
pycaretを使ってみて思ったこと

pycaretって?
これまで機械学習っていうのは、データ解析&クリーン化を行った後、1つのモデルでハイパーパラメータを決め、学習、ハイパーパラメータを調整してまた学習、そして結果を比較。また別のモデルでハイパーパラメータを決め、(以下同じ)…でさらにモデル同士を比較するという果てしなき戦いをやってました。そこに現れたのがpycaretなるライブラリ。pycaretを使うとたった数行のコードでデータ解析から複数モデルの学習から比較までできる!という機械学習界の3分クッキングライブラリらしいのです。
公式チュートリアルを見る
こりゃすげぇ!ってことでgitに上がっているpycaretのチュートリアルを見たらかなり勉強になったし、簡単にモデル比較ができてちょっと感動しました。
↓こんなモデルごとの比較がすぐできた…すげー。
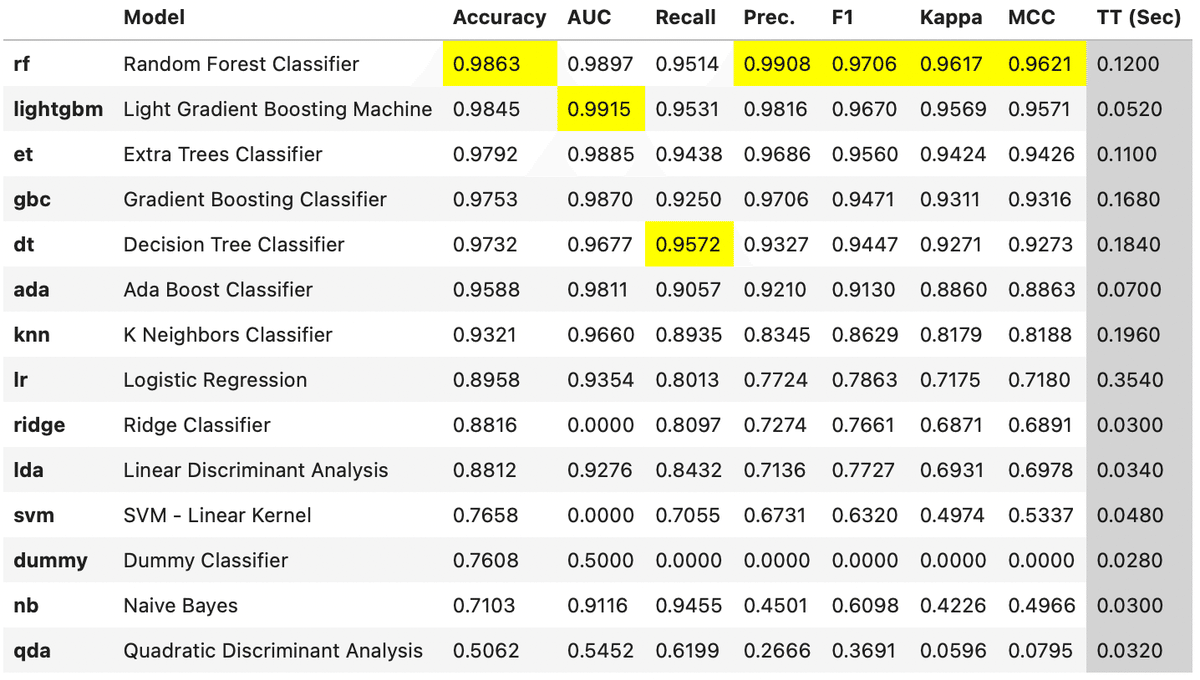
pycaretでできる解析
チュートリアルに掲載されている内容を全て試してみましたが、本当に簡単です。できたことはこんな感じ。
アノマリー分析:ちょっとおかしなデータを探す(不自然なクレジットカード利用を検出するなど)
クラス分類(バイナリ、多クラス):いわゆるクラス分けですが、ラベル付きのデータで学習することが多い。2つに分ける(Yes/No)がバイナリ、3つ以上の分けるのが多クラス。
クラスタリング:ラベル(正解)データがないデータで、データの特徴のみでクラス分けを行うのがクラスタリング。
文章解析:文章が好意的かどうかなんかでレビュー分析で使われます。サンプルは英文ですが、工夫すれば日本語でもできるかな。
回帰分析:いわゆる数値予測。築年数、土地の広さ、駅何分などの情報から住宅価格を予想するといったもの。
アソシエーション(関連)分析:特徴データ同士の関連性を分析する。ここに詳しい説明が…
pycaretではできない?こと
ディープラーニングを使った解析は今のところ無さそうです。pycaretの解析結果と、ディープラーニングの解析結果の比較も気になるところですが、これは別でやる必要があるみたい。
感想など
正直、未だ細かいことはよく分からないことが多い(学習すると精度が下がることが多い。何故?)ですが、pycaretのコンセプトはすぐ理解できるし、簡単に各モデルの結果を簡単に比較できることが分かりました。かなり短時間で様々なトライができるので面白いですねー。また、いろいろ試してここで公開しようと思います。
それにしても、pycaretで数行コードを書くだけでは、コンペに勝つようなことは不可能でしょうが、普通のビジネスだったら十分通用するんじゃなかろうか?っていう気がします。自社のデータをかき集めた後は、数行のコードを書くだけで分析、予測ができるなんてとんでもない時代ですね。