
開発生産性指標・FourKeysについてまとめてみた

長年CTOをやってますが、開発生産性の話しは、長年の悩みでした。
アンタッチャブルとして、触れる事は許されない領域として捉えてました。
しかし、Four Keysが出てきて、ようやくこの辺の議論が出来る様になってきたので、FourKeysについてまとめてみました。
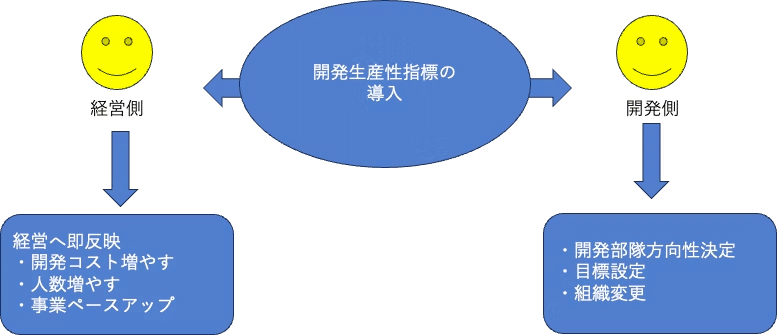
経営側の課題
・開発部隊の中身がわからない
・イケてるのか悪いのか心配
・生産性が良いのか悪いのか不明
・コストを何処まで許容すべきか不明
開発部隊側の悩み
・もっと成果をアピールしたい
・コストの妥当性を説明したい
・生産性の高いチームを証明したい
指標による見える化で目線をあわせるべき
Four Keysの提案
Four Keysとは、
ソフトウェア開発を行えているかどうかを計測する指標です。
Four Keysの指標を用いることで、開発組織のスループットが可視化され、歩留まりの解消と生産性の向上を促すことができるようになります。
「Four Keys」とは、GoogleのDevOps Research and Assessment(https://dora.dev/)
チームが提唱した開発生産性を計測するためのフレームワークで、以下4つの指標で構成されています。

Four Keysと組織のパフォーマンス
DORAはFour Keysの正しさを学術的な手法で明らかにした
Four Keysに関する回答をクラスタリング分析し、ハイパフォーマー/ローパフォーマーの発見
→ハイパフォーマーほど組織のパフォーマンス (収益性や市場上昇率、国際の競争能力など)も高いとわかった
Four Keysは、手法の効果も説明できる
例題: リファクタリングはどんな効果があるのか
・変更のリードタイム: 変更を加えやすくなり短縮
・デプロイ頻度: 頻繁になることでリスクとリリースが可能
・変更失敗率: コードを理解しやすくなりミスが減少
・サービス復元時間: コードを理解しやすくなり原因の特定が容易に
→ 適切なリファクタリングが開発生産性の向上につながることが
分解して体系的に証明できる
Four Keysの提案
品質(安定性)とスループット(ベロシティ)の両立
Four Keysは、互いに独立した指標ではなく、デリバリにおける品質とベロシティを高いレベルで実施できているかを測る指標です。

1.変更のリードタイム
コードが commitされてから本番環境で正常に実行されるまでの時間

変更リードタイムの改善例
1.バリューストリームマップ(VSM)を書いてボトルネックを発見
2.よくあるボトルネックの対処
・CIの高速化
・即レビュー文化などでレビューリードタイムの短縮
・計画によって作業単位とリリース単位を小さくする
・フィーチャートグル(フラグ)などで本番反映までに待たせない
・QA作業の最適化
・リリースフローの最適化
2.デプロイ頻度の改善
・変更リードタイムの改善により頻度が上がる
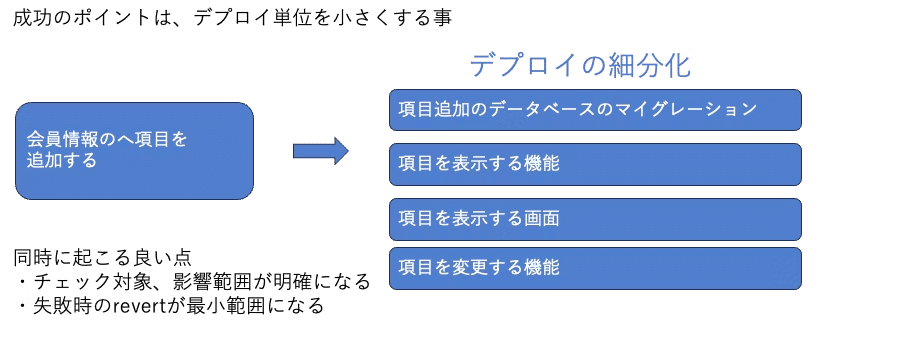
・デプロイ単位を小さくする
・測定指標は、
・PR数、PRオープン数、PRマージ数等
・d/d/d deploys/a day/developer) 0.1以上を目指す
・リリースとデプロイの分離(Feature Toggleの導入)
・すぐにマージできる仕組みの導入
・リリース作業の簡素化・自動化
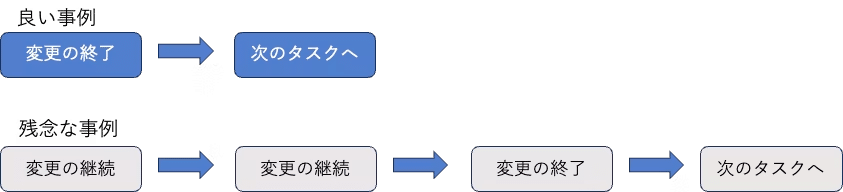
3.変更失敗率
本番環境に変更を加えた、またはユーザーへのリリースを実施した結果サービスが低下し、
その後修正を行う必要が生じた割合
障害ではなく、失敗率。
つまり、本番で障害は起こらなくても、再度、修正が必要となった場合も含める。
ただし、計測が難しいため、障害の計測のみもあり。

変更失敗率、N回失敗すれば、リードタイムもN+1となり大きく生産性が下がる
デリバリーの安定性もスループットに影響が大きい
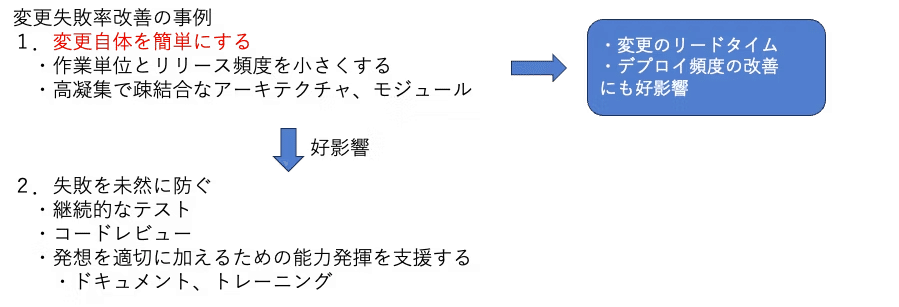
4.サービス復元時間
障害から復旧するまでにかかる時間。一般的にはMTTR(平均修復時間 Mean Time To Repair)
障害を完全になくす事は、難しいし、コストがかかるため、いかに早く復旧できるかに重きをおいた思想

サービス復元時間改善事例
1.監視の整備
・監視によって障害の予兆や障害を検知する
・ログ、メトリック、トレーシングで原因を特定
2.ロールバックの仕組みの整備
・変更起因の障害を安定して修復可能にする
3.障害対応訓練や障害対応テンプレートの整備
4.障害ノウハウ蓄積
・ポストモーテムを行い、過去の経験を活かし未来対策を行う
自分たちで気付ける様に監視する
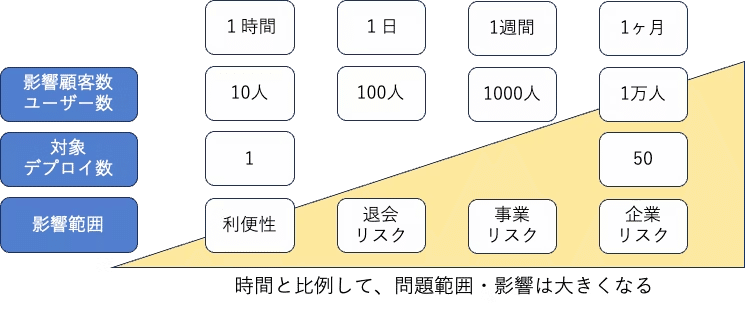
障害の発生フロー
1.お客からの通報
2.社内からの通報
3.システムからの通報
3番についての割合を増やしていく。(計測)
3で気付くと障害時間が短くなる。つまり影響範囲も小さくなる。
長くなると、お詫び対応やログの調査、影響ユーザー調査、サービス補填等とんでもなくコストが増えてしまう
監視の事例
1.サーバーリソース
CPU・メモリ・ディスク・ロードアベレージ
2.アプリ異常値
200以外のステータスの監視
3.エンドポイント、画面表示の処理時間の監視
異常値チェック、割合チェック
4.ビジネス重要指標の定点観測・監視
登録率、マッチング率、ファネルチェック等
5.データ整合性チェック
データ側から整合性があっているかのチェックを行い仕様漏れなどを検出
計測しながらやるべき事
開発に置いての様々な見直し
1.git-flowからGithub Flowへ
2.CIからchatopsへ
3.考え方のインストール
4.組織変更
1.git-flowからGithub Flowへ
デプロイ頻度をあげるためにgit-flowの問題点
リリースフローとか複雑
・リリース前に手作業的な手順や検査の手続きが発生する
・releaseブランチを切る / mainへのPRを作る / 動作確認 /CIを待つ等など
・リリースのタイミングを合わせるためのコミュニケーションが発生する
・「今からリリース作業しますけども、いいですか?」
・「待ってください、これを入れたいです」
・「わかりました、明日の朝にします」
・誰かが「リリース作業」を進行する必要がある
・当番制など
・変更担当者がリリース時に不在の時に検証すべき点等の引き継ぎが発生する
・「XXXの変更が混ざっているので、YYYのチェックをお願いします」
→このままではデプロイ頻度をあげられない
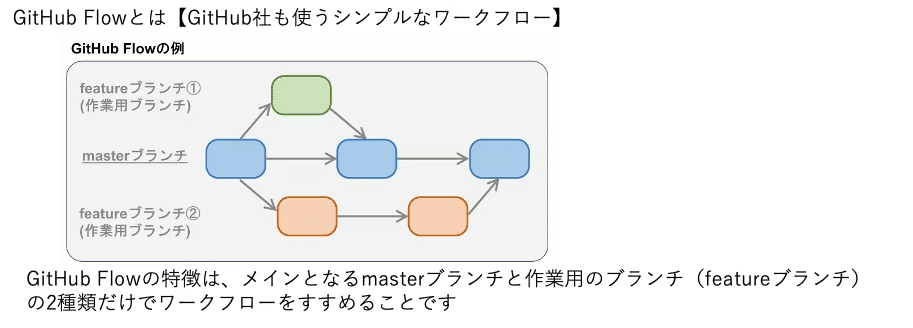
GitHub Flowを使うときに守るべき6つのルール
①「masterブランチのものは何であれデプロイ可能である」
②「masterから説明的なブランチを作成する」
③「名前をつけたブランチに定期的にpushする」
④「いつでもプルリクエストを作る」
⑤「マージはプルリクエストがレビューされた後だけ」
⑥「レビューのあとは直ちにデプロイする」
→ マージやデプロイがすぐに出来る状態に持っていける
2.CIからchatopsへ
CIといえば、CircleCIやJenkinsやcapistranoですが、マージされたらすぐにデプロイするためには、
ツールの画面を立ち上げたりする事自体、非効率
Slackからchatopsにより簡単にデプロイ可能にする
同時にインフラ側では、
fargateやECS等のコンテナの導入を行いデプロイ速度、デプロイの簡素化も必須。
→ デプロイに対しての物理的、心理的障害をなくす
3.考え方のインストール
Four Keysの指標を上げることを目的にしてはいけない
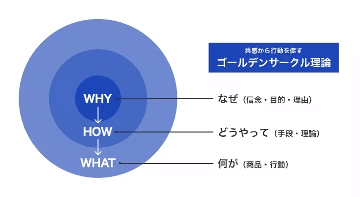
ゴールデンサークル理論により指標を目的ではなく、WHYから始める!
ゴールデンサークル理論によりとは、
「WHY(なぜ)→HOW(どうやって)→WHAT(何が)」の順番で伝えることで共感を得られる、という理論です。説明を「WHY(なぜ)」から始めると、他者の感情や信念の部分に触れられるため、行動を促しやすくなります。
・WHY:なぜデプロイ頻度が多い方が良いのか?
→ ・デプロイ頻度が少ないと沢山の機能が一度にデプロイされてしまう。
これにより、テスト、レビューも難しい、リリース後チェック、リバート戻しも難しくなる
・マージが大変、コンフリクトも多数発生
・リリース日程調整が大変
・ WHY: PRが小さくなると何が良いのか?
→ ・レビューがすぐにできる。量が多いと見る気が失せる。
・テストが小さいので品質が上がる
4.組織変更
1.現状チームに課題を与えて対応してもらう
→ 既存のタスクの追われて改善出来ない可能性が高いので、
メンバーのタスク状況を確認する必要あり
2.専任メンバーを置き、各チームと兼務にて推進してもらう
→ 専任メンバーは、 Four KeysのWHYを理解してもらった上で、
且つ、各チームに入り込み改善業務を推進してもらう
3.指標関連の仕組み化は、独立して実施する。
→ 自社で仕組みを構築するか、外部サービスを利用するか決定
→ 組織的に動かないと生産性向上は実現出来ない
評価
1.各指標をOKRに利用したり、人事評価にも利用する
2.ただし、個別にPR数等が少ないメンバーにヒヤリングを行い改善を行う

指標だけを独り歩きさせたり、大枠でのみ数値を見るのではなく、個別に改善活動が必要
まとめ
様々の先駆者の方々の資料とか登壇内容から私なりに整理して現在運用している内容です。先駆者の皆様に敬意を評します。
2024年は、この開発生産性指標・FourKeys様々な企業に注力して導入したいと思います。
エンジニアの皆様、これはエンジニアの明るい未来のための活動です。一緒にがんばりましょう!!
最後に
未経験の皆さん、若手エンジニアの皆さん、勉強方法について悩みがあればなんでも気軽に質問して下さい!
これからも記事を書いていきますので、モチベーションアップのためフォロー、イイねお願いします。