
ChatGPT勉強日記(#8) Pineconeの使用料が高いのでqdrantというベクターデータベースに乗り換えた(前編)

勉強日記第5回でIDEOのHuman Centered Design (人間中心設計)の資料をベクターデータにしてPineconeに保存した。第6回でそのベクターデータを知識と使って質問に答えるChagGPTを作った。
これで満足して、しばらく放置しておいたのだが、、月末にInvoiceが$22.25が届いた。むむむ!
ダッシュボードを開いてBillingのページに行くと、1日2.2ドルかかっていることがわかった。
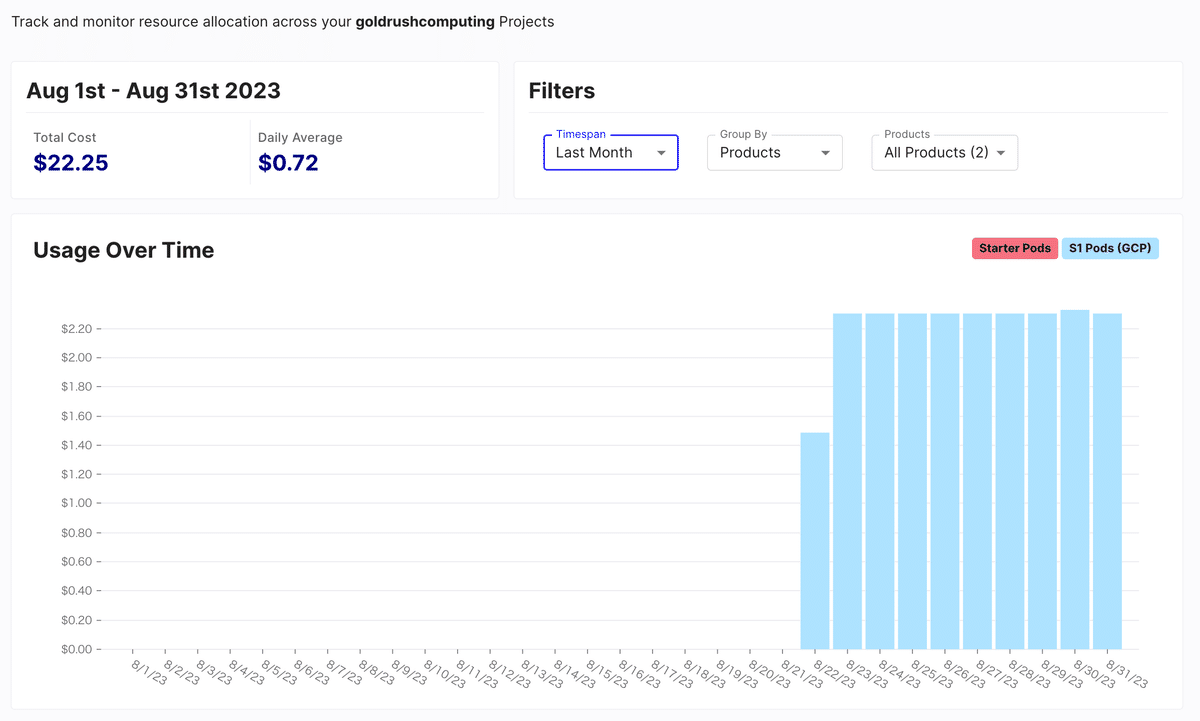
すっかり忘れていたがPineconeの有料プランは月70$~だったのだ。
データがそんなになくともきっちり月70ドルになるように日割りで課金されていく。
円安ということもあり、毎日300円が160個のベクターデータを保存しておくだけでかかっているのである。
これは趣味や試作で使うには高すぎる。。
そんな折に、ベトナムチームのバックエンドエンジニアのKからベクターデータベースならqdrantがいいなじゃないかという意見が届いた。
Kはインフラ、バックエンド全般に精通しているがAIをやっていたという話はきいたことがない、ただなぜかこのベクターデータベースをおすすめしてきたのである。
調べてみると、qdrantはpineconeのようにフルマネージドサービスとしても提供しているが、自分の環境にも構築できるようになっている。
フルマネージドサービスの恩恵に浴して楽をしていたので、若干腰が上がらなかったが、このまま行くと来月は70ドルの請求がくるということを思い浮かべ、思い腰をあげてqdrantを使ってみることにした。
qdrant Dockerコンテナの起動
qdrantはDockerイメージが公開されているので、それを持ってきて、
docker run -p 6333:6333 qdrant/qdrant:latestのように一発で走らせる事もできる。
僕はコマンドを忘れてしまうので、下のようなdocker-compose.ymlファイルを作った。
version: '3.7'
services:
qdrant:
image: qdrant/qdrant
container_name: "qdrant"
ports:
- 6333:6333
volumes:
- ./qdrant/storage:/qdrant/storagedocker compose upで簡単に起動できるし、qdrantのファイル(/qdrant/storage)をローカルマシンのディレクトリにバンドルすればDockerコンテナを誤って消去したとしてもデータがなくなることはない。もう一度コンテナを起動すれば同じデータを引き継ぐことができる。
(この後は↓の第5回の内容をもとに、今回qdrantへ乗り換えるために変更した箇所に絞って説明していきます。)
プロジェクトファイルの構成は第5回と全く同じ。まずconstants.pyの編集から始めた。
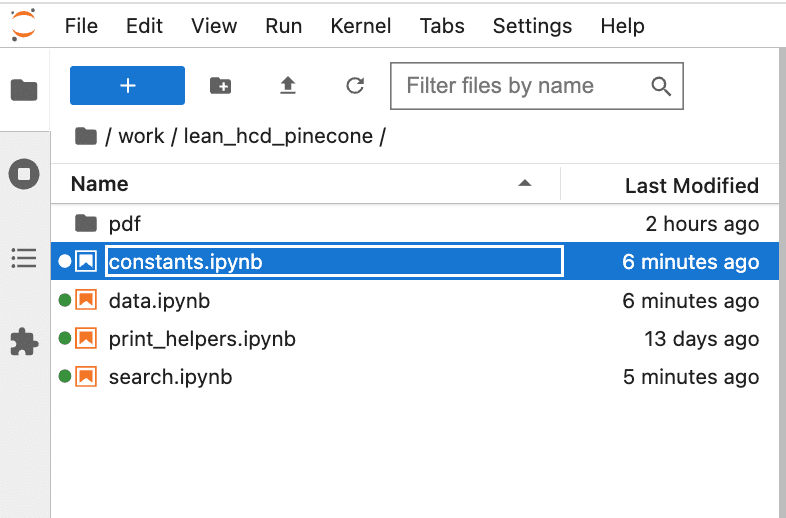
constants.ipynbを開いて下のように、PINECONEのリージョン、Index名、API_KEYなどを消して、qdrantの情報を環境変数として追加した。
%env OPENAI_API_KEY=<OpenAI APIのAPI_Key>
%env CHAT_MODEL_NAME=text-davinci-003
%env QDRANT_URL=http://172.17.0.1:6333
%env QDRANT_COLLECTION_NAME=hcd_embeddingsqdrantのURLとCollection名を指定するだけで良いのでPineconeよりもシンプルである。PineconeではベクターデータのテーブルのことをIndexと呼んでいるが、qdrantではCollectionと呼ぶようだ。
URLはDockerのデフォルトのブリッジネットワークのアドレスを指定する。
僕の環境ではJupyter Notebookも別のDockerコンテナの中で動いているので、Jupyter Notebookのコンテナの中からqdrantのコンテナのポート6333番にアクセスしないといけない。この場合、JupyterNotebookコンテナから見て、qdrantのコンテナのIPアドレスが172.17.0.1になるというわけだ。
他にコンテナが動いてない場合、たいてい172.17.0.1になるが、これは他に動いているコンテナなどの状況によって変わるので調べるのが少し面倒。
docker inspect <コンテナ名>で調べたり、後は、Jupyter Notebookのコンテナに
docker exec -it <Jupyter Notebookのコンテナ名> shで入って、
$ curl http://172.17.0.1:6333/statusなどのようにリクエストを投げて、qdrantのコンテナの方にアクセスログが来ているかをみて確認した。
172.17.0.1じゃない時は172.17.0.2とか172.17.0.3とかになっているときもある。
僕もこのDockerのルールに詳しくないが、IPアドレスではなく、
host.docker.internalという特別なDNSも使える。
例えばJupyter Notebookからこのようにリクエストをおくると、qdrantのほうでリクエストを受け付けたログが見えると思う。
curl http://host.docker.internal:6333/statusIPアドレスが見つからなかったら
%env QDRANT_URL=http://host.docker.internal:6333のように環境変数を設定しても良いだろう。
次にベクターデータをストアするためのNotebook、data.ipynbを編集していく。
data.ipynb
今回、qdrant-clientというモジュールが必要になるので下のように追加でインストールしておく。
%pip install qdrant-clientその後は、PDFのデータをチャンクに切り分けるsplit関数などはそのままで、
チャンクをEmbeddingsでベクターデータにし、Pineconeに保存していく処理の箇所を書き換えていく。まず、したのように、pineconeとLangChainのPineconeクラス、OpenAIEmbeddingsクラスをインポートしているところを、
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone↓のように、QdrantClient, Qdrantをimportするように書き換えた。
from qdrant_client import QdrantClient
from langchain.vectorstores import Qdrant
from qdrant_client.http import models
from langchain.embeddings.openai import OpenAIEmbeddings
つぎに、OpenAIEmbeddingsのインスタンスを作成し、pineconeを初期化すしているところ↓のpineconeの初期化を消して、
# Initialize OpenAI Embedding
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['OPENAI_API_KEY'])
# Initialize Pinecone
pinecone.init(api_key=os.environ['PINECONE_API_KEY'], environment=os.environ['PINECONE_INDEX_REGION'])したのようにQdrantClientオブジェクトを初期化するコードに書き換える。
# Initialize OpenAI Embedding
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['OPENAI_API_KEY'])
client = QdrantClient(url=os.environ['QDRANT_URL'])
vectors_config = models.VectorParams(size=1536, distance=models.Distance.COSINE)
client.recreate_collection(
collection_name=os.environ['QDRANT_COLLECTION_NAME'],
vectors_config=vectors_config,
)pineconeは予めWebサイト上でIndexを作成したが、qdrantはまだCollectionを作ってないので、recreate_collection関数をつかってCollectionを作成する.
SaveVectorToPinecone関数(↓)を書き換えて、
def SaveVectorToPinecone(texts, filename):
Pinecone.from_texts(texts, embeddings, metadatas=[{'chunk': index, 'file': filename} for index, _ in enumerate(texts)], index_name=os.environ['PINECONE_INDEX_NAME'])SaveVectorQdrant関数を作成した。
def SaveVectorToQdrant(texts, filename):
Qdrant.from_texts(texts, embeddings, metadatas=[{'chunk': index, 'file': filename} for index, _ in enumerate(texts)], collection_name=os.environ['QDRANT_COLLECTION_NAME'],
2つの関数を見比べてみると、from_texts関数のパラメーターが
index_name
から
collection_name
に変わっているだけなのがわかる。
LangChainの統一的なインタフェースのお陰で、こんなに簡単にベクターデータベースを切り替えられてしまうのである。
これで、あとはpdfフォルダの下のファイルを1つずつ読み込んで、テキストデータを取り出し、それを、SaveVectorToPinecone関数に渡していたところの関数名をSaveVectorToPineconeからSaveVectorToQdrantへ変えるだけでおわりである。
import PyPDF2
import os
pdf_dir = 'pdf'
# Iterate over every file in the pdf directory
for filename in os.listdir(pdf_dir):
if filename.endswith('.pdf'):
# Open the PDF file
with open(os.path.join(pdf_dir, filename), 'rb') as file:
# Initialize PDF reader
pdf_reader = PyPDF2.PdfReader(file)
# Extract text from every page
content = ''
number_of_pages = len(pdf_reader.pages)
for page_num in range(number_of_pages):
content += pdf_reader.pages[page_num].extract_text()
SaveVectorToQdrant(split(content), filename) データの確認
qdrantにはダッシュボードが着いており、ブラウザでホストアドレス + /dashboardで中を見ることができる。
http://localhost:6333/dashboardのようにブラウザのアドレスバーに入力すると、下のように現在qdrantにあるCollectionの一覧が表示される。
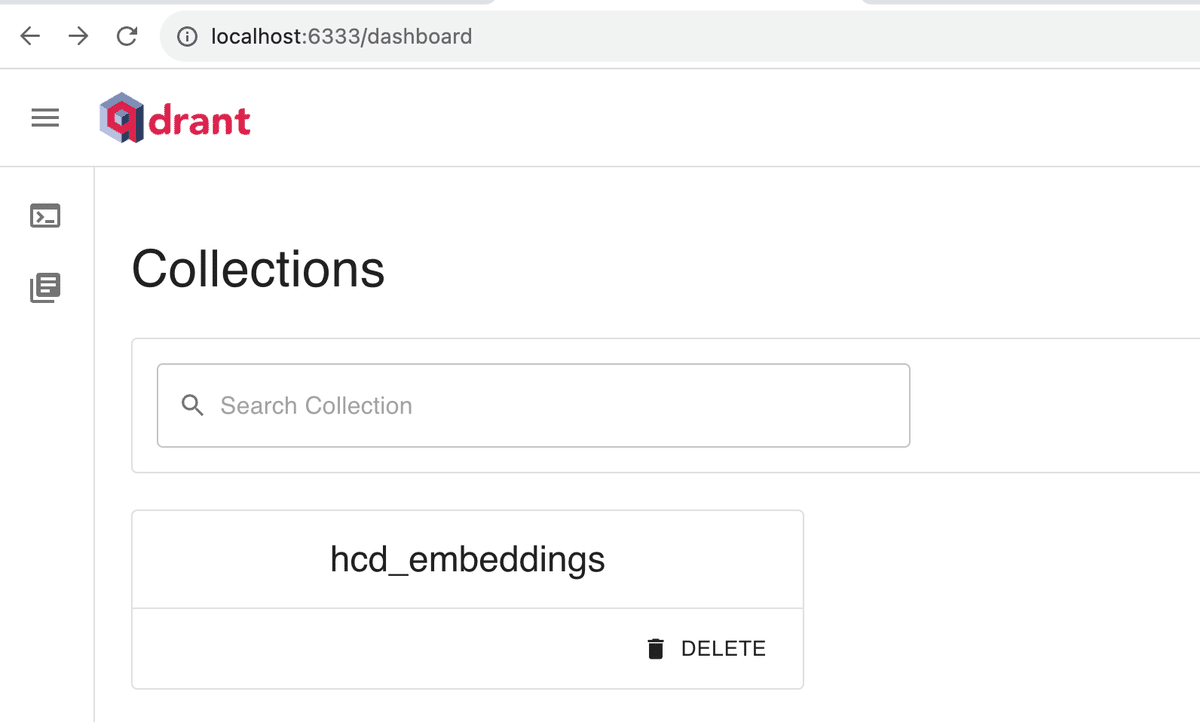
今回作ったhcd_embeddingsというCollectionを選択すると、コレクションの中にあるかくデータが閲覧できる。
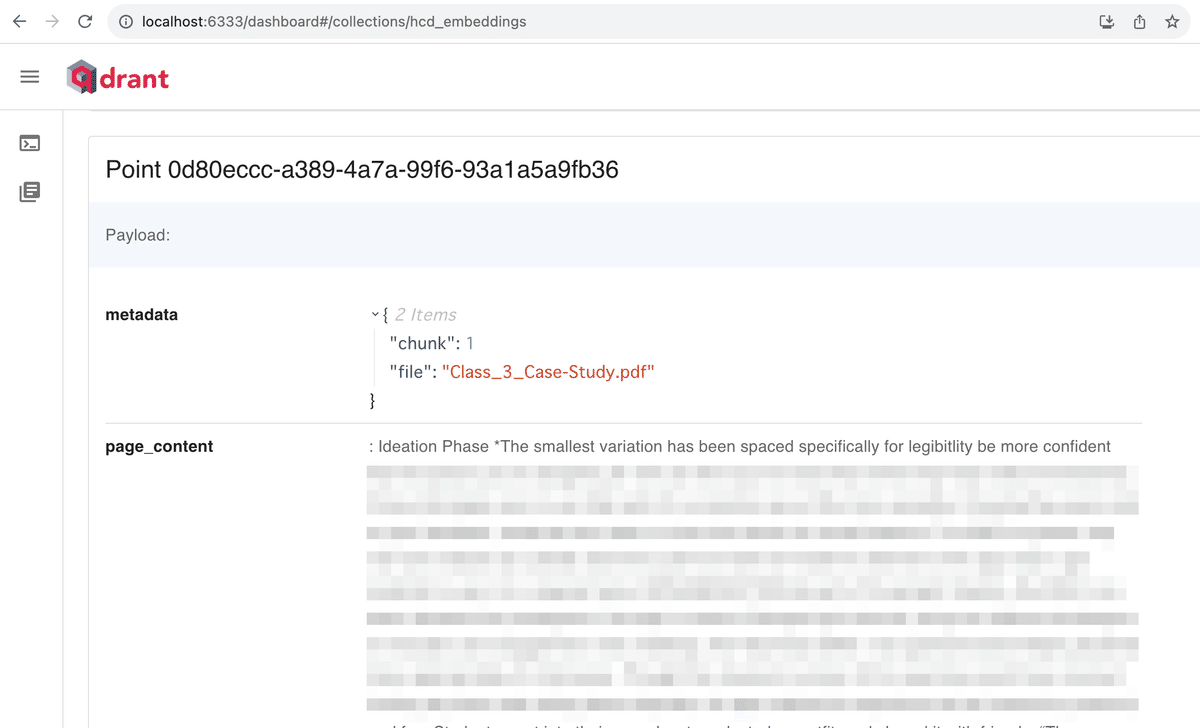
LangChainを介してqdrantに保存しているので、どうやっているのかは確認していないがどうやらLagChainがベクター化される前の元データもpage_contentという名前でqdrantに保存しているようである。
metadataで指定した以外にも上のスクリーンショットのようにpage_contentというカラムに元データが入っているのがわかる。
これはベクターデータを検索したついでに元データも参照できるのですごく便利だなと思った。Pineconeだと、metadataに元データのIDなどを入れておき、SQLデータベースなどに元データを探しに行かないといけないと思っていたので、page_contentがあるqdrantはそれだけでも使う理由になると思った。
このようにqdrantに切り替えてみて思った感想は、試作や勉強のためであればqdrantのほうが圧倒的にコスパよしだし、Pineconeと比べて実装のしにくさもなく、むしろより使いやすいくらいだった。
次回は今回作成したqdrantのCollectionに対してベクターデータの検索を行い、ベクターデータの知識を生かした回答を生成するChatGPTを作って見ようと思う。
続く。
このブログに関する質問や、弊社(Goldrush Computing)への開発案件の依頼は↓↓↓からお願いします。弊社では現在、OpenAI APIを使った高度なドキュメントや文字列情報を扱ったシステムの開発に注力しております。
mizutori@goldrushcomputing.com
次回は↓↓↓