
gitlabを使ったAWS CodePipelineで成果物をS3にデプロイする

ここまで見てきたようにAWS CodePipelineは一般的には以下の3層(ステージ)で構成される事が多い
ソース: コードのリポジトリやアーティファクトの取得元を指定します。
ビルド: コードのコンパイルやパッケージングを行います。
デプロイ: アプリケーションを指定の環境に配置します。
この3層に限らずいろいろ複雑な構成を取る事は可能
今現在のチュートリアルでは1.と2. を見てきたが、ここでいよいよ3のデプロイに挑戦してみようというのが本稿の狙いである。
シナリオ: markdownをhtml化した生成物をs3に移動する
この項目で概ねmarkdownからpandocを使ってhtmlにする事ができているはずだ。これをs3に移動する手順をみていこう。
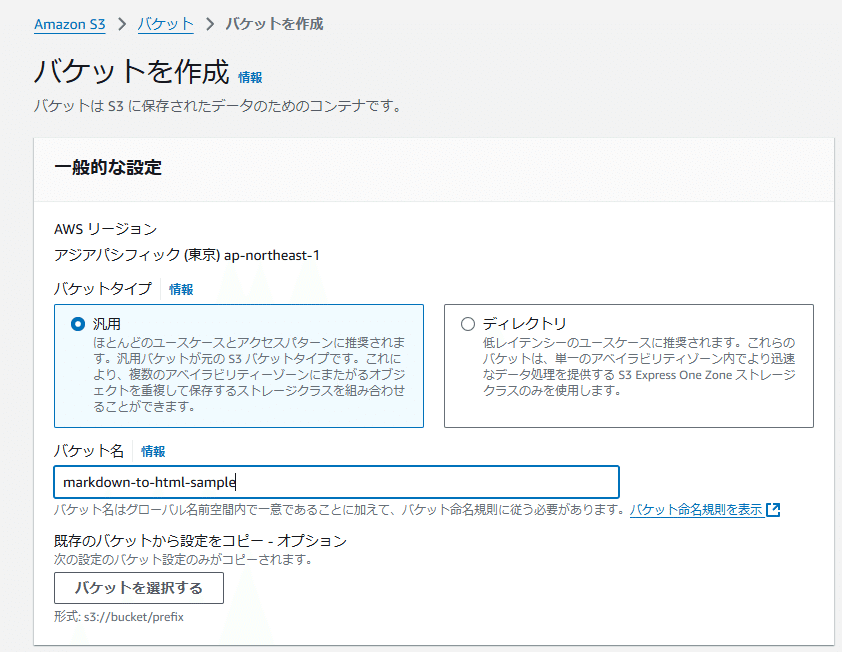
s3バケットの作成
まず、保存先としてs3バケットを作成する。これはAWS内で一意である必要があるので各自適当に作成する事。ここではmarkdown-to-html-sample とした
再びpipelineを作成する
Build custom pipelineからパイプライン名をtest-deploy-to-s3とした
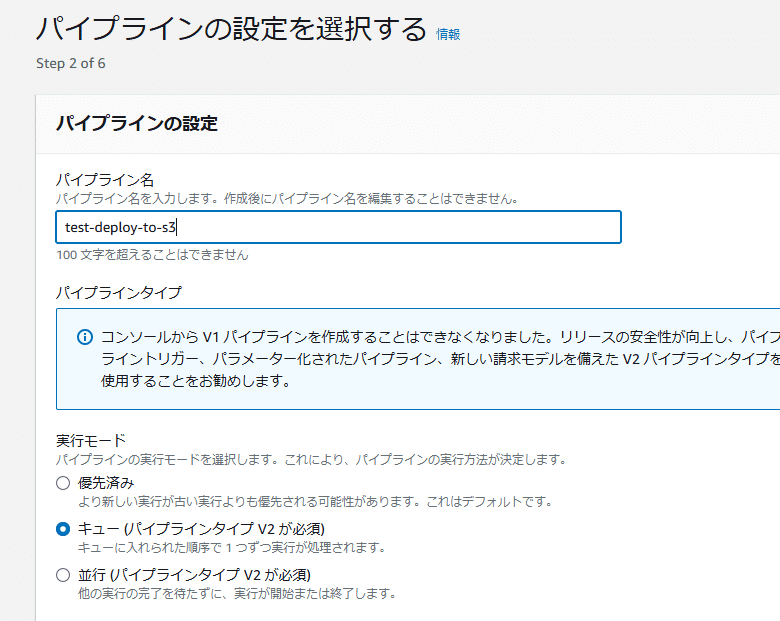
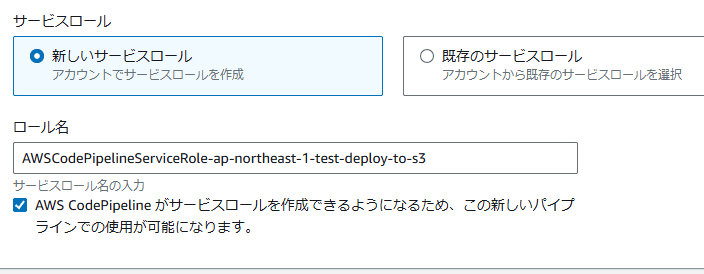
ここでロールがまた新たに作成される。ここではAWSCodePipelineServiceRole-ap-northeast-1-test-deploy-to-s3 となっていた。まああまりロールを作成しちらかすのもアレなので本来は既存のサービスロールを使った方がいいと言えばそうなんだけどまだテストなのでこれでいく。
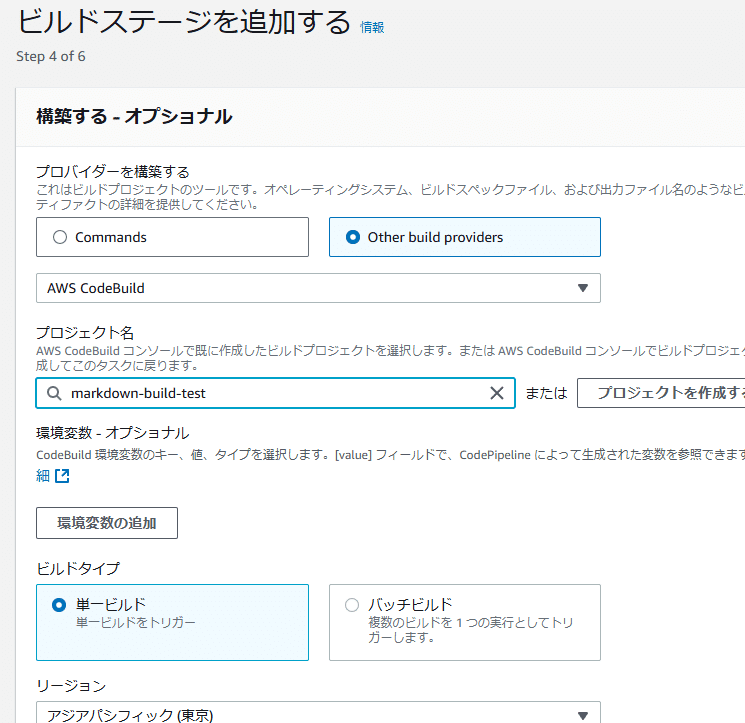
ソースステージは前回と同じく適当にヒョイヒョイ設定する。

ビルドステージは前回と同じくCodeBuildから持ってくる
デプロイステージでS3を選択する
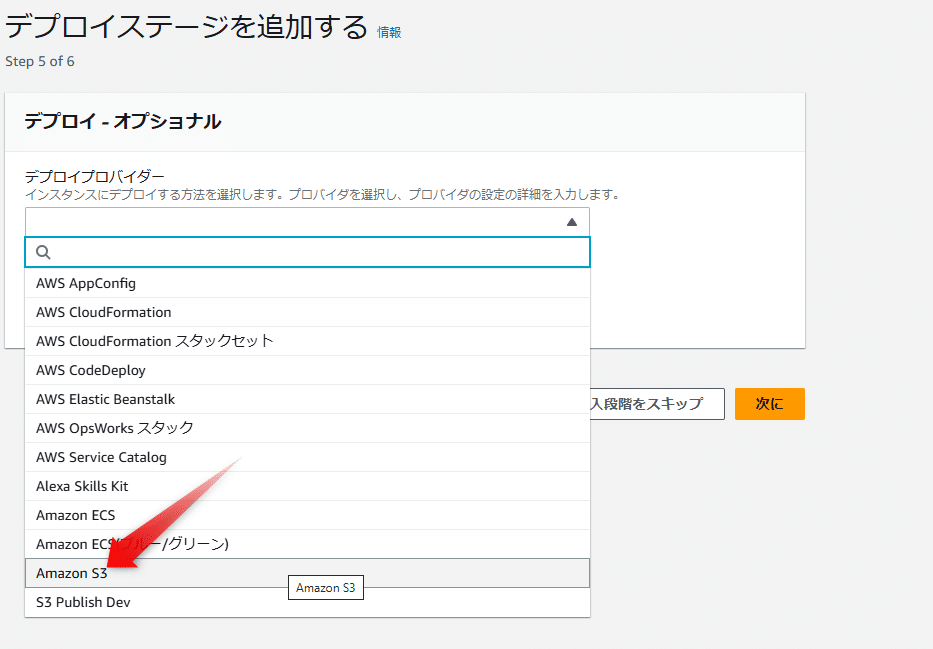
ここで
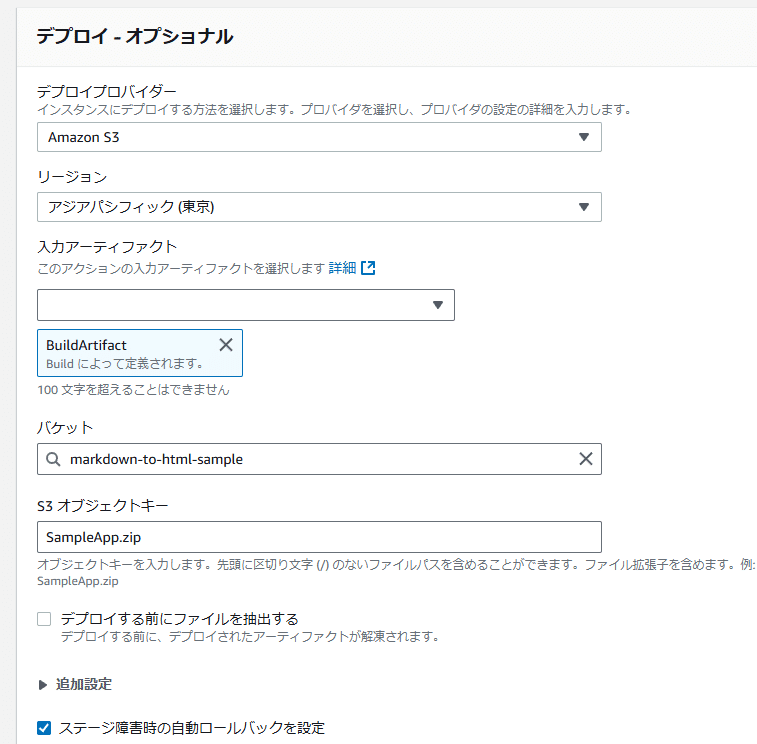
S3オプジェクトキー にSampleApp.zipと入力する。バケットは前段作ったやつ。
これでパイプラインを作成すると自動的に実行が開始されるはず。そして成功する
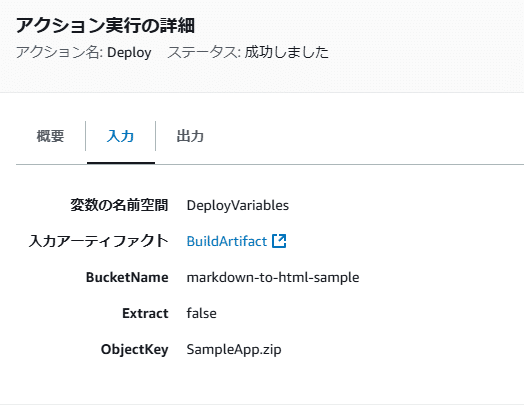
これはこれで気持ち悪いので、ロールの権限を確認しておく。
IAMロールの権限確認
IAMロールをみてみよう
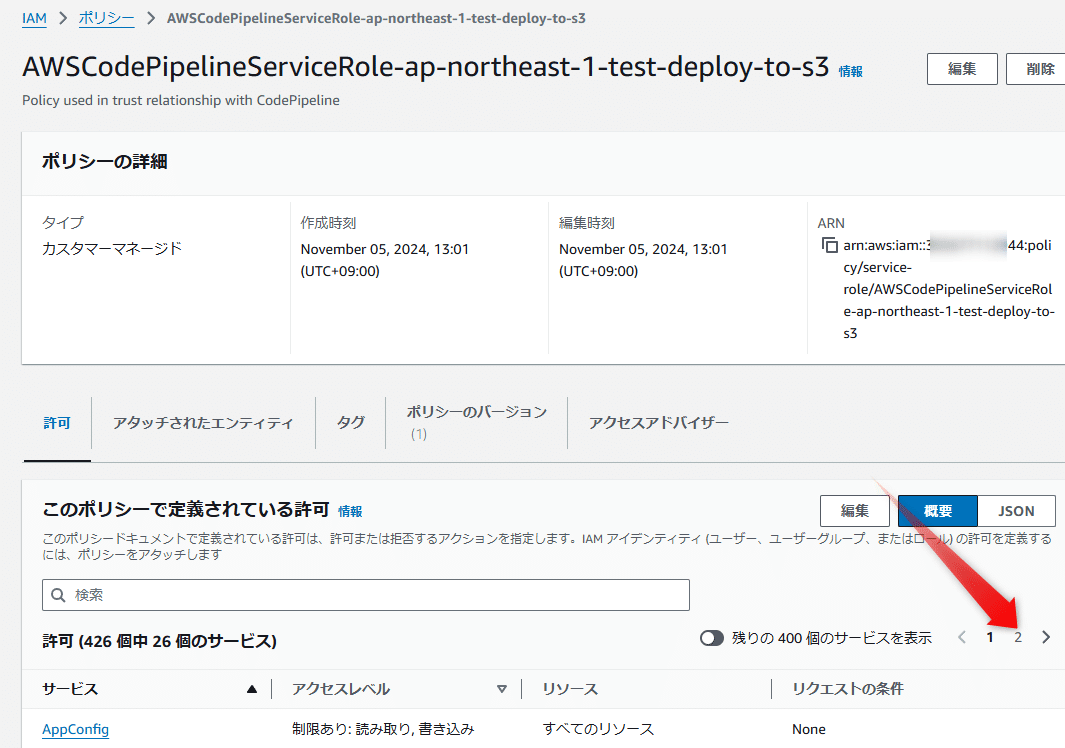
ページを送ると
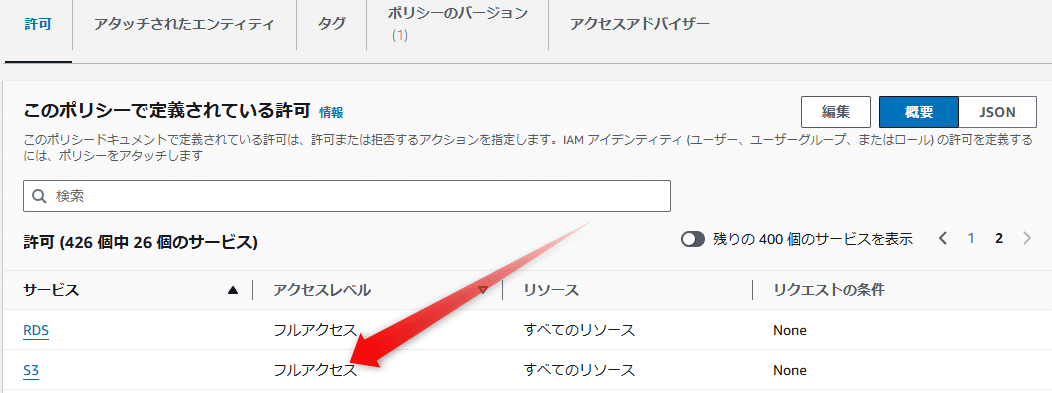
S3にフルアクセスが付いているため。これはかなり強力な権限を持つroleが自動作成されているので取り扱いはある程度気をつける必要がある。まあpipelineが実行されているときだけ有効だからある程度強力にしてあるとは思うんですけど。
S3を確認する
実際にどのようにデプロイされたかを確認しよう
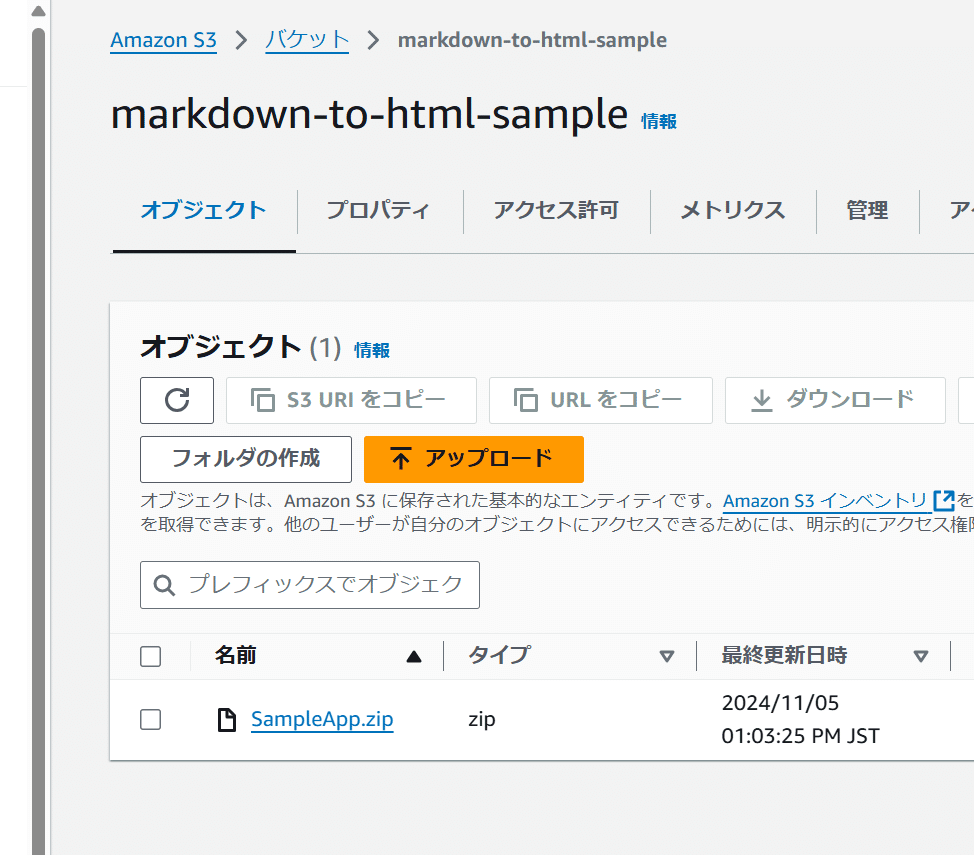
とまあこのようにzipでアップロードされている。これはそもそもビルドをどうやっていたかというと
build:
commands:
- echo "Converting sample.md to HTML format"
- pandoc sample.md -o sample.html # MarkdownをHTMLに変換
- echo "Displaying HTML content of sample.html:"
- cat sample.html # 標準出力にHTMLの内容を表示このようになっていた。つまり実際にはsample.htmlというファイル1つなのだけどもzipでdeployされている。これはどうしてかというと複数ファイルがあった場合とりあえず全てzipで固めてdeployされるという事を意味している。これがzipのままだと面倒くさい場合も多いだろう。その場合に対応するため、以下のようなビルドオプションがあるのを発見できる
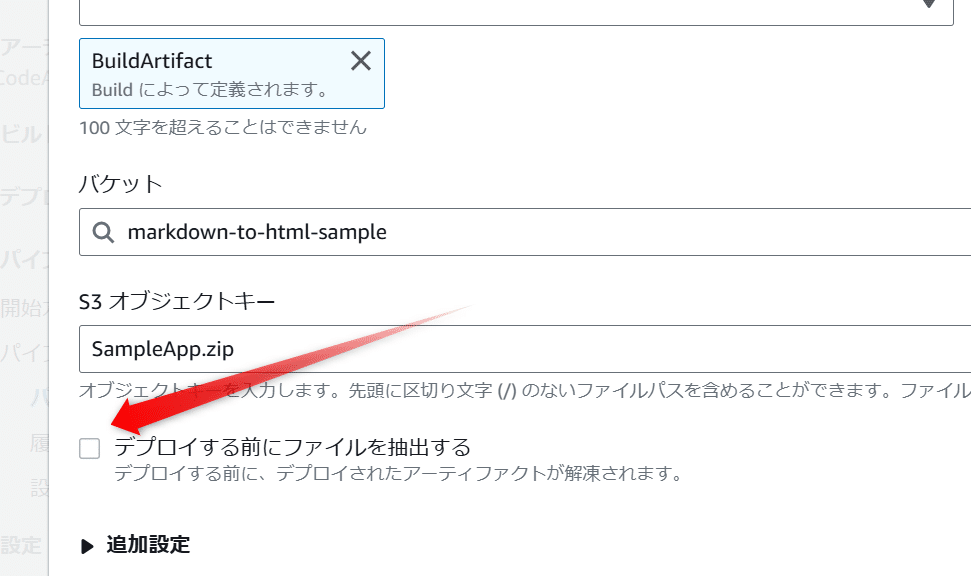
これをチェックして再度ビルドしてみよう
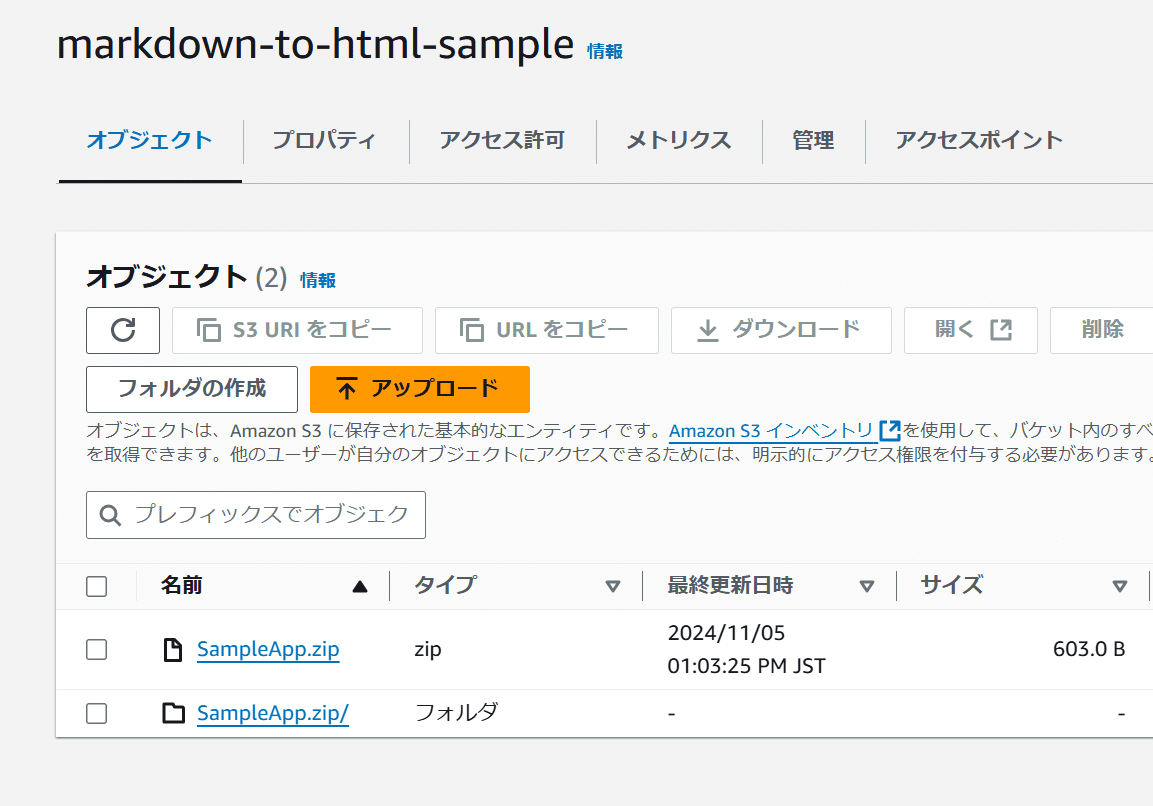
zipを残したまま展開した例。このようになる。従って、展開する場合は.zipとかじゃなくてdirの名前にしておくのがよいでしょう。
次回
s3にhtmlをアップロードしてこれをcloudfrontから見てもいいっちゃいいんだけど、これはあまりこのpipelineやらcodebuildやらには関係ないのでEC2に送りこむ例をやって一端この議題を終えようかなと思ったりしま。