【Python初心者】機械学習を使ったピンポイント気温予測

こんにちは。Note初投稿、Python副業化を目論み中の一般男性Aです。
現在、Pythonのデータ分析について勉強中でして、そのアウトプットととして本記事を投稿しました。
初心者ですので語句の間違い、コードの間違い多数あるかと思います。同じ初学者の方は鵜呑みにせず、また、熟練者の方はご指摘いただけますと幸いです。
目的
自分の居住区(京都)の来月の気温について、モデルを構築し、予測する。
実行環境
OS:Windows10
Python 3.7.11
Google Colaboratory
Chrome
(1) データセットの準備
今回使用した分析データは下記の気象庁サイトからダウンロードしました。
データは以下の内容を取得しました。
・地点:京都
・項目:月別値 「月別平均気温」「月最高気温」「月最低気温」
・期間:1872年9月~2021年9月(約150年)
CSVの中身は下のような感じです。

なお、CSVファイルの名前は”data.csv"です。
(2) データクレンジング
このままの形式では気温予測できないため、必要なデータだけ抽出します。
7行目から抜き出したい(1~6行目は使わない)ため、"skiprows"を指定します。
import pandas as pd
df = pd.read_csv("data.csv", header=None, skiprows=6)
#"data.csv"の読み込み。1~6行目をスキップする。また、「品質情報」や「均質番号」といったノイズデータが存在しているので、欲しいデータの列のみ抽出します。このような時は"usecols"を指定します。今回は、1, 4, 7列目が必要なデータです。
df = pd.read_csv("data.csv", header=None, skiprows=6, usecols=[0,1,4,7])
#"data.csv"の読み込み。1~6行目をスキップする。1,4,7列目のみ抜き出す。列の名前も付けておきましょう。"df.columns"に列数と同じ長さのリストを代入することで設定できます。
df.columns = ["date","temp_max", "temp_min", "temp_ave"]
df
#現在のdfの中身
date temp_max temp_min temp_ave
0 1872/9 NaN NaN NaN
1 1872/10 NaN NaN NaN
2 1872/11 NaN NaN NaN
3 1872/12 NaN NaN NaN
4 1873/1 NaN NaN NaN
... ... ... ... ...
1784 2021/5 30.2 8.8 19.4
1785 2021/6 33.6 15.2 23.9
1786 2021/7 37.3 21.6 27.9
1787 2021/8 38.7 21.5 27.7
1788 2021/9 31.8 19.9 24.9
1789 rows × 4 columns続いて欠損値対応です。リトワイズ法で欠損値を含む行を全て削除します。
df = df.dropna()
#欠損値を含む行の削除
df
#現在のdfの中身
date temp_max temp_min temp_ave
98 1880/11 22.4 -1.6 8.2
99 1880/12 12.8 -8.3 2.4
100 1881/1 11.3 -9.2 0.5
101 1881/2 16.3 -7.8 2.5
102 1881/3 17.2 -6.1 4.7
... ... ... ... ...
1784 2021/5 30.2 8.8 19.4
1785 2021/6 33.6 15.2 23.9
1786 2021/7 37.3 21.6 27.9
1787 2021/8 38.7 21.5 27.7
1788 2021/9 31.8 19.9 24.9
1691 rows × 4 columnsNaN表記でデータが無かった行を削除することに成功しました。
以上でデータの前処理は終了です。
(3) データのグラフ化
時系列データでは視覚化することが非常に大切です。
Pythonのmatplotlibを用いて前処理をしたデータをグラフ化してみます。
import matplotlib.pyplot as plt
X=df["date"]
y_max=df["temp_max"]
y_min=df["temp_min"]
y_ave=df["temp_ave"]
plt.title("Kyoto_temp.")
plt.xlabel("date")
plt.ylabel("temp.")
plt.plot(X, y_max, color="r") #最高気温は赤色でプロット
plt.plot(X, y_min, color="b") #最低気温は青色でプロット
plt.plot(X, y_ave, color="k") #平均気温は黒色でプロット
plt.legend(["temp_max", "temp_min", "temp_ave"]) #グラフの凡例の追加
plt.show()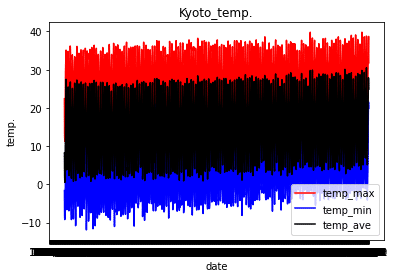
データ数が多すぎてよく見えないグラフになってしまいました。
しかし、この150年でじわじわと気温が上昇していることがわかりました。
また、最高気温や平均気温よりも最低気温の方が上昇する傾きが急なように見えます。どちらかと言うと夏(最高気温)がどんどん暑くなっているイメージでしたので、少し意外な結果です。
(4) 分析の方向性
ここで改めて分析の方向性を決めます。
先ほどのグラフ化によって今回のデータには正のトレンドがあることがわかりました。
さらに気温データですので周期変動(季節変動)があることもわかっています。
これらのことから、まずは原系列からトレンドと季節変動を取り除き、時系列データを定常化した上で分析を実行し、定常化したデータのモデルを構築することを目指します。
その後にトレンドと季節変動を合成して原系列のモデルを構築します。
今回は、季節周期を持つ時系列データに対応したSARIMAモデルを利用してみます。
パラメーターを探索する前にもう少しデータを整えておきます。
時間情報("date"のデータ)をインデックスにすることで、この後の処理で扱いやすくなります。
index = pd.date_range("1880-11-30", "2021-09-30", freq="M") #1
df.index = index #2
del df["date"] #31. pd.date_range("開始時", "終了時", freq="間隔")を使用して時間情報を用意します。
2. 用意した時間情報をデータのインデックスに指定します。
3. 元のデータの時間情報("date")を削除します。
何度かこの操作をしましたが、個人的には3の削除を忘れることが多かったです。適宜データを出力して、現在のデータがどうなっているのかを確認する必要があると感じました。
(5) パラメーター決定
SARIMAモデルには以下のパラメーターがあります。
(p, d, q)
(sp, sd, sq, s)
Pythonには自動で最適化してくれる機能は無いとのことですので、ベイズ情報量基準(BIC)でパラメーターを探してくれるプログラムを自分で書きます。
今回のデータは気温ですので月ごとのデータに季節性があります。そのため、周期sは12としています。
なお、実装の都合上、今回モデル化するのは「平均気温」("temp_ave")のみに絞りました。
import warnings
import itertools
import numpy as np
import statsmodels.api as sm
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s)
for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
#実装の都合上、平均気温のみを引数に与える
selectparameter(df['temp_ave'], 12)#出力結果
[(1, 1, 1), (0, 1, 1, 12), 4926.728480778194]無事に最適なパラメーターを得ることができました。
(6) モデルの構築と予測
ついにSARIMAモデルの構築です。パラメーターは先ほど得た最適値を使用しています。
SARIMA_temp_ave = sm.tsa.statespace.SARIMAX(df["temp_ave"],order=(1, 1, 1),seasonal_order=(0, 1, 1, 12)).fit()モデルが構築されたら予測してみたくなるのが人間です。
モデル名.predict("予測開始時", "予測終了時")を使用することで簡単に予測ができます。
ただし注意点として、"予測開始時"は元の時系列データに含まれていないといけません。今回の場合ですと、2021-09-30以前である必要があります。ここでは2020-01-31から2022-09-30(1年後)までを予測してみました。
pred = SARIMA_temp_ave.predict("2020-01-31", "2022-09-30")
plt.xlabel("date")
plt.ylabel("Average temp.[℃]")
plt.show()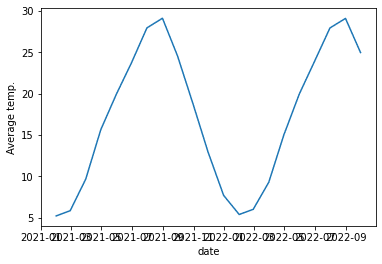
最後に、予測データと実際データを比較してみます。
pred = SARIMA_temp_ave.predict("2020-01-31", "2022-09-30")
plt.plot(pred, color="r")
plt.plot(df["temp_ave"]["2016-01-31": "2021-09-30"])
plt.xlabel("date")
plt.ylabel("Average temp.[℃]")
plt.show()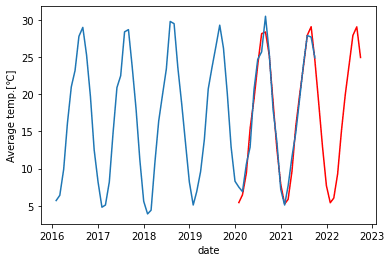
2行目で予測データの表示、3行目で実際データの表示を行っています。実際データを全て表示するとデータ数が多くグラフが見にくいため、["2016-01-31": "2021-09-30"]で抽出する範囲を指定しています。
結果を見て、以下の所感を得ました。
・1年間での気温の上下は上手く捉えることができている。
・最大値、最小値は少しずれている。
季節変動を予測するのには適していそうだと考えます。今年はどれくらいのペースで寒くなっていくのか?といったことを予測できそうです。
終わりに
学習した内容を用いて、データの準備から予測までを初めて一通り経験しました。
実際に自分でコードを記載すると上手く動かない部分が多く、エラーのチェックが大半の時間を占めました。
しかし、学習の復習にもなりましたし、とても良い勉強になったと感じています。
今回BICの値については議論しませんでしたが、かなり大きい値でしたので、もっと最適なパラメーターがあるのかもしれません。また、「最高気温」や「最低気温」などのデータも組み合わせるとより幅広い予測ができそうです。
一つプログラミングを行うと、いろいろとやりたいことが湧き出てきます。これからより一層勉強を頑張ろうと思っています。
最後までお読みいただきありがとうございました。