
Chat GPT勉強日記 #3. Embeddingsを使ってみる

前回↓↓↓、OpenAI APIの公式ドキュメントを読んで勉強するなかで一番気になったEmbeddingsを今回は使ってみたいと思う。
Embeddingsを、あくまで私個人の感想的に説明すると
Open AIのモデルが単語やフレーズ、文章をどうやって理解、表現しているのかを垣間見れるもの
である。
まずは、下の公式ドキュメントから、Open AI APIのEmbeddingsのAPIのEndpointを取得した。
POSTメソッドの、以下のエンドポイントがEmbeddingsの機能を使うためのAPIである。
https://api.openai.com/v1/embeddingsこのAPIを手軽に使って見るためにPostmanを使った。
Postmanを立ち上げ、POSTリクエストを作って、URLに上のURLを入力する。

このままの状態でSendボタンを押してみると
いつものことながら、下のように怒られた。。
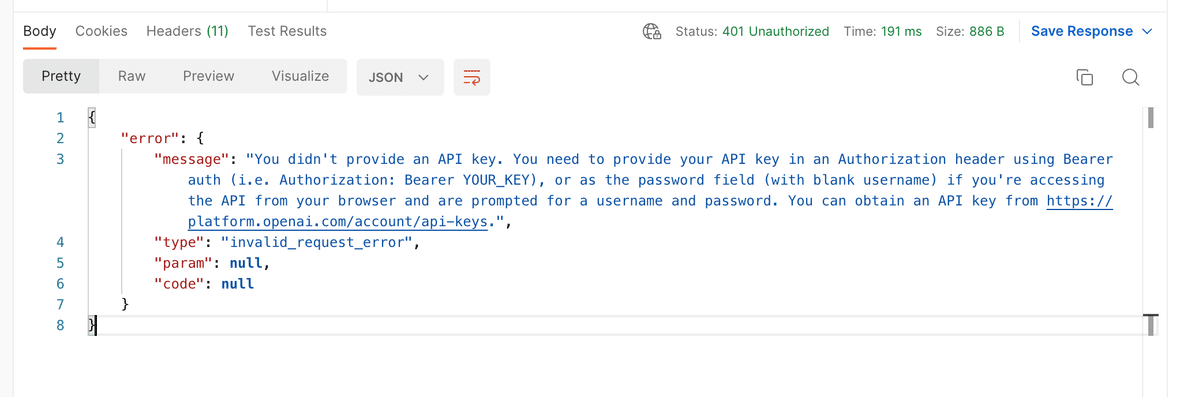
このエラーメッセージにかかれている↓のURLを開くと、
https://platform.openai.com/account/api-keys
OpenAI APIを使うためのSecret keyを作ることができる。(OpenAI API使用のための有料プランに加入する必要があります)
このシークレットキーをAuthorizationヘッダにつけて送る。
Postmanに戻り、
Authorizationタブで、Bearer Tokenを選択

Bearer Tokenを選択後、右側のTokenというプレースホルダーが入っている入力箇所に先程のSecret Keyを入れる。

ここで一回Sendを押すと、下のように、モデルを指定してください、お叱りが返ってきた。Postするデータを何も指定していないので当然であるがこれで認証が通ったことがわかる。

もう一度Embeddings APIのドキュメント↓にもどると、
model、input、userという3つのパラメータを遅れることがかいてある。
modelはこの中のどれかを使うと書かれているが、、
https://platform.openai.com/docs/models/overview
今回は↓にかかれているtext-embedding-ada-002というモデルを使うことにした。
https://platform.openai.com/docs/models/embeddings
Postmanで、Bodyタブを選択し、送信データの形式にrawをチェック、そして右端のドロップダウンからJSONを選択する

ここに、modelと、inputを指定する。inputには、Embeddingsの機能を使ってベクター数値化してほしい単語、プレーズ、文章などを指定する。
つまり、Open AIのモデルがどうやって理解、表現しているのかを垣間見たい言葉をここに指定する。
今回は「ラクダ」をinputに指定してみた。
{
"model": "text-embedding-ada-002",
"input": "ラクダ"
}これで、Sendボタンを押してリクエストをOpenAI APIに送ると、下のような結果が返ってきた

返ってきたJSONデータの中のdataの中のembeddingの中身が配列になっており、たくさんの数値が入っているのがわかる。
この配列は、1536行あるので、「ラクダ」という言葉が1536次元のベクターデータにOpen AIのモデルによって変換されたことになる。
この1536次元のベクターデータがOpen AIがラクダを理解・表現する時に使う数値ということになる。
このように、Embeddingsを使って僕はOpenAIのモデルがラクダをどう理解・表現しているかを垣間見たのであった。
次にありがたく頂戴したこのベクターデータをベクターデータベースに保存していく。
ベクターデータベース
ベクターデータベースについては、どれがいいのか、各サービスにどういう違いがあるのか、まだ良くわかっていないが今回はSingleStoreDBというのを使ってみることにした。
Free Trialのアカウントを作って、進んでいくとまず、Workspace Groupというものを作って、CloudプラットフォームをAWS, GCP, Azureのなかから選ぶ

残念ながらRegionはTokyoがリストになかったので、Singaporeを選択した。
次にWorkspaceの設定を行った。

Workspaceの名前を設定して、データベースのSizeを選ぶ。今回は一番スペックの低いものを選択した。データベースインスタンスの作成・起動に少し時間がかかるが、終わると下の様になった。

右側のCreate Databaseボタンをクリックし、今回はanimalというデータベースを作った。


このanimalデータベースを選択すると、まだ、下のようにテーブルが何もはいってないことがわかる。

左のメニューのDEVELOPの下にあるSQL Editorを選択して、

下のようにテーブルを作ることにした。
CREATE TABLE IF NOT EXISTS Animal (
id SERIAL PRIMARY KEY,
name TEXT,
vector BLOB
);nameは動物の名前、vectorは先程embeddings APIから返ってきたベクターデータを格納するカラムである。
下のようにワークスペースとデータベースに先程作ったものが選択してから、クエリを入力する。

そして、画面右上のRunボタンを押すと、

下のようにAnimalテーブルが作成された。

このテーブルにSQLエディターを使って、ラクダをベクターデータを名前と一緒に保存した。
INSERT INTO Animal(name, vector) VALUES ("ラクダ", JSON_ARRAY_PACK("[
-0.015508087,
0.0026380979,
...
-0.001926449,
0.0010192259
]"))
同じ手順で、チンパンジー、チーター、キリンのベクターデータも保存した。

ベクターデータベースの検索
これで、動物のベクターデータベースができたので、このベクターデータベースを使って、データベースにない生き物について、このベクターデータベースを使って類似度を調べて見たいと思った。
Open AI APIの/embeddings APIを使って「オカピ」のベクターデータを取得する。
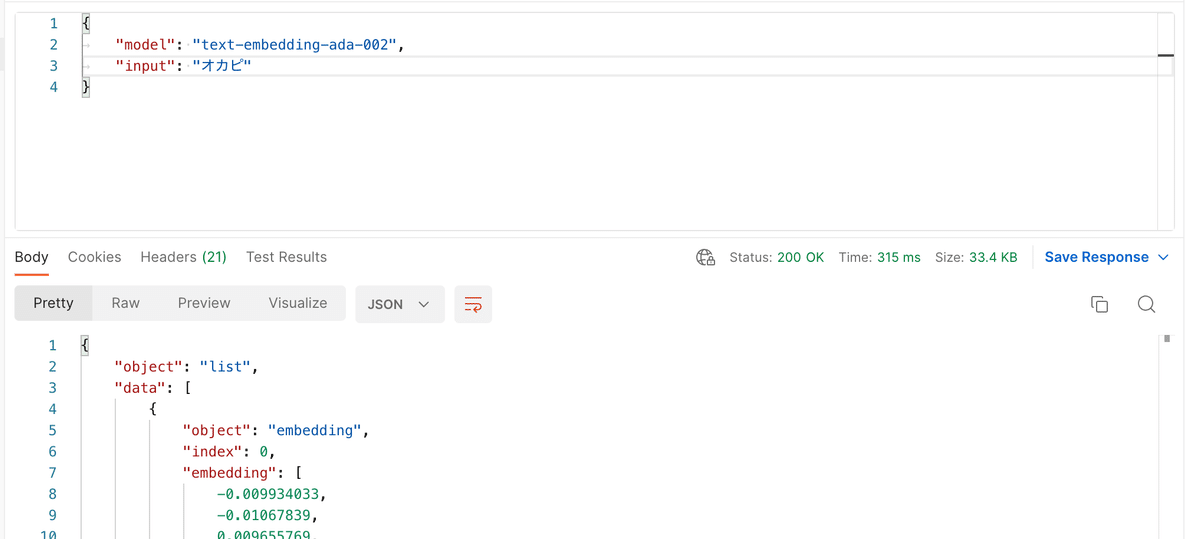
このオカピのデータベースで下のようにデータベースを検索し、ベクターデータのドット積が大きいものから並べる
SELECT name, dot_product(vector, JSON_ARRAY_PACK("[
-0.009934033,
-0.01067839,
...
-0.0027617724,
-0.013189725
]")) AS similarity FROM Animal ORDER BY similarity DESC
このクエリをSQL Editorで実行すると、下のような順番になって結果が返ってきた。similarityが類似度である。

確かに、合ってる気がする!
一番オカピに体格が近そうなキリンが1位に、顔が若干似ているラクダが2番目にランキングしている。
チーターよりチンパンジーのほうが上なのは何故かはわからないが、OpenAIのモデルはそう思っているようである。チーターは肉食動物だから一番離れているのかもしれない。
このようにEmbeddingsとベクターデータベースを使うと、単語や文章をベクター化して、分類して検索するということが簡単にできることがわかった。
続く。
このブログに関する質問やWeb・Android・iOSアプリの開発の相談はこちらからお願いします。↓↓↓
@mizutory
mizutori@goldrushcomputing.com
次回は↓↓↓
この記事が気に入ったらサポートをしてみませんか?