
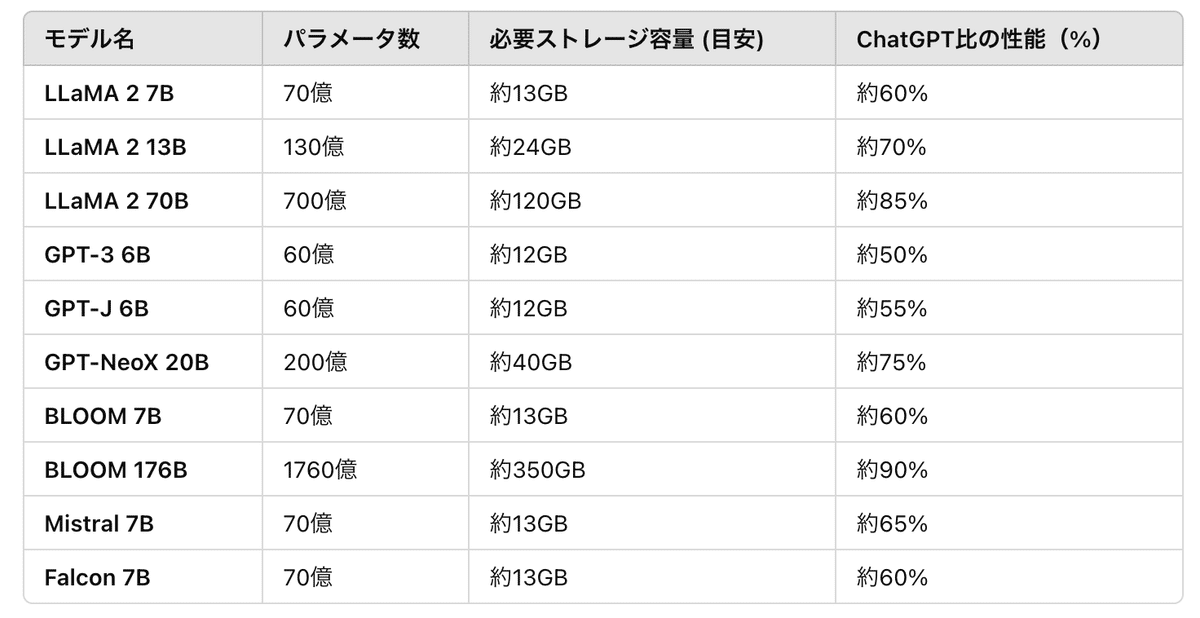
2024年 / LocalPCにインスト可能なLLM

以下は、各モデルがローカルPC上で動作するために必要なストレージ容量の目安です。モデルのサイズは、通常FP16(半精度浮動小数点)やINT8(量子化)などの最適化がされていない状態でのもので、最適化の度合いによっても異なります。
補足
モデルサイズの最適化: 上記のサイズは、モデルがFP16形式で保存されている場合のものであり、量子化(INT8やINT4)や分散化することでさらに小さくできます。
動作環境の影響: これらのモデルは、通常GPUや高速なCPUとRAMを必要とするため、ハードウェア要件もストレージと同様に考慮する必要があります。
BLOOM 176BとLLaMA 2 70Bは、いずれも高度な自然言語処理タスクに対応するために開発された大規模なLLMで、性能や特徴において多くの興味深い点があります。それぞれの詳細を見ていきましょう。
1. BLOOM 176B
開発背景: BLOOM(BigScience Large Open-science Open-access Multilingual Language Model)は、BigScienceプロジェクトによって開発され、多くの言語とドメインに対応するモデルとして設計されました。BLOOMは特に、多言語対応が強みで、複数の文化的背景や言語間の理解を支援するための設計がなされています。
パラメータ数: 1760億パラメータ
必要ストレージ容量: 約350GB(FP16形式)
相対性能(ChatGPT比): 約90%
特徴と技術的な詳細
多言語対応: BLOOMは、46の言語と13のプログラミング言語に対応しています。これにより、英語以外の言語(日本語を含む)でも優れたパフォーマンスを発揮するようにトレーニングされています。
分散学習: BLOOMのトレーニングには、さまざまな組織から提供された分散コンピューティングリソースが活用され、10,000人以上の研究者がプロジェクトに参加。多言語に対応する膨大なデータセットと分散学習によって、性能を最大限に引き出しています。
プラグイン対応と拡張性: BLOOMは多言語・多文化対応を目指しており、他のAIモデルやAPIと連携しやすく、柔軟なシステム拡張が可能です。
デプロイ難易度: BLOOM 176Bは非常に大規模なため、通常のPCや標準的なGPU環境での動作は困難です。NVIDIA A100(40GBのVRAM)などの高性能GPUを複数台使用することが推奨されます。また、ローカルでのデプロイには高度な知識とインフラが必要です。
主な用途
多言語サポートが必要なタスク: 国際的なアプリケーションや、複数言語を扱うデータの処理。
大規模な自然言語生成: 物語生成や記事作成などの自然言語生成タスクで、極めて自然な文体と内容を提供可能。
2. LLaMA 2 70B
開発背景: LLaMA(Large Language Model Meta AI)は、Meta社(旧Facebook)が開発した言語モデルで、LLaMA 2はその最新バージョンです。LLaMAシリーズは、特にパラメータ数と計算リソースのバランスを考慮し、効率的かつ性能の高いモデルを目指しています。
パラメータ数: 700億パラメータ
必要ストレージ容量: 約120GB(FP16形式)
相対性能(ChatGPT比): 約85%
特徴と技術的な詳細
計算効率: LLaMA 2はパラメータ数を抑えながらも、効率よく高精度の出力が得られるよう設計されています。高い計算効率により、BLOOM 176Bよりもリソースの少ない環境で運用可能です。
高いパフォーマンス: 特に推論性能において優れており、特定タスクにおいて高い精度を維持しながらも効率的に動作します。
トレーニングデータと最適化: LLaMA 2は、主に英語を含む一般的なデータセットでトレーニングされており、さまざまな自然言語処理タスクに対応可能です。
デプロイ可能な環境: LLaMA 2 70BはBLOOM 176Bほどの計算資源を必要とせず、VRAM 40GB程度のGPUがあればローカルPCでも動作可能。これにより、BLOOM 176Bよりも広範な環境での実装が可能です。
主な用途
自然言語生成と応答: カスタマーサポートや会話エージェントなど、自然な対話生成において有用です。
分析と推論タスク: 言語理解や要約、文章分類などの推論タスクにおいて、効率的かつ高精度な処理が可能です。
研究用途: Meta社の支援により、学術研究やプロトタイプ開発に向けて広く提供されています。

両モデルとも優れた性能を発揮するため、用途やローカルのPCスペックに応じて選択することが重要です。BLOOMは多言語対応が求められるプロジェクトに適し、LLaMA 2は効率とパフォーマンスを重視した用途に向いています。