TensorFlow解説、過学習と学習不足について知る

過学習と学習不足について知る
https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
上記の記事を読んでつまづいたところのメモです。
results[i, word_indices] = 1.0って何だ?
def multi_hot_sequences(sequences, dimension):
# 形状が (len(sequences), dimension)ですべて0の行列を作る
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0 # 特定のインデックスに対してresults[i] を1に設定する
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)上記のコードは、ワードインデックスをマルチホットベクトルに変換しています。
train_data[0][1,14,22,16,43,530,973,1622,1385,......]こういう感じのデータを
train_data[0]array([0., 1., 1., ..., 0., 0., 0.])こういう感じに変換しています。
もう少し小規模な例で説明すると
[2, 3, 5]
を
[0, 1, 1, 0, 1, 0, 0, 0, ....]
に変換します。
(2つ目と3つ目と5つ目の位置に1がきて、それ以外の要素はすべて0が並ぶ)
np.zeros()の使い方
np.zeros((3, 5))array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])np.zeros((n, m))
と書くと
n行、m列のゼロ行列が生成される。
results = np.zeros((3, 5))
results[0, [0, 1, 4]] = 1.0
resultsarray([[1., 1., 0., 0., 1.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])np.zeros((3, 5))
でゼロ行列を生成して
results[0, [0, 1, 4]] = 1.0
みたいに書くと
0行目の0列目、0行目の1列目、0行目の4列目
の値をまとめて1に変更できる。
plt.plot(train_data[0])のグラフの正体
plt.plot(train_data[0])
plt.plot(train_data[0])
のグラフは上記の通り。
何だコレ?
plt.plot()って線グラフじゃなかったっけ?
train_data[0]array([0., 1., 1., ..., 0., 0., 0.])train_data[0]の中身は上記の通り。
len(train_data[0])10000train_data[0]の長さは1万。
train_data[0][:5]array([0., 1., 1., 0., 1.])train_data[0]の先頭5件だけ取り出してみると上記の通り。
plt.plot(train_data[0][:5])
先頭5件のデータだけをplt.plot()で描画した結果、ちゃんと折れ線グラフになってますね。
plt.plot(train_data[0])
改めて最初のplt.plot()グラフを確認。
x軸の0~5000あたりの範囲、青色で塗りつぶされているように見えるけど、実際には線グラフが下端の0と上端の1を行ったり来たりでギザギザしているはず。
ギザギザの密度が濃すぎて塗りつぶされたように見えているだけです。
後半の部分、垂直に縦線が並んでいるように見えているのも、実際には垂直ではありません。
横幅がものすごく短い山型が並んでいます。
クロスエントロピーって何だっけ?
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Epoch 1/20
49/49 - 2s - loss: 0.4494 - accuracy: 0.8093 - binary_crossentropy: 0.4494 - val_loss: 0.3094 - val_accuracy: 0.8819 - val_binary_crossentropy: 0.3094
Epoch 2/20
49/49 - 1s - loss: 0.2267 - accuracy: 0.9167 - binary_crossentropy: 0.2267 - val_loss: 0.2916 - val_accuracy: 0.8822 - val_binary_crossentropy: 0.2916
Epoch 3/20
49/49 - 1s - loss: 0.1705 - accuracy: 0.9403 - binary_crossentropy: 0.1705 - val_loss: 0.2969 - val_accuracy: 0.8815 - val_binary_crossentropy: 0.2969
Epoch 4/20
49/49 - 1s - loss: 0.1359 - accuracy: 0.9541 - binary_crossentropy: 0.1359 - val_loss: 0.3206 - val_accuracy: 0.8779 - val_binary_crossentropy: 0.3206
Epoch 5/20
49/49 - 1s - loss: 0.1129 - accuracy: 0.9633 - binary_crossentropy: 0.1129 - val_loss: 0.3578 - val_accuracy: 0.8703 - val_binary_crossentropy: 0.3578
Epoch 6/20
49/49 - 1s - loss: 0.0938 - accuracy: 0.9705 - binary_crossentropy: 0.0938 - val_loss: 0.3905 - val_accuracy: 0.8681 - val_binary_crossentropy: 0.3905
Epoch 7/20
49/49 - 1s - loss: 0.0789 - accuracy: 0.9758 - binary_crossentropy: 0.0789 - val_loss: 0.4363 - val_accuracy: 0.8626 - val_binary_crossentropy: 0.4363
Epoch 8/20
49/49 - 1s - loss: 0.0654 - accuracy: 0.9821 - binary_crossentropy: 0.0654 - val_loss: 0.4844 - val_accuracy: 0.8587 - val_binary_crossentropy: 0.4844
Epoch 9/20
49/49 - 1s - loss: 0.0536 - accuracy: 0.9870 - binary_crossentropy: 0.0536 - val_loss: 0.5219 - val_accuracy: 0.8570 - val_binary_crossentropy: 0.5219
Epoch 10/20
49/49 - 1s - loss: 0.0447 - accuracy: 0.9899 - binary_crossentropy: 0.0447 - val_loss: 0.5713 - val_accuracy: 0.8534 - val_binary_crossentropy: 0.5713
Epoch 11/20
49/49 - 1s - loss: 0.0372 - accuracy: 0.9920 - binary_crossentropy: 0.0372 - val_loss: 0.6200 - val_accuracy: 0.8527 - val_binary_crossentropy: 0.6200
Epoch 12/20
49/49 - 1s - loss: 0.0296 - accuracy: 0.9948 - binary_crossentropy: 0.0296 - val_loss: 0.6665 - val_accuracy: 0.8519 - val_binary_crossentropy: 0.6665
Epoch 13/20
49/49 - 1s - loss: 0.0240 - accuracy: 0.9965 - binary_crossentropy: 0.0240 - val_loss: 0.7126 - val_accuracy: 0.8503 - val_binary_crossentropy: 0.7126
Epoch 14/20
49/49 - 1s - loss: 0.0186 - accuracy: 0.9978 - binary_crossentropy: 0.0186 - val_loss: 0.7580 - val_accuracy: 0.8497 - val_binary_crossentropy: 0.7580
Epoch 15/20
49/49 - 1s - loss: 0.0147 - accuracy: 0.9988 - binary_crossentropy: 0.0147 - val_loss: 0.8026 - val_accuracy: 0.8486 - val_binary_crossentropy: 0.8026
Epoch 16/20
49/49 - 1s - loss: 0.0113 - accuracy: 0.9994 - binary_crossentropy: 0.0113 - val_loss: 0.8431 - val_accuracy: 0.8479 - val_binary_crossentropy: 0.8431
Epoch 17/20
49/49 - 1s - loss: 0.0089 - accuracy: 0.9996 - binary_crossentropy: 0.0089 - val_loss: 0.8794 - val_accuracy: 0.8476 - val_binary_crossentropy: 0.8794
Epoch 18/20
49/49 - 1s - loss: 0.0072 - accuracy: 0.9998 - binary_crossentropy: 0.0072 - val_loss: 0.9170 - val_accuracy: 0.8478 - val_binary_crossentropy: 0.9170
Epoch 19/20
49/49 - 1s - loss: 0.0058 - accuracy: 0.9998 - binary_crossentropy: 0.0058 - val_loss: 0.9502 - val_accuracy: 0.8470 - val_binary_crossentropy: 0.9502
Epoch 20/20
49/49 - 1s - loss: 0.0049 - accuracy: 0.9999 - binary_crossentropy: 0.0049 - val_loss: 0.9809 - val_accuracy: 0.8469 - val_binary_crossentropy: 0.9809Epoch 1/20
loss: 0.4494
accuracy: 0.8093
binary_crossentropy: 0.4494
Epoch 2/20
loss: 0.2267
accuracy: 0.9167
binary_crossentropy: 0.2267
Epoch 3/20
loss: 0.1705
accuracy: 0.9403
binary_crossentropy: 0.1705
lossとbinary_crossentropyが毎回同じ値になってますね。
これは、
baseline_model.compile()
で
loss='binary_crossentropy'
と指定したから。
このloss(バイナリークロスエントロピー)って何でしょう?
結論だけ書くと、
-log(P)
という数式です。
Pは正解ラベルの確率。
「過学習と学習不足について知る」
このTFチュートリアルでは、IMDBデータセットを使っています。
映画のレビューテキストに対して、ポジティブかネガティブかを推測するモデルを作成しています。
「This is good movie.」(これはいい映画)というテキストが入力として与えられ、この映画がポジティブである確率が0.9(ネガティブである確率が0.1)とモデルが推測したとします。
そして、正解のラベルはポジティブでした。
この場合
クロスエントロピーは
-log(P)=-log(0.9)=0.10536051565
となります。
-log(0.9)が0.10536051565ということは
log(0.9)は-0.10536051565です。
これをどうやって計算するかというと、
Googleの検索窓に
-ln(0.9)
と入力すると計算できます。

Google電卓の場合、
log(0.9)のように入力すると、底が10の常用対数、
ln(0.9)のように入力すると、底がeの自然対数が計算できます。
クロスエントロピーの-log(P)というのは、底がeの自然対数のことです。
(Google電卓でいうと-ln(P)の方です)
「対数って何だっけ?」という話はここでは割愛します。
loss(クロスエントロピー)の大まかな値
Pの値が0.1~1.0の範囲で0.1間隔で-log(P)の値を調べるとこんな感じ。
(ここでの-log(P)は底がeの自然対数の方です)
-log(1.0)=0
-log(0.9)=0.10536051565
-log(0.8)=0.22314355131
-log(0.7)=0.35667494393
-log(0.6)=0.51082562376
-log(0.5)=0.69314718056
-log(0.4)=0.91629073187
-log(0.3)=1.20397280433
-log(0.2)=1.60943791243
-log(0.1)=2.30258509299
正解ラベルがポジティブのときに
ポジティブな確率が1.0(100%)とモデルが推測した場合
P=1.0
-log(P) = -log(1.0) = 0
となります。
モデルの役目はこの損失関数-log(P)が0になるようにモデル内の重みを学習することです。
(Pが1.0になることを目指す)
そして、Pの値が下がっていくと(正解ラベルに対する推定確率が下がると)
-log(P)の値は増えていきます。(損失関数の値が増えていきます)
なぜ損失関数が
-log(P)
なのかというと、
「Pが1のとき(100%正解を当てられるときに)数字が0になり、
Pが0のときに(推定率が悪いときに)数字が大きくなる数式で
何か良いのないかなー」
と昔の偉い人が考えてたら
-log(P)
というのを思いつきました。
「-log(P)は微分可能なので勾配が求められる」というのもあるんですが、詳しい話は省略。
グラフの見方
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16, 10))
for name, history in histories:
val = plt.plot(history.epoch,
history.history['val_'+key],
'--',
label=name.title()+' Val'
)
plt.plot(history.epoch,
history.history[key],
color=val[0].get_color(),
label=name.title()+' Train'
)
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0, max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])
青の実線、0エポック(x軸が0)のところを見ると、Binary Crossentropyの値(y軸の値)は0.4494です。
Binary Crossentropyが0.4494ということは
-log(P) = 0.4494
ということです。
-log(1.0)=0
-log(0.9)=0.10536051565
-log(0.8)=0.22314355131
-log(0.7)=0.35667494393
-log(0.6)=0.51082562376
-log(0.5)=0.69314718056
-log(0.4)=0.91629073187
-log(0.3)=1.20397280433
-log(0.2)=1.60943791243
-log(0.1)=2.30258509299
0.4494は-log(0.7)と-log(0.6)の間ですね。
じゃあPの値が0.6~0.7の間、正解ラベルを正しく推測できる能力が60~70%って感じでしょうか?
Epoch 1/20
49/49 - 2s - loss: 0.4494 - accuracy: 0.8093 - binary_crossentropy: 0.4494 - val_loss: 0.3094 - val_accuracy: 0.8819 - val_binary_crossentropy: 0.3094model.fit()
したときの出力を改めて確認すると
loss: 0.4494 - accuracy: 0.8093
となっています。
実際には80.93%の割合で正解ラベルを予測できています。
accuracyが80%(P=0.8)ならば
lossの値(-log(P))は0.22314355131
にならないとおかしくない?
loss: 0.4494
というのは、トレーニングデータ1万5千件の平均値なので、個々のデータをみるとlossの値が0~∞の間でばらばらの値を取っているはず。
0側(正解ラベルを正しく推測できたとき)よりも∞側(正解ラベルを正しく推測できなかったとき)の方が影響力が大きいので、平均するとlossの値は∞側に引っ張られて大き目の数値になるみたいですね。
L1正則化って何?
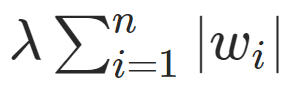
L1正則化では、「w(重み)の総和」をペナルティとして使う。
λはハイパーパラメータ。
正則化の影響力をどの程度活用するかをλに入れる数字の大小で調整する。
L2正則化って何?

L2正則化では、「w(重み)の2乗の総和」をペナルティとして使う。
先頭がλ/2となっているのは微分した時にλ/2があると計算しやすいから。
w^2を微分すると2wになるので、元の数式にλ/2が入っていると、微分後の数式がλwという簡単な式になって見やすいよねって話です。
λはハイパーパラメーターです。
λの値は後から自由に設定できるので、λ/2だろうと、λ/100だろうと、数式として余分な係数をつけてもOK。
L1正則化・L2正則化って何?
loss(損失関数)はバイナリークロスエントロピー、-log(P)です。
モデルは-log(P)が小さくになるように学習します。
正則化を使うと
(-log(P) + 正則化の数式)
が最小になるように学習します。
正則化項が小さくなるのはどういうときか?
それは、各wの値が小さくなるとき。
重みが大きいより、重みが小さいほうがモデルの性能が良くなります。
たとえば、
「This is a good movie.」
というレビューデータがあって
「ポジティブ」
に分類されているとします。
各単語の重みが
This: 0.1
is: 0.3
a: 0.1
good: 0.9
movie: 0.5
みたいになっていたとします。
goodの重みが大きいので、レビューの文章中にgoodという単語があるかどうかがポジティブかネガティブかの判定に大きな影響が出てきます。
また、各単語の重みが
This: 0.1
is: 0.3
a: 0.1
good: 9999999999.0
movie: 0.5
みたいになっていたとします。
goodの重みが極端に大きくなっています。
この場合、goodの有無だけでポジティブかネガティブかの判定が決まるようになってしまい、他の単語がほぼ意味をなさなくなります。
そうなると
「not と goodがペアで使われているときは『ネガティブ』」
みたいな意味をモデルには学習してほしいのに、notの有無には関係なく、goodの有無だけで結果が決まるような偏ったモデル(過学習)になってしまいます。
つまり、重みが大きいと性能が悪くなる傾向にあります。
L1正則化やL2正則化をつかうと
「損失関数が小さくて、なおかつ重み全体も小さい状態」
を目指してmodelの学習が進むので、過学習が発生しにくくなります。
L1正則化とL2正則化の2種類あるんですが、基本的にはL2正則化を使った方が性能が良くなります。
TensorFlowの正則化
l2_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(16,
kernel_regularizer=tf.keras.regularizers.l2(0.001),
activation='relu',
input_shape=(NUM_WORDS,)),
tf.keras.layers.Dense(16,
kernel_regularizer=tf.keras.regularizers.l2(0.001),
activation='relu'),
tf.keras.layers.Dense(1,
activation='sigmoid')
])tf.keras.layers.Dense()
のオプションに
kernel_regularizer=tf.keras.regularizers.l2(0.001)
のように書けばレイヤーにL2正則化の機能を追加できます。
0.001の部分はλの数値です。
tf.keras.layers.Dropout(0.5)って何?
dpt_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(16, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1, activation='sigmoid')
])tf.keras.layers.Dropout()
というのは、ノートの一部を無視するための設定です。
Dropout(0.5)だと50%を無視するってことです。
tf.keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
tf.keras.layers.Dropout(0.5),
とした場合は、
Denseレイヤーに16個のノードがあるうちの、ランダムに8個だけを選んで計算にしようされます。
あえて一部機能制限を付けて学習することで、過学習が抑えられます。