
bitmex_websocketを10倍高速化して遅延をなくす!

更新報告:2018/4/23 tuned_bitmex_websocket.pyのimport文に余計なモジュールが入っていたので、削除しました(^^;
使用しようとしてうまくいかなかった方は、もう一度ダウンロードして差し替えてみてください。すみません!
こんばんは、皆さん。ドテドテっと儲かってらっしゃいますでしょうか。bot&トレード初心者のモッチオです。
前回は公式ライブラリと環境特有の問題とはいえ、情報に遅延のあるライブラリを紹介してしまい、すみませんでした!
今回、そのライブラリ(しかもBitMEX公式)を高速にチューンナップしたコードを紹介させていただきます。また、どうやってコードの高速化を行っていったかについても、コードの解説として説明しちゃいます。
ご使用のbotやpythonコードの動作がどうも遅すぎる、改善したい、、、というときに参考にしていただければ、幸いです!
それでは早速、チューンナップ版bitmex_websocketのコードです!
既存ライブラリに修正を加えた形なので、無茶苦茶長いです。なのでダウンロードできるようにしました。解凍して、組み込みたいbotと同一のディレクトリ内に配置してください
zipファイルの中には、bitmex_websocket.pyを改良した「tuned_bitmex_websocket.py」と、「util」フォルダとが入っています。両方を、組み込むbotと同一のディレクトリに配置してください。
使いかたです!
前回で紹介したbitmex_websocketを使用するコードに修正を加えた者を通して解説します。まずはそのコードをご覧ください。
#!/usr/bin/python3
from datetime import datetime as dt
import time
import pytz
#from bitmex_websocket import BitMEXWebsocket
from tuned_bitmex_websocket import BitMEXWebsocket
# タイムゾーン取得
tokyo_tz = pytz.timezone('Asia/Tokyo')
try:
# WebSocket API接続用オブジェクトを生成
ws = BitMEXWebsocket(endpoint="wss://www.bitmex.com/realtime", symbol="XBTUSD", api_key=’APIKEY’, api_secret='SECRET')
# instrumentメソッドを一度呼び出さないとエラーを吐くので追加(内部的にget_tickerがこの情報を使用するため)
ws.get_instrument()
# Socketの接続が活きている限り処理を続けます
while ws.ws.sock.connected :
now = dt.now().strftime('%Y-%m-%d %H:%M:%S')
#now = tokyotz.localize(dt.now()).strftime('%Y-%m-%d %H:%M:%S')
# Ticker情報を取得!
tick = ws.get_ticker()
# ポジション情報を取得!(get_position()はありませんが、プロパティ「data」の中にちゃんと入ってるんですね)
# ただし、ポジションが一つもない場合、'position'というデータ自体がありませんので、そこを考慮します
if 'position' in ws.data:
positions = ws.data['position']
else:
positions = []
# 取得したポジション情報には現在保有している全ての通貨セットのポジションが含まれますので、'XBTUSD'でフィルタリングします
positions = [position for position in positions if position['symbol'] == 'XBTUSD']
# コンソールに表示してみます
print("%s : ticker : %s" % (now, ws.data['trade'][-1]))
#print(ws.timemark)
for position in positions:
print("%s : position : synbol %s : qty %s" % (now, position['symbol'], position['currentQty']))
# 0.1秒ごとに繰り返します!
time.sleep(0.1)
except Exception as e:
print(e)
ws.exit()
ほとんど変わってないですね!では解説します!
使用方法解説
といっても使う側では変化を意識するところはほとんどないです。既存の機能を一切壊さないように気を付けて改修しました!なので、
import文を変更するだけです!
#from bitmex_websocket import BitMEXWebsocket
from tuned_bitmex_websocket import BitMEXWebsocketつぎに、BitMEXのライブラリのどこをどう改修したか、解説させていただきます。
理解していただきやすくするため、まっこと手前味噌!なのですが、いかにして遅延箇所を特定し、改善していったかを織り交ぜならが、解説を試みたいと思います。永くなりますので、興味のある方のみで結構です。よろしければどうぞお付き合いくださいませ!
改善方法解説(どこを改修したか)
改修したいプログラムがある場合、そのどこを改修するかということは、とても、とても重要なことです。特に改善したい内容が、「挙動が〇〇だが、今後は〇〇に変え、〇〇の場合は〇〇を行うようにしたい」などの処理内容を変更するものだったりすると、そのプログラムに対する深い理解が要求されてきてしまいます。
しかし、今回は改善したい内容が「速度を改善したい」という割と単純で確認しやすいことなので、ぐっと話が単純になります。処理の内容がどうこうというよりも時間がかかっているところを直せばよいからです。
※※!!話が単純になるだけであって、簡単だとは言ってませんので夜露死苦!!※※
処理時間がかかりすぎているところを特定するため、各処理の処理時間を計測します。この計測に凄く役に立つのが・・・time.time()と連想配列です!
まず、処理にかかった時間を記録しておくため、連想配列を一つ作っておきます。
import time # time()を使用するためにインポート
timemark = {} # 計測した時間を累計するため、連想配列を作っておく
次に処理時間を図りたい箇所を囲むように、start = time.time()とend =time.time()で現在時間を取得します。(この関数はUTC秒数を、小数点以下も含めて返してくれます)endからstartを引いたものが、処理にかかった時間となるので、これを連想配列に格納していきます。
演算子に+=を使って、同じ処理の計測では累計していくようにします。
これは処理時間が「たまたま早かった・遅かった」を排除していくためです。
start = time.time()
・・・・時間を計りたい処理
end = time.time()
timemark['hoge'] += end - start # 処理にかかった時間が累計されていく連想配列には、計測した処理時間がどんどんたまっていく、という塩梅です。
print(timemark) # { 'hoge': 3.14, 'moge': 1.257, ....}と、計測したい箇所でかかった時間の累計が一覧で確認できるbitmex_websocketの処理速度を計測!
前置きが長くなってしまいました。いよいよbitmex_websoketの処理でどこが遅かったをお伝えしましょう。
時間を計測する処理を仕込んだのは、dataプロパティを更新するメッセージを受け取って処理する「__on_message()」関数のなかです。
この中には、「partial」「insert」「update」「delete」と、4種類のメッセージを処理するための分岐がありました。このうち、どれが、どれだけの時間を食っているのか?結果はこの通り。

ちょっと、わかりにくいですね。
partialが0.000009秒、insertが約0.00685秒、updateが110,045秒、deleteが0.5296秒ほどかかっています。
明らかにupdateが遅いですね!!
このupdateの処理部分で、findItemByKeys()という関数が使用されています。
※可読性向上のため、インデントを調整してあります
elif action == 'update':
self.logger.debug('%s: updating %s' % (table, message['data']))
# Locate the item in the collection and update it.
for updateData in message['data']:
item = findItemByKeys(self.keys[table], self.data[table], updateData)
if not item:
return # No item found to update. Could happen before push
item.update(updateData)
# Remove cancelled / filled orders
if table == 'order' and item['leavesQty'] <= 0:
self.data[table].remove(item)updateデータがある度に実行されている・・・
これがちょっと怪しいので、この関数の処理時間も実は一緒に諮っていました。ちなみにこの関数の処理時間合計は109.864秒でした。
ほとんど全部こいつのせいですね!!
この関数、deleteの処理でも呼ばれているのですが、deleteは実行される頻度が少ないので、あまり処理時間が膨らんでいないものと思われます。
なので、findItemByKeys()を高速に動作させるように改修しました!
改善方法解説(その2:いかに改善したか)
findItemByKeys()の中身を見てみましょう。
def findItemByKeys(keys, table, matchData):
for item in table:
matched = True
for key in keys:
if item[key] != matchData[key]:
matched = False
if matched:
return itemまず関数名に注目です。「アイテムをキーから見つけます」になってますね。
関数が受け取る引数から説明すると、keysにはアイテムを特定するために必要な項目名が入っています("symbol","id","side")みたいな具合ですね。このkeysの項目をもとに、matchDataと同一のキーを持つデータをtableから探して返却する関数のようですね。
for文のロジックを見てみると、table内のデータを先頭から1件1件づつ取り出して、matchDataとキー項目が同一のデータを探しているようです。
データを探してねって要求が来るたびに先頭から探す・・・・
遅そうですね!
※このbitmex_websocket.pyは、BitMEXがWebSocketAPIの利用方法を利用者に伝えるためのものなので、多少速度が遅くても、やっていることがわかりやすい、こうした素直な処理ロジックが記述されている方が正解という見方があります。このコードはこのコードで正解です。
ズバリ!この関数でかかっている110秒・・・100倍早くできます!
その代わり、ちょっとした準備が必要で、その他のinsert・deleteなどの処理が遅くなる可能性がありますが、こうした場合に昔から使われている方法があります。インデックスを作ります。
tableは配列ですので、何番目に対象のデータが入っているかがわかれば、すぐにデータを取り出せます。なので、あらかじめkeyとなる項目の値に対して、tableの何番目にデータがあるよ、という辞書を作成しておけば、辞書をめくればすぐにどこにあるかがわかり、データを取り出してお返しできます。
# findItemByKeys高速化のため、インデックスを作成・格納するための変数を作っておく
self.itemIdxs = {}
””””
{"table名":{
"XBTUSD-68978907-sell" : 2,
"XBTUSD-90686787-buy" : 108,
....
....
"""こうしたインデックスがあれば、探したいデータのキーを使って、即座に対象データを取り出すことができます。
改修後のfindItemByKeys()は下記のようになっています。(処理時間計測の文は削除してあります)
def findItemByKeys(self, keys, table, matchData, itemIdxs):
md_keyvalue = "-".join([str(v) for k,v in matchData.items() if k in keys])
if md_keyvalue in itemIdxs.keys() and len(table) > itemIdxs[md_keyvalue] :
return table[itemIdxs[md_keyvalue]]matchDataからキーとなる情報を取り出して連結し、それをつかって、
辞書(itemIdxs)にそのキーを持つデータが含まれているかをチェック
それがOKなら、tableの何番目からデータを取り出すかを指定して、そのまま返却しています。
ただ、この方法にはちょっとめんどくさいトレードオフがあります。それは新しいデータが来たり、データを削除したりした場合に、インデックスを常に最新の状態しておくことが必要なことです。
それで、partial、inset、deleteの処理において、インデックスを作成・更新する処理を入れてあります。
例)partialのindex作成処理
#indexを作成します
# self.itemIdxs[table][keyvalue(kye1val-key2val-key3val)] に
# 対象データのdata[table]上のインデックスが格納されます
for i in range(len(self.data[table])):
item = self.data[table][i]
keyvalues = "-".join([str(v) for k,v in item.items() if k in self.keys[table]])
self.itemIdxs[table][keyvalues] = iかなり端折ってしまいましたが、実装方法の解説はここまでとして、気になる改修結果をご紹介したいと思います。
改修結果
先ほど貼らせていただいたbitmex_websoket通常版の計測結果と同時に計っていた、改修版の測定結果が下記になります。
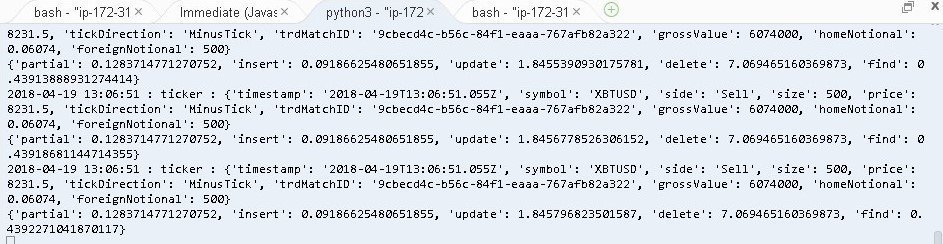
partialが0.1283秒、insertが0.0919秒、updateが1.8457秒、deleteが7.0695秒ほどかかっています。改修前がupdateだけで110秒かかっていたことを考えると、すべて合わせても10秒たらず。全体で約10倍の高速化に成功しています。
findItemByKeys()などは0.4292秒、約256倍の高速化に成功です!しかも数字の切りがいいなぁ!
これにより、遅延が発生するほどの処理待ちがなくなり、現在時刻と取得したデータのタイムスタンプも、ほぼ差がありません。
高速化成功です!!
この記事は、AKAGAMIさん販売のドテン君を改良していく中で、websocketを使用した改修を行おうとし、bitmex負荷増加時にTIMESTAMPの値がおかしいという報告を頂いて、対応したものです。
ドテン君を購入することで参加できる「AKAGAMI LOUNGE」では、bot開発・運用・その他について、常に濃度の高い議論がなされています。5万円と高額のnoteですが、逆に考えますと、botを利用するために5万円のリスクをとれるマインドの高い方々の集まりです。勉強にならないわけがない!
このbitmex-websocketの改修版を使用した、価格変化を高速にとらえるbotも「AKAGAMI LOUNGE」内で無料公開させていただく予定です。(すでに有料で公開されている方もいらっしゃるようですが、まぁ、わたくし後発のようですし、LOUNGE内では無料で配布させていただきます!)
なお、私のコミュニティでの名前も「モッチオ」となっております。
当noteに関するご質問やコード提供など、できる限り対応させていただきますので、是非声をおかけください。