで、全く気がつかなかった。
今後の展望
モデルの精度向上・・・教師データを充実させ、再学習。
2クラス部類にする・・・英語と日本語に部類する、など。
より軽い処理になるようにバックエンド全体を見直す。
最後に
プログラミング初心者の状態からWebアプリ制作を達成したことで、自信に繋がりました。今後も色々な課題に積極的にチャレンジして、もっとデジタルスキルを向上させたいと思います。