
【AlgoStation】AIで過剰最適化を検出するアプリ #RT無料 #MT5 #AI

🔶トレーダーの永遠の課題
バックテストで素晴らしい成績を出すEAなのに、実際のトレードではまったく利益が出ない... その悩みの原因は「過剰最適化」かもしれません。AlgoStationは、私たちEAトレーダーが直面する最も深刻な課題の一つである過剰最適化という問題を、AIの力で解決させることに挑戦します。

🔶過剰最適化とは
過剰最適化(オーバーフィッティング)は、EAが特定期間のデータにピッタリ合いすぎてしまう現象です。 これにより以下の現象が発生します。
テスト期間では驚異的な成績😍
しかし未来のデータでは全く機能しない😭
ほとんどのEAがこの問題に直面している😅
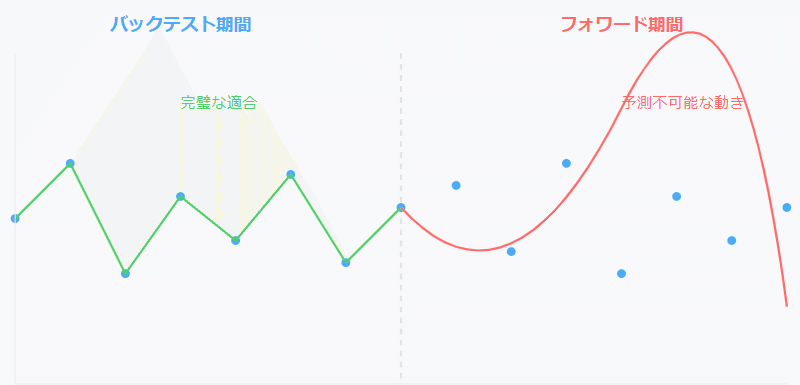
🔶なぜ従来の方法では解決できないのか
フォワードテストを使用してのEAの評価には限界があります。
バックテストとフォワードテスト両者の結果が良好なパラメーターはすでにフォワード期間においても過剰最適化を起こしている可能性が高く、結果として全期間で最適化を取っているにすぎないのです。
※ここでいうフォワードテストとはテスターを使用したフォワードテストのことです。

🔶人間の認知の限界
パラメーターと結果の関係性を見つけようと3Dグラフを見ても、4次元以上のパラメーターの関係性は把握しきれないですし、そもそもノイズでよくなったのか、トレードの本質を捉えているかの区別も困難です🤷♂️
直感的な判断では限界があります😅


🔶AlgoStationを使用したアプローチ
検出原理
パラメーターと損益の関係性を分析
ノイズと本質的なパターンを明確に区別
人間には把握できない複雑(多次元)なパターンを検出

具体的な機能
CSVの読み込み
選択したパラメーター(特徴量)と結果(目的変数)を使用して機械学習
全パターンの予測値を出力(結果CSVのPredict列)
実際の結果と予測値の乖離から過剰最適化を検出(結果CSVのOrverfitting列)
結果をCSVとして保存

予測と逆予測
パラメーターから結果を予測はもちろん、結果からパラメーターを逆予測することも可能です🔁
例えばドローダウンを特徴量として、特定のパラメーターを目的変数に設定すると、ドローダウンを抑えたいならそのパラメーターをその値にしたらいいかを予測することができます

活用シーン
眠っているEAの復活😪
無料EAの性能最大化🆓
新規EA開発時のパラメーター調整🆕
既存EAの性能改善👷♂️
パラメーター調整における時間と労力の大幅削減⏳

🔶使用方法
使用方法の一例を紹介します。単純な教師あり学習なので、工夫次第では別の用途で使用できるかもしれません。
①アプリ起動
インストール方法は最下部です。

②ログイン画面でユーザーID入力
ユーザー登録方法は最下部です。
③AI過剰最適化チェックボタンをクリック
今後AI関係のアプリとして機能追加を予定しています。
④最適化CSV作成
CSVはフォワードテストを含めた「先行結果」タブを保存したXMLをCSVとして保存を推奨。

エクセルファイルを以下の手順でCSVとして保存
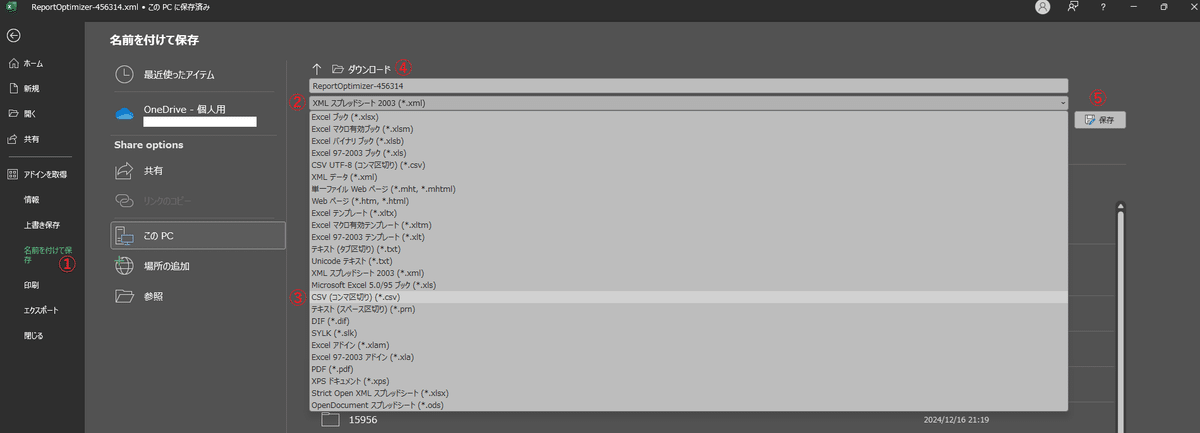
予測の精度を高めるために
①サンプル数が少ないとそもそも統計がうまく取れないため、「取引回数」「パラメーター数」「最適化ステップ数」は多いほうがいい。
②フォワードテストは1/2にしておくとバックテストとフォワードの結果が同等になっているかが評価でき便利
③CSV中の異常値を学習させると予測がうまくいかないことがある。
④すべての結果が正常値でも高安値の5~10%は異常値として学習させない方が無難。
上記を考慮してCSVの作成&前処理をすることを推奨します。
⑤CSV選択→読込み開始
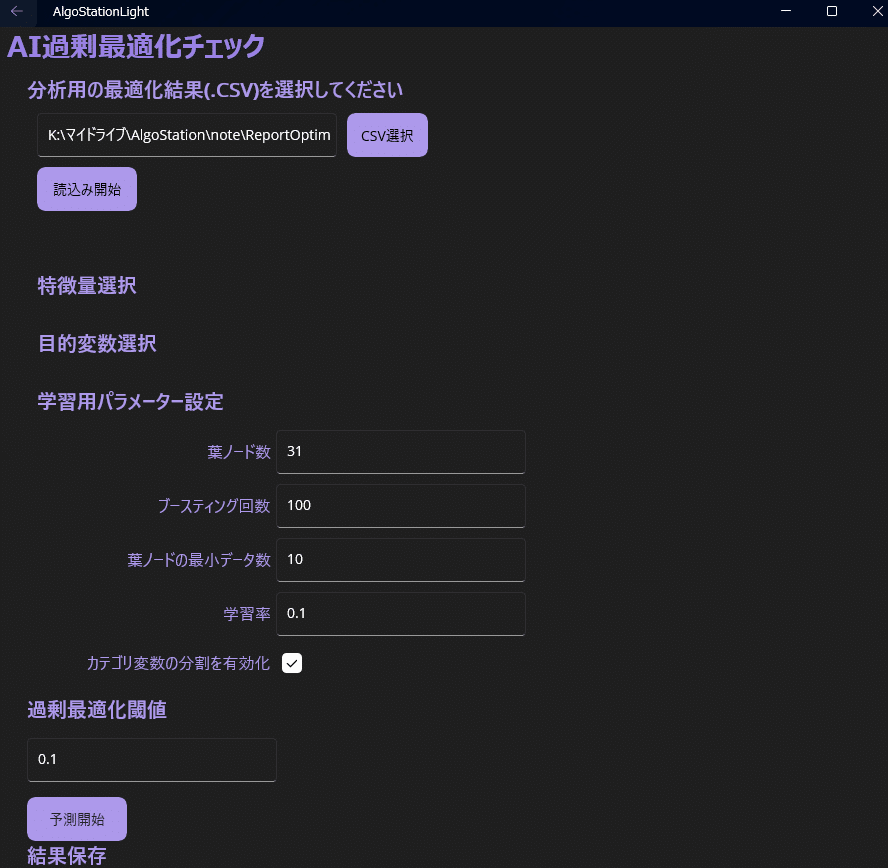
⑥特徴量選択
読込みが完了すると特徴量選択にチェックボックスと各種項目が出現します。これはCSVのヘッダーをそのまま読み込んでいるためです。特徴量として設定する「EAのパラメーター変数名」をすべて選択してください。
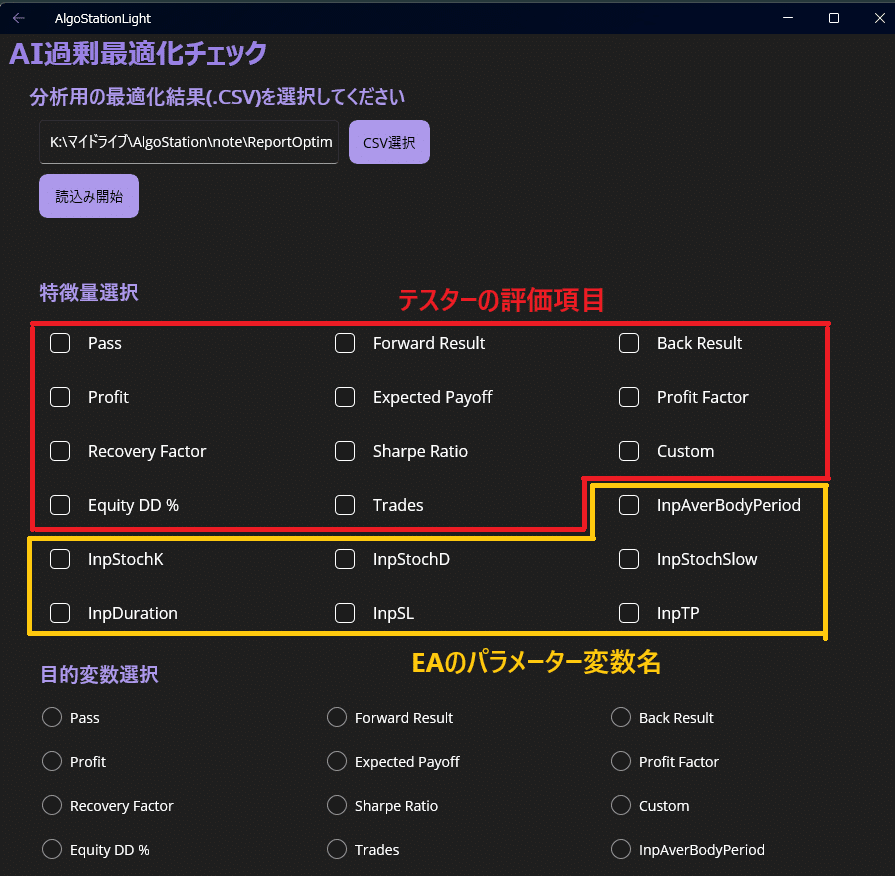
⑦目的変数選択
「Back Result」を選択します。

⑧学習用パラメーター設定
学習用パラメーターを設定します。
パラメーターはLightGBMのパラメーターです、お好みに設定して使用してください。基本的にはデフォルト値で使用します。
⑨予測開始
「過剰最適化閾値」は予測結果と実際の結果の乖離がどの程度あった場合にオーバーフィッティングとするかの数値です。後ほど最適な値に調整しますので、ここでは少し大きめの0.1(10%)でOKです。
「予測開始」を押してください。
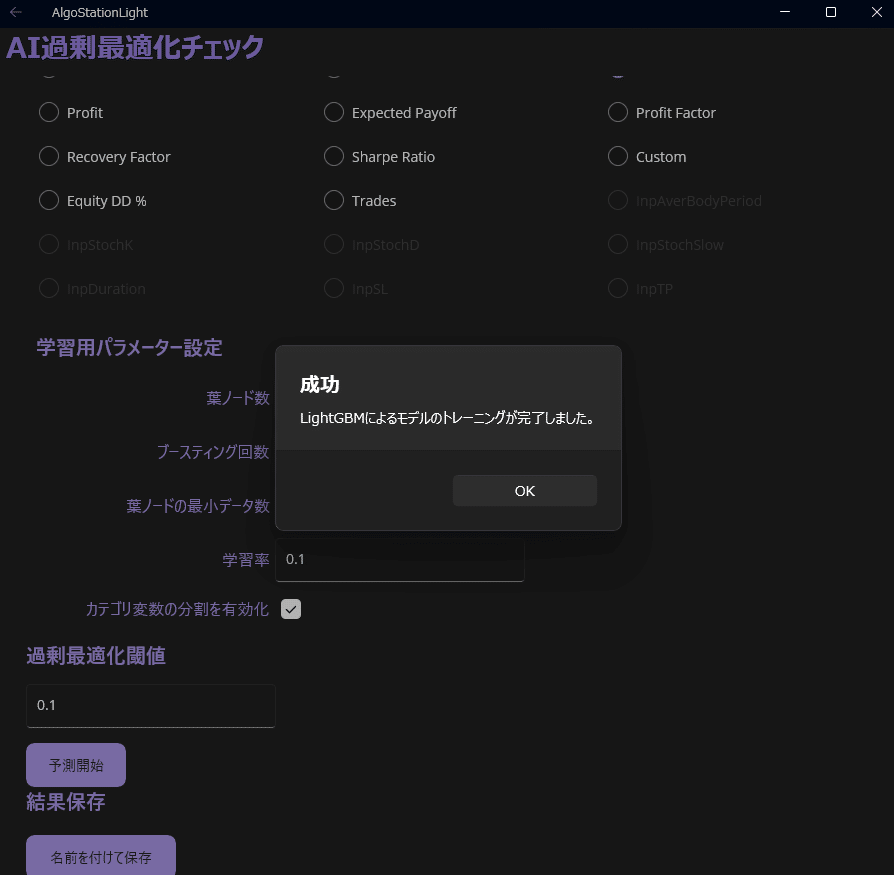
⑩結果保存
「名前を付けて保存」を押してCSVを保存します。
CSVの「Predict」と「Overfitting」の名前を変更すると、再度このCSVを学習に使用して、別の予測値を算出することも可能です。
複数の項目の予測値を算出してみるのもいいかと思います。
⑪過剰最適化閾値の検討
0.001程度でも十分です。
この値は実際に結果を保存して以下の手順でグラフを確認して決定してください。
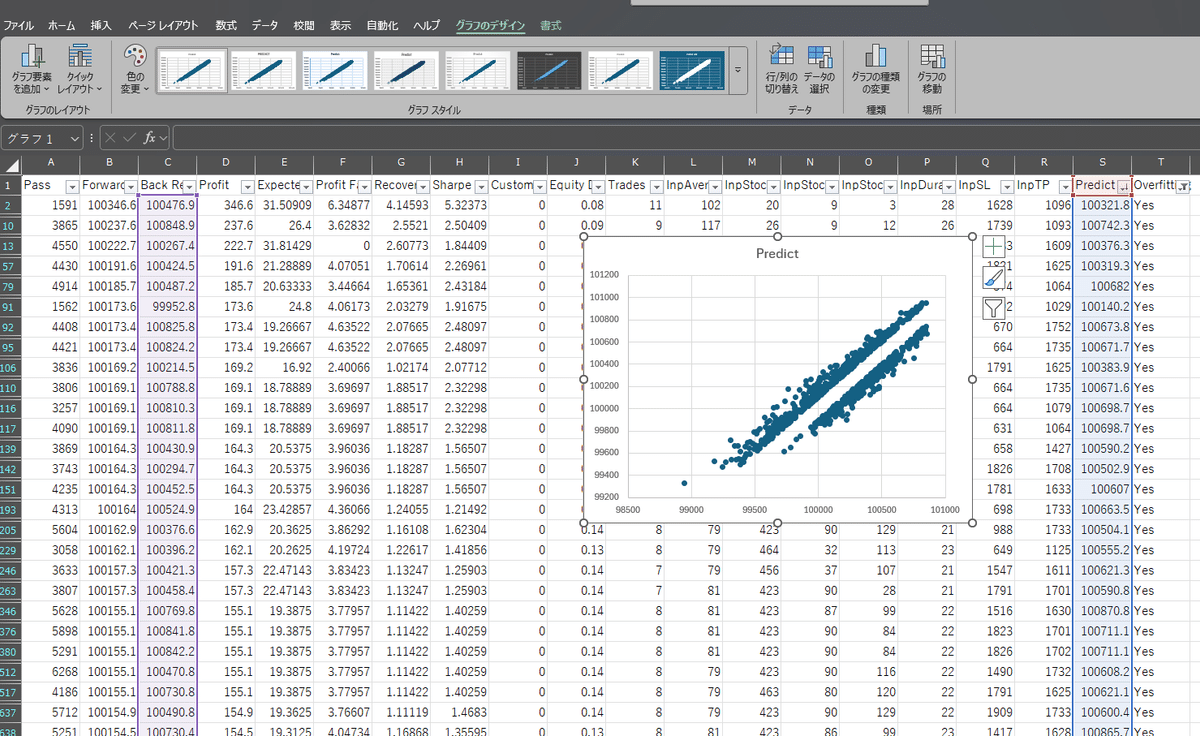
1.フィルターを適用し、「Overfitting」がYesの項目を表示
2.「Buck Result」列と「Predict」列を選択して散布図作成
3.乖離しているデータが表示され乖離してないデータがどの範囲になっているか可視化できる
⑫パラメーターの決定
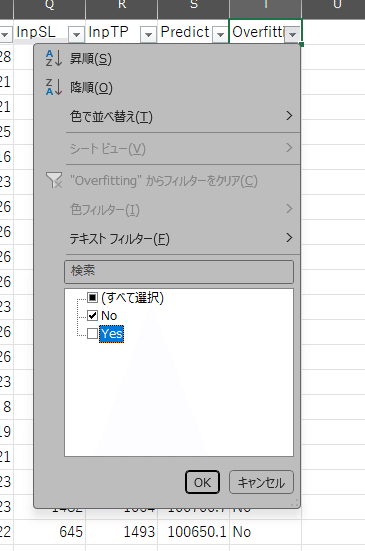
CSVを開いたらヘッダー行を選択した状態でフィルターを適用させます。

「Overfitting」がNoの行を表示させます
「Predict」を降順に並び替えて、結果が高い行を上部に表示させます。
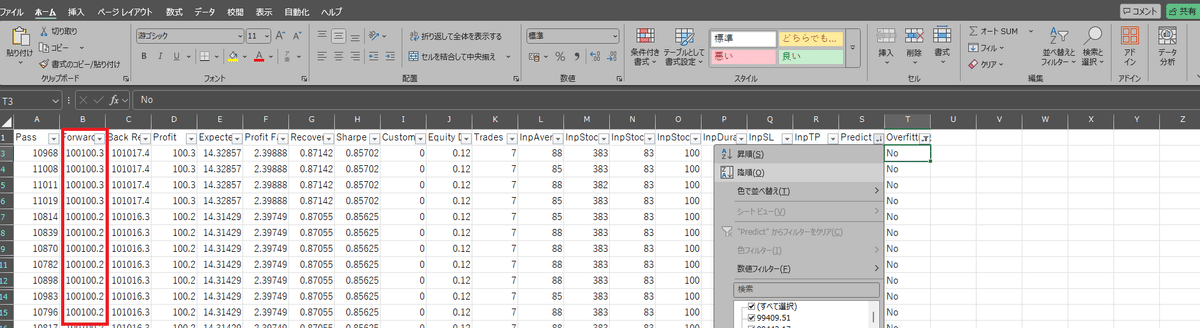
この上部のパラメーターでフォワードの結果を確認して、良好であれば正しい性能を有したパラメーターを選択できていることになります。
応用発展のために
損益はOverfitしてないけど、DDはOverfitしてるという場合も考えられます。このプロセスを繰り返し、次にDDの予測値を出力させたりパラメーターを絞っていくといいと思います。
また反対に結果(損益、DD、PF、RF、SF)から特定のパラメーターの予測値を出力したりも可能です。
🔶ご案内
✨業界唯一のAI×自動売買のプログラミング教室
✨初心者から上級者までを対象とした動画・教材・サンプルコード
✨トータルコンテンツ数50個以上
✨生成AI連携・ディープラーニング・強化学習
✨アビトラ・コピトレ・おしゃべりインジなどユニークなソースコードも満載
✨コンテンツ随時追加中!最近はWonderful Mの全ソースコードも公開しています!
noteで記事を書きました!この投稿をリポストするとお得に記事を読むことができます。
— ワン🐕AIの個人開発ガチ勢 (@wonderfulfxlife) December 25, 2024
【MT5】Wonderful M #28通貨 #AI | ワン('ω')FXフリーランス @wonderfulfxlife #note https://t.co/CcVbrN5EwE
一緒にMQLやAIについて勉強しませんか😊
詳しくはこちら👇👇
ここから先は
この記事が気に入ったらチップで応援してみませんか?