
【コード1行解説】 python 日本語版共起ネットワークの作成

はじめに
これだけあれば「共起ネットワーク」を作ることができます。を目指して丁寧に解説しました。
「共起ネットワーク」の作成は自然言語処理の発展として最適で、WordCloudの作成を終えた初学者の次のステップとしてもおすすめです。
一般に出ている記事とは異なり、コード1行ごとに解説を挟んでいます。かなり丁寧に書いているので専門知識不要かつ、どんな方でも0から以下のような「共起ネットワーク」が最短で作れるように設計しています。

コピペ用のコードもあるので、スムーズにいけば30分ほどで「共起ネットワーク」を作ることができます。
また、質問対応も受け付けているため不明な点があればサポートさせていただきます。
対象者
pythonを使って日本語版「共起ネットワーク」を作成したい
pythonの理解を深めるために何か学習物が欲しい。
記事を見てもコードがどの行で何をやっているかわからない。
このライブラリは何といった疑問がある。
コード1行解説サンプル(本編より抜粋)
理解を深めるためにコード1行ごとに全て解説をつけているのが特徴です。
1行ずつ解説を入れることでそのコードが何をしているのか分かるような構成にしております。
コード本編よりも解説の方が分量が多く理解を深めることができます。
以下に例を載せます。
コード内にコメントにて解説をしています!
そのためそのまま貼り付けながら学習することができます。
以下#にて記載している内容が解説です。
上から読んでみてください。
import Counter
# 各単語が出現している文章の数を調べる
# word_countに全ての結果を格納するため空のCounter型を用意する
word_count = Counter()
# 1文章ごとの単語たちを取り出す
for word_list_1d in word_list_2d:
# 1文章における各単語の出現回数を取りword_countに溜めていく
word_count += Counter(set(word_list_1d))
# 解説
# setで単語の重複をなくし、全ての単語の出現回数をあえて1回とする
# なぜならば、今回使用するjacard係数の定義では各単語が何個の文章中に現れたか、が指標となるため。
# つまり1つの文章中にAという単語が1回現れようが100回現れようが「1つの文章にAが現れた->1カウント」となる
# for文によりこの処理を全文章にて行うことでword_countには「どの単語が」「何個の文章で出てきたか」かの情報が格納される
# Counterについて
# Couter型同士の足し算では「単語」と「その回数」が逐次記録されていく
# 例
# Counter({'バナナ': 1, 'りんご': 1})
# と
# Counter({'バナナ': 1, 'みかん': 1})
# を足すと
# Counter({'バナナ': 2, 'りんご': 1, 'みかん': 1})
# といった結果が得られる。
各行ごとの解説(コード内にも記載しています)
# 1文章における各単語の出現回数を取りword_countに溜めていく
word_count += Counter(set(word_list_1d))
解説
setで単語の重複をなくし、全ての単語の出現回数をあえて1回とする
なぜならば、今回使用するjacard係数の定義では各単語が何個の文章中に現れたか、が指標となるため。
つまり1つの文章中にAという単語が1回現れようが100回現れようが「1つの文章にAが現れた->1カウント」となる
for文によりこの処理を全文章にて行うことでword_countには「どの単語が」「何個の文章で出てきたか」かの情報が格納される
Counterについて
Couter型同士の足し算では「単語」と「その回数」が逐次記録されていく
例
Counter({'バナナ': 1, 'りんご': 1})
と
Counter({'バナナ': 1, 'みかん': 1})
を足すと
Counter({'バナナ': 2, 'りんご': 1, 'みかん': 1})
といった結果が得られる。
続く。。。
このレベルの丁寧さで「共起ネットワーク」の完成までを解説しています。
この記事を読むことでpythonの基本も網羅的に理解できるようになっているのでpython初心者にも非常におすすめです。
「共起ネットワーク」について、この記事で完全にマスターしちゃいましょう!
※記事について値上げする可能性があるためご了承くださいませ。
共起ネットワークの作成にあたって
共起ネットワークの構成要素
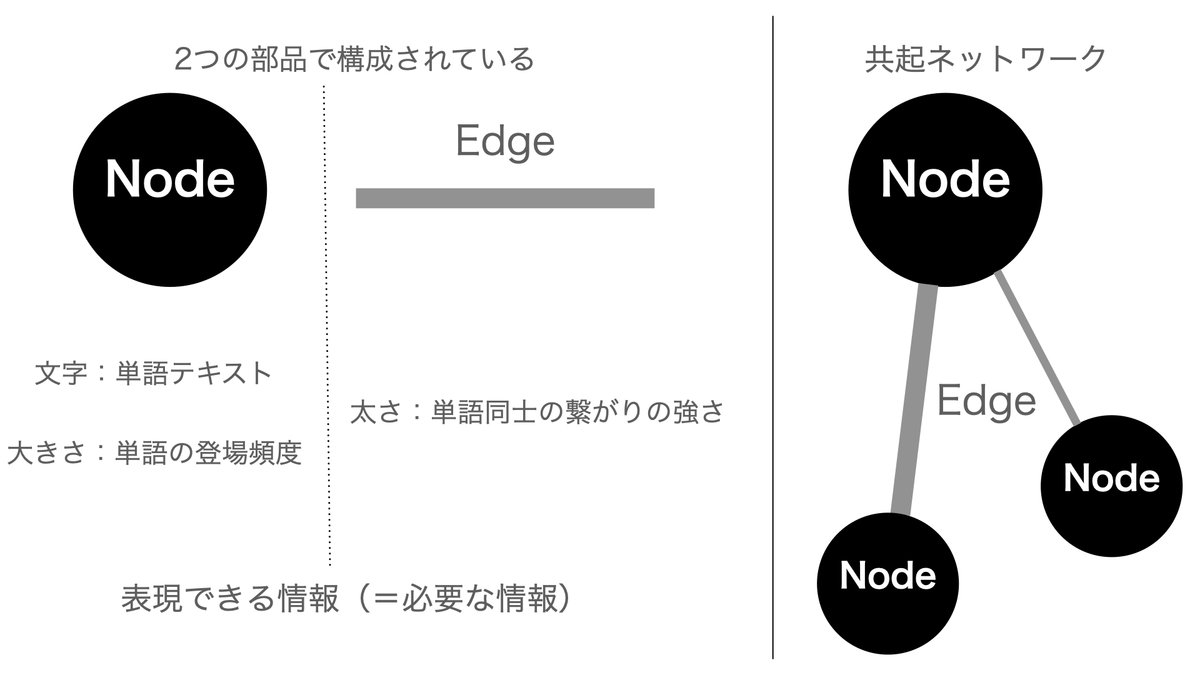
共起ネットワークはNodeとEdgeから構成されており、それらで分析した情報を可視化する手法です。
それぞれNodeの大きさやEdgeの太さで単語の登場頻度や、単語同士の繋がりを表現することができます。
逆にいうとこれらの情報があれば、共起ネットワークを描くことができるということになります。
Nodeの作り方
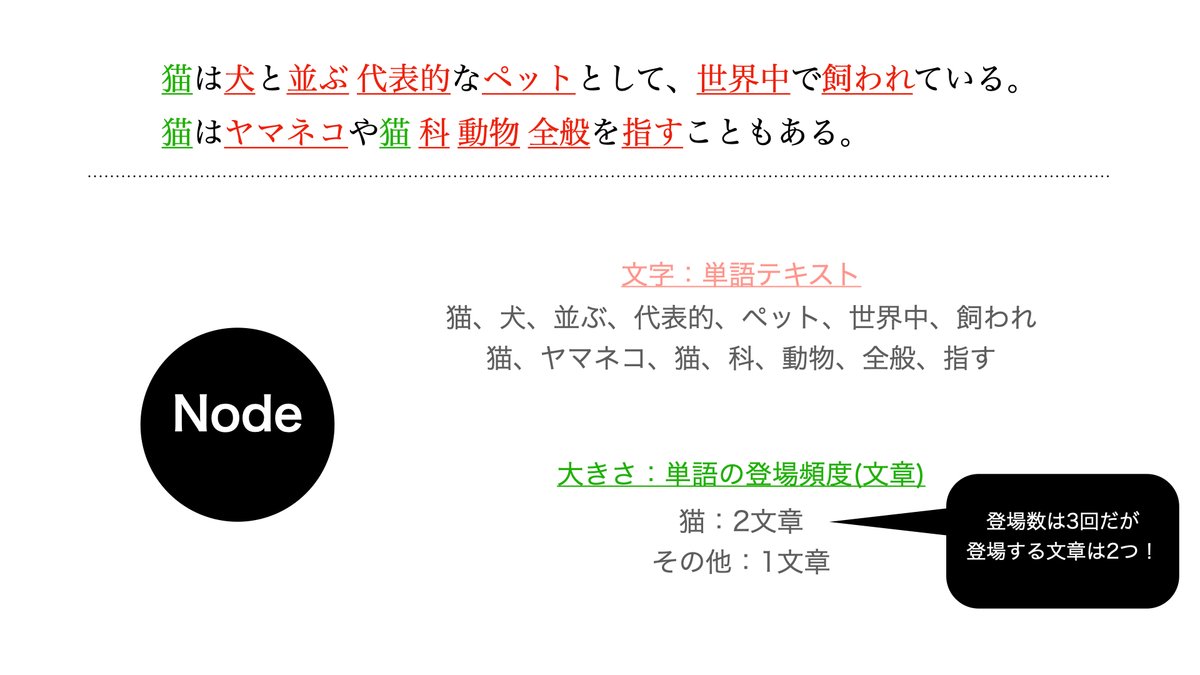
Nodeは「1.単語情報」と「2.単語の登場頻度情報」の2つを与えることで表現することができます。
「1.単語情報」については、スライド上部に記載した例文を用いて「猫」「犬」といった単語が抜き出せることからイメージできるかと思います。
「2.単語の登場頻度情報」については、今回は単語の登場頻度を単語の登場文章数として定義することに注意してください。これは一文章に同一の単語が何度も出て来た場合に何度もカウントしないようにするためです。
Edgeの作り方1

Edgeでは「単語のつながりの強さ」をEdgeの太さで表します。
ただここで、「単語のつながりの強さ」とはどのように定義するのでしょうか。分析をする上では、この「単語のつながりの強さ」何らかの数値として読み取らせる必要があります。
Edgeの作り方2

そこで「つながりの強い単語同士は文章中に同時に登場するのではないか?」という仮説を立ててみます。
実際に、「猫」「ペット」「飼われる」「犬」「動物」という単語についてみてみると、「猫」は「ペット」で「飼われる」ものであり、「犬」も同様、「猫」も「犬」も「動物」であることから、これらの単語は関連が高そうに見えます。
このように文において、単語と単語が同時に出現することを「共起」といい、今回はこの「共起」の特徴を活かして単語同士の繋がりを表現してみたいと思います。
Jaccard係数について

共起を用いた単語同士の繋がりの強さを表現する手法の一つに「Jaccard係数」というものがあります。
この定義だけ見ても何のことかわからないと思うので、実例を見てみたいと思います。
jaccard係数の具体例

これから2単語間の繋がりの強さを定義します。今回例として、対象の2単語をそれぞれ「A:猫」「B:ペット」とします。
「A:猫」という単語はスライド内の1),2),3)の文章内に出てくるためAの集合には1),2),3)の文章が入ります。
同様に「B:ペット」という単語はスライド内の1),2),4)の文章内に出てくるためBの集合には1),2),4)の文章が入ります。
これらを表した図がスライド内の図になっており、Jaccard係数の定義に従うと
AとBの共通要素(文章)が2 つ
AとBのどちらかを含む要素(文章)が4つ
のためJaccard係数は
2/4=0.5
となります。
また、Jaccard係数の意味するところは、
分子=対象の単語が同時に使われている文章数(共起の文章数)
分母=対象の単語がそれぞれで使われている文章数
つまり、対象単語を含む全文章のうち
対象の単語が同時に使われている確率、割合を示す係数と言えます。
jaccard係数の計算テクニック

ここではJaccard係数の計算テクニックについて紹介します。
Jaccard係数の分母に注目してみると
Jaccard係数の分母 = Aの要素数+Bの要素数-AとBの共通要素数
と計算することができます。
ここで最後の項の「AとBの共通要素数」はJaccard係数の分子そのものです。
そのため、Jaccard係数を求める際には
Aの要素数(Aを含む文章数)
Bの要素数(Bを含む文章数)
AとBの共通要素数(AとBが共起する文章数)
の3つが分かると計算することができます。
jaccard係数まとめ

まとめるとNodeの定義で使用する単語同士の繋がりの強さは共起を利用した、Jaccard係数によって定義することができる。
そのJaccard係数は
1. 単語A
2. 単語B
3. 単語A単語Bが同時に出現する文章数
の3つの要素を求めれば良いということになります。
これらをpythonを用いることで計算機的に一気に処理を行います。
事前準備
必ずインストールしておくライブラリ
以下をインストールしてください。
pip install pandas
pip install numpy
pip install networkx
ここから先は
この記事が気に入ったらチップで応援してみませんか?