
ZERO-SHOT-DETECTIONをDeticで実装!物体検出学習コストの大幅削減も可能に

初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
転職回数:1回(建設(2年9か月)→IT系年収100万up(現職3か月))
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はzero-shot-detectionを用いた物体検出手法の一つであるdeticとclipについて解説しようと思います。
ZERO-SHOT-DETECTIONとは
学習時には存在しないクラスの分類を行う技術
zero-shot-detectionは以下の記事ではこのように解説されています。
そのために必要となるのが、画像を「犬」と分類する場合の犬という単語ベクトルに変換すること。
ZERO-SHOT-DETECTIONのメリット
こうすることで、「あ、この画像はこんな特徴量ベクトルが出てきなたぁ。。。」
その結果、「そうすると、、、犬っていう名前になるのね!」
みたいな感じで画像から単語を検索することが可能になります。
つまり今まで、画像をラベル付けしながら一つ一つ行っていた作業が不必要になるわけです。
ZERO-SHOT-DETECTIONが可能なdeticとは
Deticとは2022年にMetaが論文発表したアノテーションフリーの物体検出技術となります。
Deticは画像分類データセットを使った物体検出器のトレーニングを可能とし物体検出の検出分類数(Vocabulary)を大幅に拡張しました。
このことでDeticは物体検出の学習時にアノテーションさせた画像を入力する必要なく、実装が簡単になります。
またデータセットの確保も容易になります。
Deticの特徴
画像データセットで物体検出のトレーニングが可能になったことにより大量のデータセットより学習を行ってます。
https://github.com/facebookresearch/Detic/blob/main/docs/MODEL_ZOO.md
一例として
「Detic_C2_SwinB_896_4x_IN-21K+COCO_lvis.onnx」モデルでは
backbone:SwinB(Swin-Transformer)とCenterNet2のDetector,Federated Loss, large-scale jitttering
データセット:ImageNet21k、COCOデータセット
識別可能リスト:COCO,LVIS
「Detic_C2_SwinB_896_4x_IN-21K+COCO_in21k.onnx」モデルでは
backbone:SwinB(Swin-Transformer)とCenterNet2のDetector,Federated Loss, large-scale jitttering
データセット:ImageNet21k、COCOデータセット
識別可能リスト:COCO,Imagenet21k
これらのクラスを分類可能となってます。
さらに「Detic_C2_R50_640_4x_lvis.onnx」のモデルでは
backbone:ResNet50
データセット:lvis
識別可能リスト:lvis
さらに「Detic_C2_R50_640_4x_in21k.onnx」のモデルでは
backbone:ResNet50
データセット:ImageNet21k
識別可能リスト:ImageNet21k
Deticの実装
それでは今回はGoogle ColoboratoryでDeticを実装します。
ドライブのマウント
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/ColabNotebooks/detic_object_detectiontorchiのインストール
!pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118detectron2のインストール
!python3 -m pip install 'git+https://github.com/facebookresearch/detectron2.git'公式よりクローン
!git clone https://github.com/facebookresearch/Detic.git --recurse-submodules
%cd Detic
!pip install -r requirements.txt実際にテスト
必要なライブラリをimport
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
import sys
import numpy as np
import os, json, cv2, random
from google.colab.patches import cv2_imshow
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
# sys.path.insert(0, 'third_party/CenterNet2/projects/CenterNet2/')
sys.path.insert(0, 'third_party/CenterNet2/')
from centernet.config import add_centernet_config
from detic.config import add_detic_config
from detic.modeling.utils import reset_cls_test
学習モデルをロード
cfg = get_cfg()
add_centernet_config(cfg)
add_detic_config(cfg)
cfg.merge_from_file("configs/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.yaml")
cfg.MODEL.WEIGHTS = 'https://dl.fbaipublicfiles.com/detic/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.pth'
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
cfg.MODEL.ROI_BOX_HEAD.ZEROSHOT_WEIGHT_PATH = 'rand'
cfg.MODEL.ROI_HEADS.ONE_CLASS_PER_PROPOSAL = True # For better visualization purpose. Set to False for all classes.
predictor = DefaultPredictor(cfg)vocabularyをロードし、検出できる対象を全て検出
BUILDIN_CLASSIFIER = {
'lvis': 'datasets/metadata/lvis_v1_clip_a+cname.npy',
'objects365': 'datasets/metadata/o365_clip_a+cnamefix.npy',
'openimages': 'datasets/metadata/oid_clip_a+cname.npy',
'coco': 'datasets/metadata/coco_clip_a+cname.npy',
}
BUILDIN_METADATA_PATH = {
'lvis': 'lvis_v1_val',
'objects365': 'objects365_v2_val',
'openimages': 'oid_val_expanded',
'coco': 'coco_2017_val',
}
vocabulary = 'lvis' # change to 'lvis', 'objects365', 'openimages', or 'coco'
metadata = MetadataCatalog.get(BUILDIN_METADATA_PATH[vocabulary])
classifier = BUILDIN_CLASSIFIER[vocabulary]
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)
テスト画像の準備
!wget https://web.eecs.umich.edu/~fouhey/fun/desk/desk.jpg
im = cv2.imread("./desk.jpg")画像のテスト
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])LVISは物体検出用のデータセットです。1000+のクラスラベルを持ち、12万枚の画像を含みます。
それを元にクラスを分類してみます。

検出対象を指定
今まではIVISに対象のクラスは全て抽出していましたが、それを絞ってみようと思います。
今回は
'headphone', 'webcam', 'paper', 'coffee'
この四つで絞ります。
必要な工程はvocabularyはカスタムで、metadata.thing_classesnの箇所を指定の値に変更すること。
from detic.modeling.text.text_encoder import build_text_encoder
def get_clip_embeddings(vocabulary, prompt='a '):
text_encoder = build_text_encoder(pretrain=True)
text_encoder.eval()
texts = [prompt + x for x in vocabulary]
emb = text_encoder(texts).detach().permute(1, 0).contiguous().cpu()
return emb
#title 検出対象の入力
#markdown 検出対象の名称を英語で入力してください。ここで自然言語による処理を可能にする
vocabulary = 'custom'
metadata = MetadataCatalog.get("__unused")
metadata.thing_classes = ['headphone', 'webcam', 'paper', 'coffee'] # Change here to try your own vocabularies!
classifier = get_clip_embeddings(metadata.thing_classes)
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)
output_score_threshold = 0.3
for cascade_stages in range(len(predictor.model.roi_heads.box_predictor)):
predictor.model.roi_heads.box_predictor[cascade_stages].test_score_thresh = output_score_threshold結果は対象のモノのみを抽出することができてます。

結果の出力
最後は結果の出力です。gyousuuって書いて見づらくなってるのはすいません。。。
import pandas as pd
result = []
[result.extend((x,
outputs["instances"][x].pred_classes.item(),
[metadata.thing_classes[x] for x in outputs["instances"][x].pred_classes][0],
outputs["instances"][x].scores.item(),
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][0],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][1],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][2],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][3])
for x in range(len(outputs["instances"])))]
df = pd.DataFrame(result, columns = ['gyousuu','class-id','class','score','x-min','y-min','x-max','y-max'])
df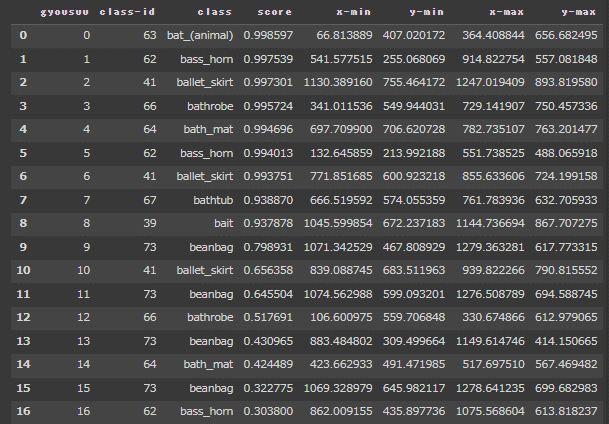
こちらの結果を使えばアノテーションを行わずに、一度deticの物体検出をかませて、結果を出力。
その後その値を使用してyolo等の高精度の物体検出モデルに適用することもできるのではないかと思います。
最後に
今回は画像分類データセットを用いた物体検出手法のdeticを開設して実装してみました。
正直yolo等の物体検出モデルのみを扱って、ラベル付けしていた身としては素晴らしいの一言。。。
今後ラベル付けをする時間すらも自動化されていく未来が見えますね。