
【イチからDX】RSS配信がないサイトの新着情報をSlackに通知させる方法を考えてみた〜その1

※この記事はコーディング等の勉強を一切合切したことがない人がネット上の情報を頼りに自動化する過程を記録しています。至らぬ点もあるかと存じますが何卒ご容赦ください🙇♀️
*今回の目的
noteのようにRSSを配信しているサイトであれば、以前ご紹介したように「zapier」を活用することでSlackに新着情報の通知を飛ばすことができます。しかし、どのサイトでもRSSを配信している訳ではありません。
今回社内でRSSを配信していないとあるサイトの新着情報をなるべく遅滞なくキャッチしたいというニーズがありましたが、更新頻度は低く、毎日確認するのは手間であったため、自動化できないか検討するに至りました。
*今回のゴール
今回はスプレッドシート特有の関数であるIMPORTXMLを使って新着情報を取得し、その情報をGASを使ってSlackに通知する方法を検討しました。
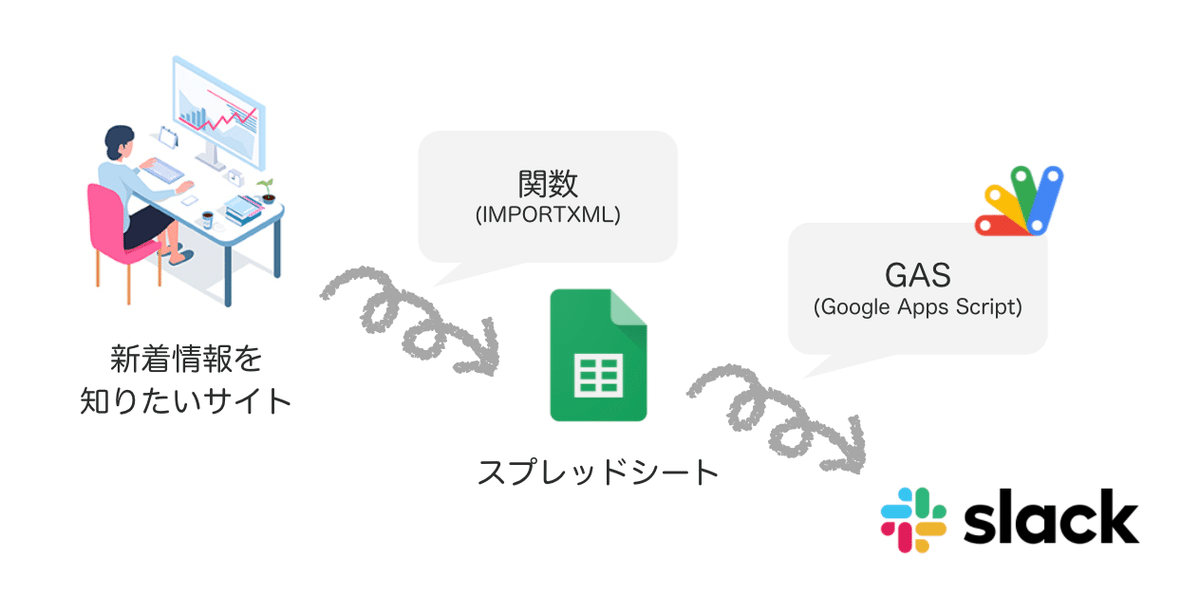
*設定手順
使用するスプレッドシートは新規でも既存のものでも構いません。また、Googleドライブ内の保存場所もどこでも大丈夫です。
*XPathの取得
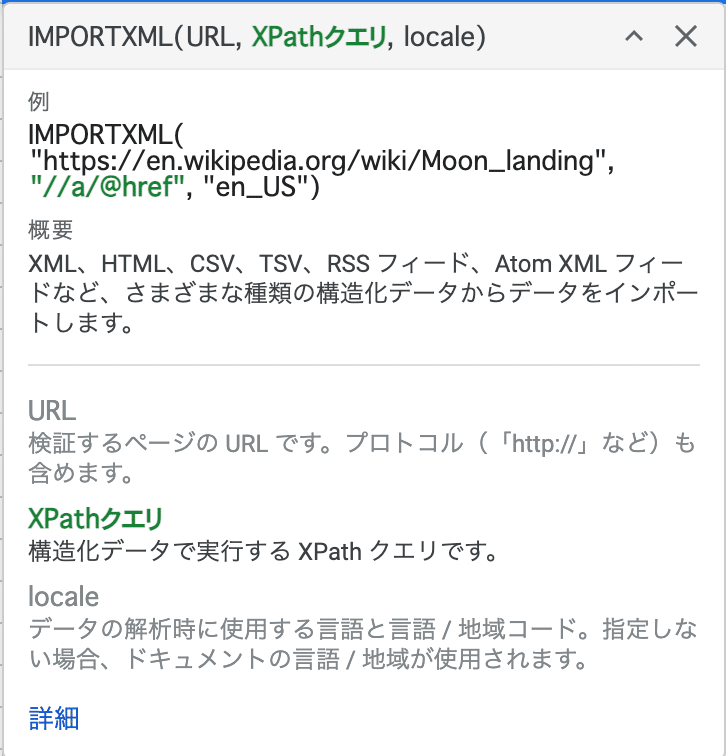
IMPORTXML関数を使用するには、情報を取得したいサイトの「URL」と「XPathクエリ」というものが必要です。
*手順1
サイト上で右クリック→「検証」を開きます(画像はChromeです)。

*手順2
右側に表示されたhtmlソースの上にカーソルをもっていくと、ページ上で該当箇所が青く表示される…とどこの記事にも書いてあるのですが、初心者にとってはそれを見つけるのが難しく。何度もエラーになりながらも今回たまたま上手くいった方法があるのでご紹介します😅
サイト上で右クリック→「ページのソースを表示」を開きます。

*手順3
新着情報一覧にある一番上のリンクの上で右クリック→「リンクのアドレスをコピー」します(リンク先のURLが取得できればOKです)。

*手順4
手順2で開いたページ上で、手順3のURLを検索します(Ctrl+F→Ctrl+V→Enter)。そうすると、福岡商工会議所さまの場合は新着情報をhtmlソース上で「news_list」というクラス名としていることが分かりました。

*手順5
手順1で開いた画面上で「news_list」を検索すると…ヒットしました🎉
カーソルをhtmlソースの該当箇所に合わせると対応する箇所(一番上の新着情報)が青くなっています。

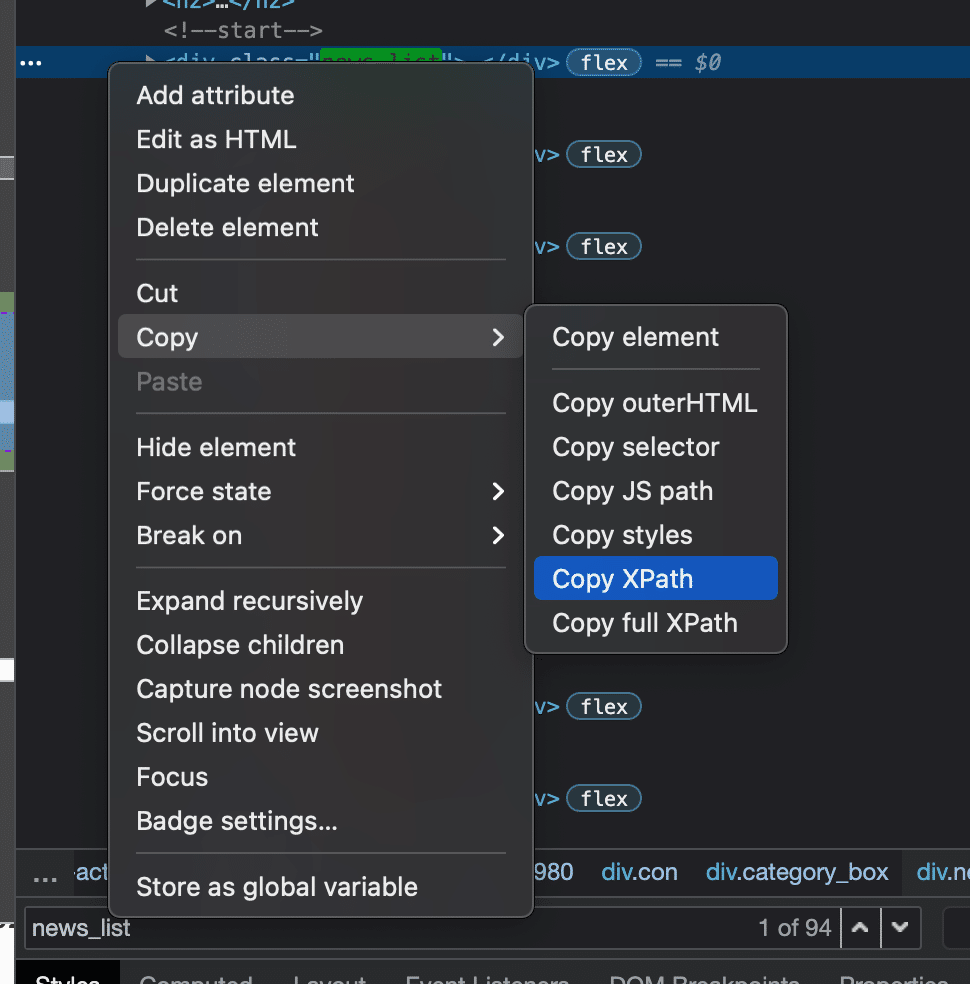
*手順6
無事に該当するhtmlソースを見つけられたら、右クリック→「copy」→「copy XPath」でXPathを取得しましょう。
*IMPORTXML関数
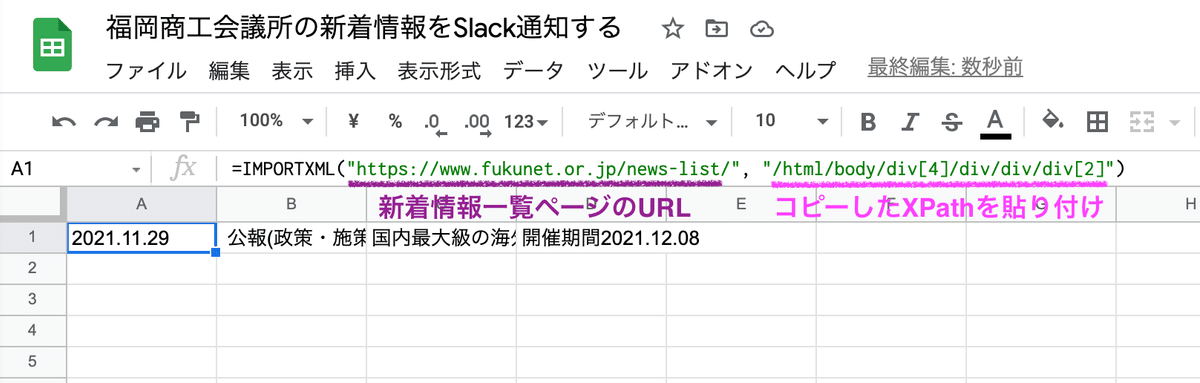
*手順7
A1セルに図のように式を入力します。それぞれ「”」で括るのを忘れないよう注意してください。
順調かと思いきや、このままでは1件しか新着情報を取得出来ませんでした。1日に二つ以上新着情報が掲載されることもあるので困ります😥
*手順8
色々試行錯誤した結果、今回は末尾の[2]を消すことでページ内の新着情報がすべて取得できたためこれで妥協しました。

ちなみに、二つ目・三つ目の新着情報のXPathはこうなっていました。
/html/body/div[4]/div/div/div[3]
/html/body/div[4]/div/div/div[4]
恐らく最後の括弧内の数字は新着情報というリストの中での何らかの番号や順番を意味していて、これを削除することでリスト全体の情報が得られたものと思われます。
*さいごに
IMPORTXML関数はスプレッドシートを開くたびに最新情報を自動で取得し直してくれます。本当はhtmlソースの仕組みをきちんと理解してXPathが取得できればもっと色々できるのですが、今回は最低限必要な情報が自動取得できるようになったので次のステップに進みたいと思います。
次はスプレッドシートの情報を元にGASを使ってSlackへ通知を飛ばしますが、長くなりますので別の記事で続きを書かせて頂きます。
もし良かったらご覧ください。それではまたお会いしましょう🐰