
時系列基盤モデルについての正しい解説
どこかのブログで時系列基盤モデルにprophetやLSTMを入れているのを見かけたので、正しい説明をしたいと思います。
時系列基盤モデルとは、膨大な時系列データを用いて事前学習されたAIモデルであり、特定のタスクに特化せずに幅広い時系列予測タスクを高精度で実行できる汎用的なモデルです。これらは、テキスト分野におけるGPTやBERTのような存在に相当します。
特徴
事前学習: 多様な時系列データセットを用いて事前学習されており、新しいタスクにゼロショットで対応可能。
汎用性: 特定のドメインやタスクに依存せず、さまざまな分野で利用可能。
効率性: 少ないデータでも高精度な予測が可能で、計算コストを抑える設計。
多用途性: 予測だけでなく、分類や異常検知など複数の時系列タスクに対応するモデルも存在。
背景
従来の時系列分析手法(ARIMAやLSTMなど)は、特定のデータセットごとに学習を行う必要がありましたが、基盤モデルは事前学習済みの知識を活用することで、大規模データセットや高い計算リソースが不要となります。これにより、金融、気象予測、製造業など、多岐にわたる分野での活用が期待されています[1][2][3][4][6][8].
Citations:
[1] https://freeasy24.research-plus.net/blog/c345
[2] https://qiita.com/ryosuke_ohori/items/826e760ad0df4a253fd3
[3] https://speakerdeck.com/rkaga/the-world-of-time-series-foundation-models
[4] https://zenn.dev/mkj/articles/cee69627a93e38
[5] https://ascii.jp/elem/000/004/218/4218920/
[6] https://qiita.com/taka_yayoi/items/af058615d955a2db7432
[7] https://blog.trocco.io/glossary/timeseries-data
[8] https://note.com/hatti8/n/n734aca9d4afb
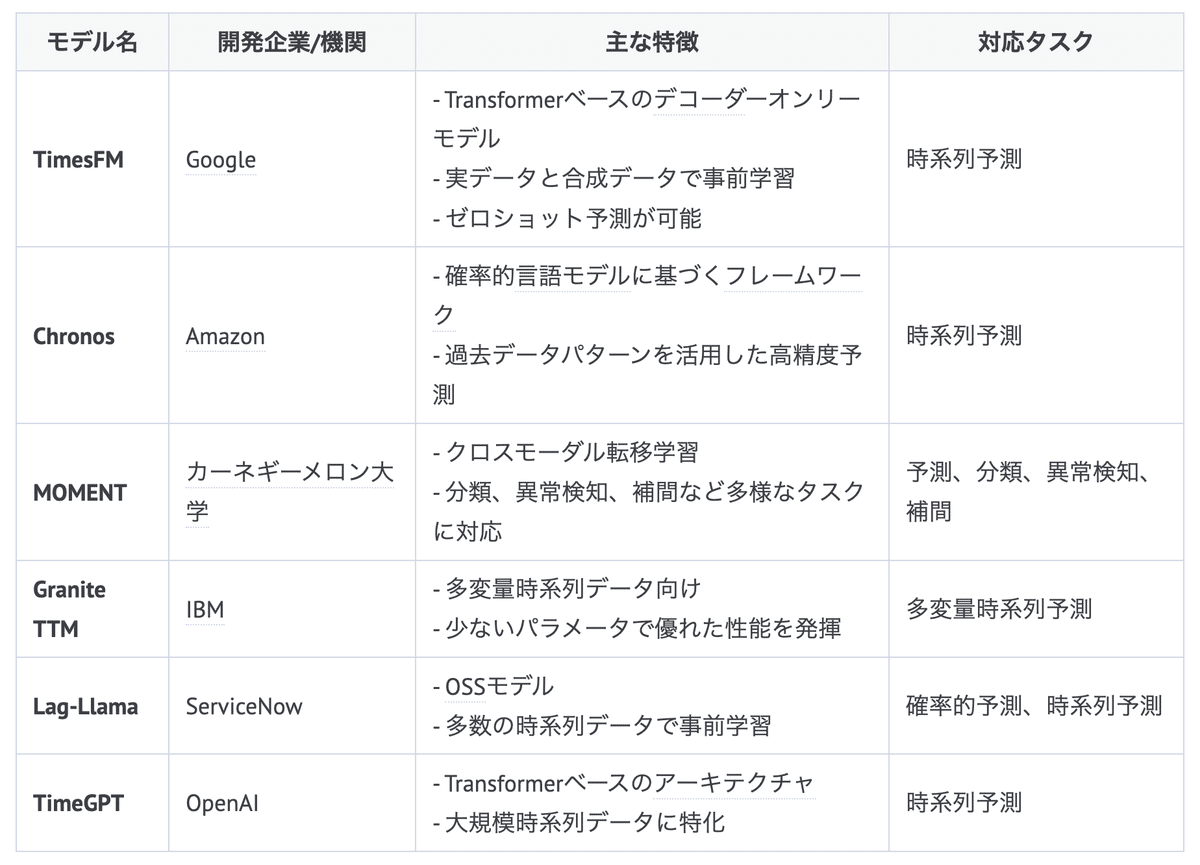
以下は、事前学習を活用した時系列基盤モデルの一覧とその特徴をまとめた表です。
特記事項
これらのモデルはすべて事前学習済みであり、多様なドメインやタスクに対応可能です。
特定のモデル(例: MOMENT)は、単なる予測にとどまらず、複数のタスク(分類、異常検知など)にも対応しています。
各モデルは、それぞれの設計思想や対象データ(単変量/多変量)によって適用範囲が異なります。
これらの基盤モデルは、従来のARIMAやLSTMといった特化型モデルとは異なり、高い汎用性と効率性を持つ点が特徴です[2][3][6][10]。
Citations:
[1] https://blog.since2020.jp/ai/時系列予測モデル一覧をまとめてみた/
[2] https://speakerdeck.com/rkaga/the-world-of-time-series-foundation-models
[3] https://qiita.com/ryosuke_ohori/items/826e760ad0df4a253fd3
[4] https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/jumpstart-foundation-models-latest.html
[5] https://zenn.dev/fmuuly/articles/e51f11c9adbd12
[6] https://zenn.dev/fmuuly/articles/0534a36d68a9f8
[7] https://ascii.jp/elem/000/004/218/4218920/
[8] https://developers.gmo.jp/technology/57341/
[9] https://www.skillupai.com/blog/tech/time-series/
[10] https://zenn.dev/mkj/articles/cee69627a93e38
時系列基盤モデルの具体的な利点は以下の通りです。
時系列基盤モデルの利点

具体例
Googleの「TimesFM」では、多様な時系列データで事前学習されており、ゼロショットで高精度な予測が可能[3][9]。
Amazonの「Chronos」は、確率的言語モデルを活用して短期的かつ高頻度な時系列予測を実現[3]。
これらの利点により、時系列基盤モデルは従来の統計モデルや特化型深層学習モデルと比べて、より効率的かつ汎用的に活用できる技術として注目されています。
Citations:
[1] https://www.skillupai.com/blog/tech/time-series/
[2] https://zenn.dev/seiichiro/articles/04dee1b1c7a30c
[3] https://speakerdeck.com/rkaga/the-world-of-time-series-foundation-models
[4] https://blog.trocco.io/glossary/timeseries-data
[5] https://qiita.com/taka_yayoi/items/af058615d955a2db7432
[6] https://zenn.dev/mkj/articles/cee69627a93e38
[7] https://zenn.dev/loglass/articles/3e596741a792b5
[8] https://tech.preferred.jp/ja/blog/timesfm/
[9] https://qiita.com/ryosuke_ohori/items/826e760ad0df4a253fd3
[10] https://jitera.com/ja/insights/42254
時系列基盤モデルには多くの利点がある一方で、以下のような欠点や限界も存在します。
時系列基盤モデルの欠点・限界

具体例
突発的な市場変動への対応不足: 自然災害や経済危機など、過去データに存在しないイベントは予測精度を著しく低下させる[1][2]。
解釈性の問題: 例えば、Google TimesFMなどのモデルは高精度だが、その結果をどのように得たかを説明することが難しい[4][7]。
リソース消費: 大規模な事前学習には高い計算コストがかかり、中小企業では導入ハードルになることも[3][7]。
これらの欠点を克服するためには、外部要因を取り入れる設計や解釈性向上技術の開発、大規模リソースを必要としない軽量モデルなど、新たなアプローチが求められています。
Citations:
[1] https://www.salesanalytics.co.jp/column/no00367/
[2] https://jitera.com/ja/insights/42254
[3] https://www.brainpad.co.jp/doors/contents/01_tech_2023-06-16-173025/
[4] https://zenn.dev/loglass/articles/3e596741a792b5
[5] https://www.medi-08-data-06.work/entry/time_serise_0309
[6] https://freeasy24.research-plus.net/blog/c345
[7] https://zenn.dev/mkj/articles/cee69627a93e38
[8] https://ai-market.jp/technology/data-analysis-time-series/
[9] https://zenn.dev/fmuuly/articles/0534a36d68a9f8
[10] https://qiita.com/taka_yayoi/items/af058615d955a2db7432