
StableDiffusionのモデルサイズ削減を試してみる(1)

先日の記事の続きです。
先に結論から言うと、現時点では失敗してます。
PCAで分解してみる
FeedForward層、後ろ側のLinear直前で流れてくるテンソルを採取して、PCAで分解してみました。

各ブロックで傾向が変わるかと思ったのですが、案外ブロック毎の差は小さいようでした。
この感じですと、次元を 25% くらいまで落としても 90% 程度の精度は確保出来そうです。
実際には活性化関数が挟まるので、これより悪い状況から始まると思われるのですが、学習で挽回してくれることを期待します。
実験ということもあり、ちょっと大胆に 5120次元を 960次元 まで削減してみます。
(なお、チャンネル数の大きい IN, IN8, MID, OUT3, OUT4, OUT5 を対象としています)
なお、PCA計算時に5120x5120の行列の固有値/固有ベクトルを求まる必要があるのですが、そこそこ重い処理で1ブロックあたり 1分弱かかりました。
まあ、そこそこ良い状態から学習始められるので、
テセウスのUNet
Bert-of-theseus と似たようなことができるように、ブロックを切り替えられるようにUNetを改造してみます。
Diffusersの ‘StableDiffusionPipeline‘ で SD1.5系のチェックポイントをロードして、UNetの一部を差し替えるようにします。
元UNetのFeedForwardから、重みをコピーしたTeacherと、次元削減するような行列を挟んだStudentを作成し、これらを切り替え可能にしておきます。
また、Teacherは 入力と出力をキャッシュしておき、Studentの学習に使えるようにしておきます。
まずはブロックごとに学習
いきなりテセウス学習(と呼ぶことにします)を行わず、各ブロックの学習を行う事にします。
オプティマイザー、スケジューラは AdaFactorを使うことにしました。
(Lr追い込むのが面倒だったので)
損失関数はMSELossを選択しました。

200ステップ(1枚画像を32stepsで生成して、そのときのIn/Outで学習)ほど回してみましたが、80ステップあたりでLossが横這いになってますね。
FeedForwardのみ学習させているので、学習速度は速い(6sec/step程度)
ですね。
テセウス学習開始
どの程度の速度で Student ブロックの採用率を増やすべきか想像つかなかったのですが、とりあえず 200ステップで全ブロック差し替えになるようにスケジュールしてみます。
すべてTeacherのUNetで画像生成。そのときのUNetのIn/Outを利用して Studentを含む UNetを学習する。という感じですね。
また、TeacherのみのUNetを通す際に 各ブロックの In/Outをキャッシュしておくこともできますので、前述のブロックごとの学習を併用してみることにします。
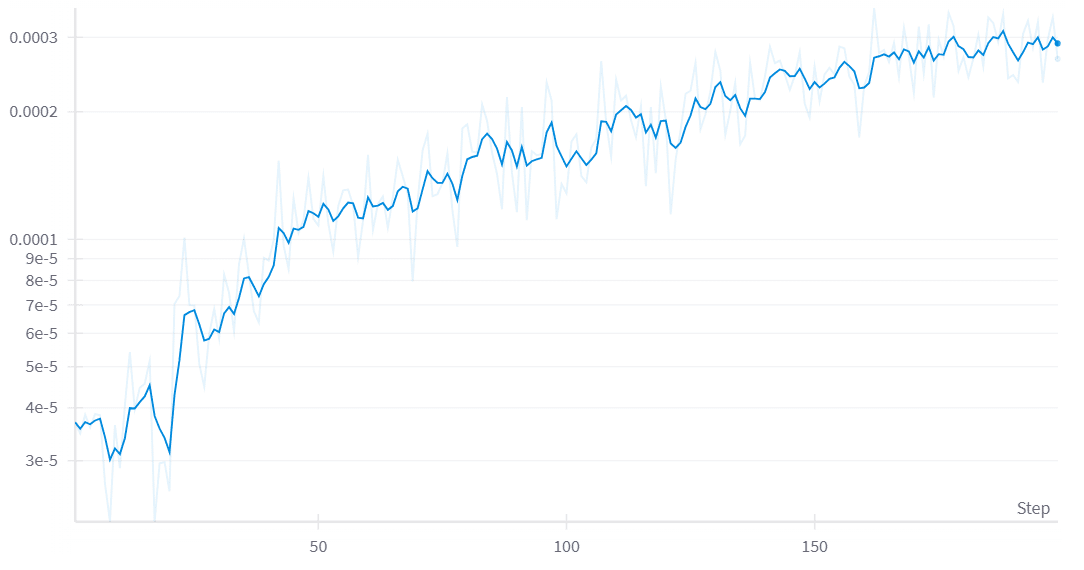
ステップが進むごとに Student ブロックの採用率が高くなるので、Lossが上昇するという、ちょっとかわったグラフになりました。
差し替え完了後もさらに学習させる
段階的な差し替え完了後も、200ステップほどさらに学習させます

Lossはあまり変化しませんね。
LoRA学習やったことがある人ならわかるかと思うのですが、Stable Diffusion の学習って、Lossが下がらないケースが多いんですよね……
画像を生成してみる
ええと、結論から言えば現時点では失敗です。
出力画像の品質が……といえるレベルまで達していません。
失敗した要因は色々実験してみないとわからないですが、
・テセウス学習で、Student採用率を上げるタイミングが早すぎた
・5120→960 は削減しすぎた
・学習可能なブロックが少なかった
(FeedForward以外も学習する)
あたりではないかなぁ……と予想してます。
生成結果
以下は生成画像載せているだけです。
注意:グロテスクに感じる可能性がありますので、苦手な方はここで閉じてください。
次元削減を適用するようなカスタムノードは作っていませんので、Diffusers で生成してみます

チェックポイントは自分用に色々と混ぜたヤツなんですが、マージ比率とかメモしてなかったので再現できないヤツです。
(マージモデル公開している人たちって凄いですね……)
以下、Promptとseedは同一で生成していきます。

これ……なんでしょうかね。

なんかメカっぽい質感になってますね……

ええと……人、ですね。
人と認識できるレベルまで持ち直しました。