エンジニア女子が触れているプログラミング言語の傾向をPythonを使って分析する - (エピソード3)

Janomeを使って形態素解析を行う
今日も前回から引き続き、エンジニア女子が触れているプログラミング言語の傾向をPythonを使って分析していこうと思います。
前回、各記事のテキストを1.txt, 2.txtという形でテキスト形式に保存しました。
今回、それらのテキストファイルを一つ一つ読み取りながら、形態素解析を行い、記事内で使用されている名詞をも抜き出していこうと思います。
テキストから形態素解析を行い、名詞のみを抜き出す
前提としたtextsというフォルダ内に分析対象のテキストが置かれているものとします。
texts
├── 1.txt
├── 10.txt
├── 11.txt
~~~Janomeを用いて名詞のみをフィルタリングする方法ですが、本家ドキュメント内に記載があるので、そちらを参照していきましょう。
TokenCountFilter を使うと,入力文字列中の単語出現頻度を数えることができます。以下は,文字列中の名詞の出現回数を数える例です(POSKeepFilterで名詞のみフィルタしています)。戻り値の各要素は,単語(表層形)とその出現回数のタプルになります。
POSKeepFilter、TokenCountFilterを用いれば、やりたいことがすぐに実現できそうですね。
というわけで、下記のようなコードを書いてみました。
(相変わらず書捨てっぽい雰囲気ありますがご愛嬌で)
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import *
import glob
import os
def main(filepath, t, a, result_file):
with open(filepath) as f:
text = f.read()
for k, v in a.analyze(text):
print('%s: %d' % (k, v))
result_file.write(k + "," + str(v) + "\n")
def listup_files(path):
return [os.path.abspath(p) for p in glob.glob(path)]
if __name__ == "__main__":
print("=== 処理を開始します ===")
target_path = "./texts/*"
path_list = listup_files(target_path)
t = Tokenizer()
token_filters = [POSKeepFilter('名詞'), TokenCountFilter()]
a = Analyzer(token_filters=token_filters)
with open("./textanalysis_result.csv", mode="w") as f:
f.write("単語, 出現回数\n")
for i in path_list:
main(i, t, a, f)
print("=== 処理が完了しました ===")
このコード内では最終的に、
単語, 出現回数
という形式のCSVファイルを生成するようにしています。
なぜわざわざCSVファイルにするかというと、これを最終的にはGoogle Spreadsheetにimportして、単語の選定を行いたいからです。
(技術系ワードとそうでないワードの選定をプログラマブルに行うのには手間がかかりそうだと思い、そのようなやり方を選びました。もちろんここらへんは実際に掛ける工数と得られるものとの兼ね合いで考えていく必要があります。無駄に時間かけるの、ダメ、ゼッタイ)
さて、実際にこのファイルを実行すると、下記のようなCSVファイルが生成されました。
単語, 出現回数
今回,1
エンジニア,9
女子,1
オープン,3
エイト,3
テクノロジー,2
開発,6
〜〜〜これを次回は使用していきましょう。
ブログ内で使用されている単語の傾向をランキング化させて表示させる(余談)
ちなみに上のコードを使えば、例えばこのブログでよく使われている単語なども調べることができます。
ちょっと面白そうなので下記の記事で試してみました。
(このブログの最初の記事です)
上の記事からテキストのみを抜き出しテキストファイルに保存した後、先程のコードで解析をします。作成したcsvファイルをgoogle spreadsheetにインポートし、数の多い順に並べ替えしたものがこちら。
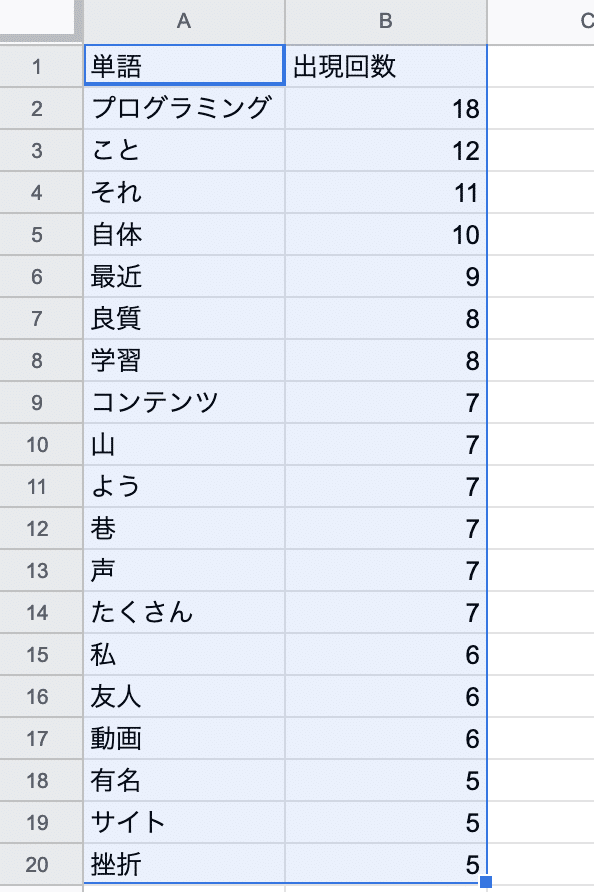
プログラミングという単語が多いのは予想通りですが、こと、それなどが入ってしまっているので、これらは除外する必要がありますね。
学習、コンテンツ、動画、などの単語が上位に入っているのもうなずける結果です。
ここらへんのインポートの流れについては次回見ていく予定です。
Janomeの作者も、やり手の女性エンジニア
ちなみに女性エンジニア関連の話をすると、Janomeの作者であるmoco_betaさんも女性エンジニアです。
Pure Pythonで形態素解析器を作成するなど、かなりやり手の方なので、技術系エンジニアとしてキャリアアップを図りたいエンジニア女子の方々は参考にされてみてはいかがでしょうか?
いいなと思ったら応援しよう!
